回顾上篇文章:
RDD:
是什么
五大特性对应五大方法
创建方式:3
操作:2 action & transformation
Spark作业开发流程: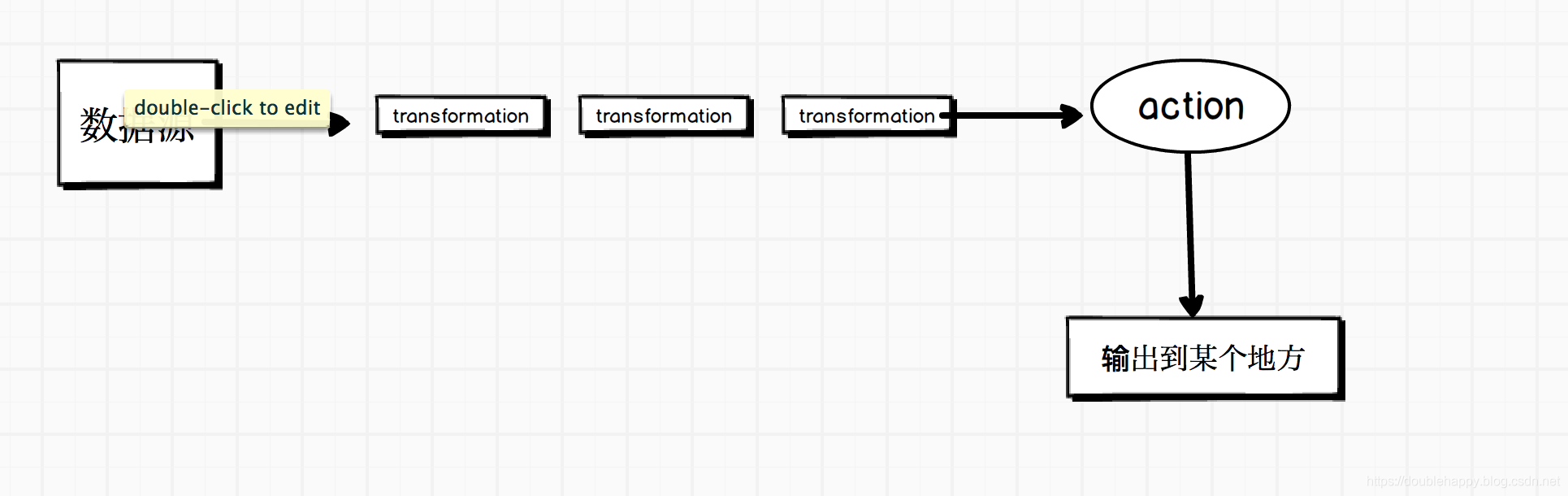
也就是:
数据源–>经过一堆transformtion–>action 触发spark作业 —>输出到某个地方
你的业务无论多么复杂 都是这样的。
Action
(1)collect
1 | /** |
1 | scala> val rdd = sc.parallelize(List(1,2,3,4,5)) |
(2)foreach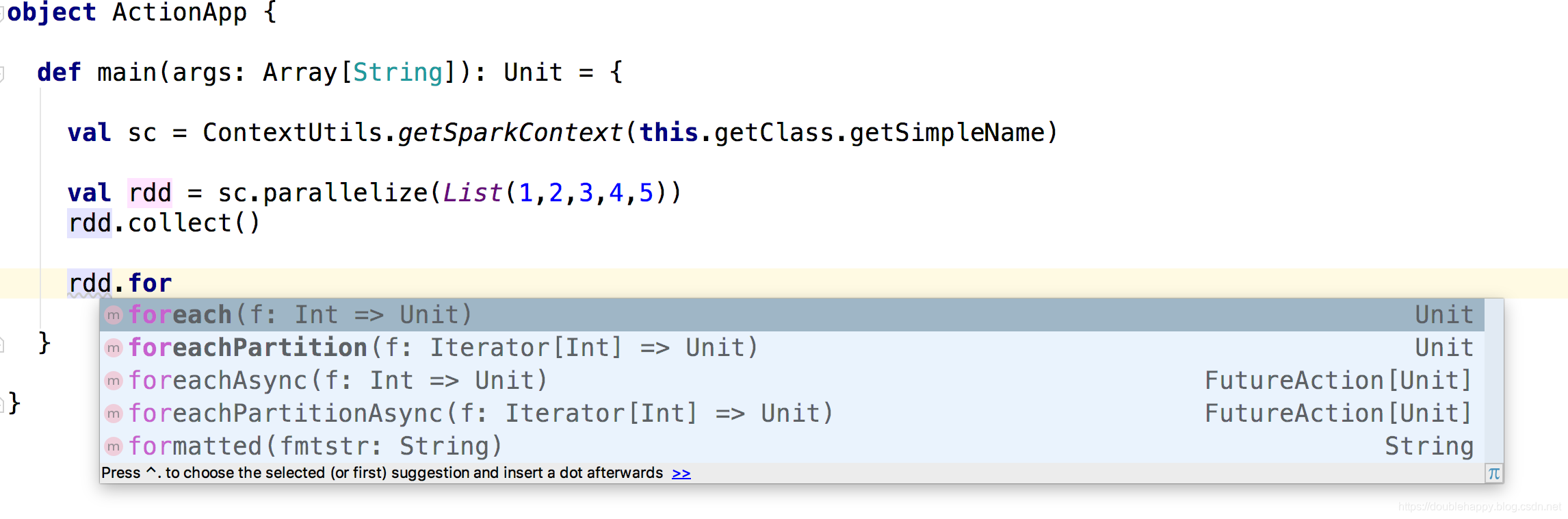
1 | /** |
1 | scala> val rdd = sc.parallelize(List(1,2,3,4,5)) |
注意:
我在spark-shell –master local[2] 模式下 rdd.foreach(println) 会显示出结果,如果在
spark-shell –master yarn 模式下 rdd.foreach(println) 会显示出结果么?为什么呢?
(3)foreachPartition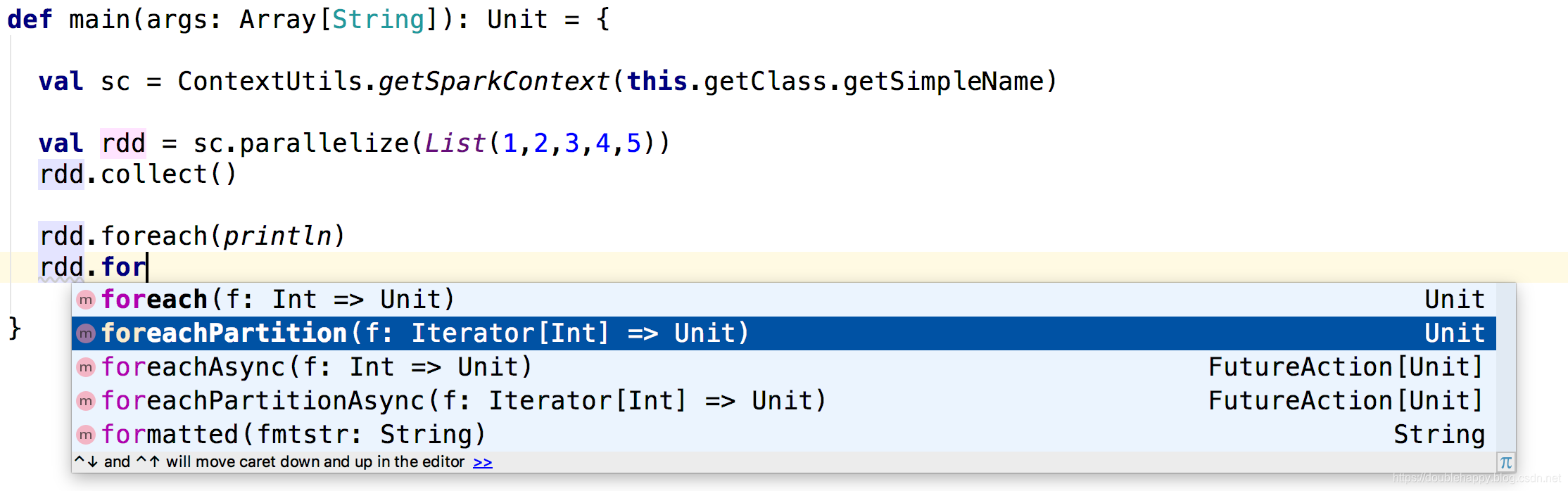
1 | /** |
1 | scala> val rdd = sc.parallelize(List(1,2,3,4,5)) |
1 | scala> val rdd = sc.parallelize(List(1,2,3,4,5)) |
能不能想到这是什么问题导致的?
foreachPartition(paritition => paritition.map(println)) 输出结果在正在执行的机器上面是有的
而控制台看到的是driver的
正好引入一个东西:
sortBy 上次的
1 | val rdd2 = sc.parallelize(List(("a",1),("b",2),("c",3),("d",4)),2) |
结果:
1 | scala> val rdd2 = sc.parallelize(List(("a",1),("b",2),("c",3),("d",4)),2) |
sortBy是全局排序的还是分区排序的?通过上面的测试知道了吗? 知道个鬼
是不是感觉是分区排序
去idea上输出结果看一下:
1 | package com.ruozedata.spark.spark02 |
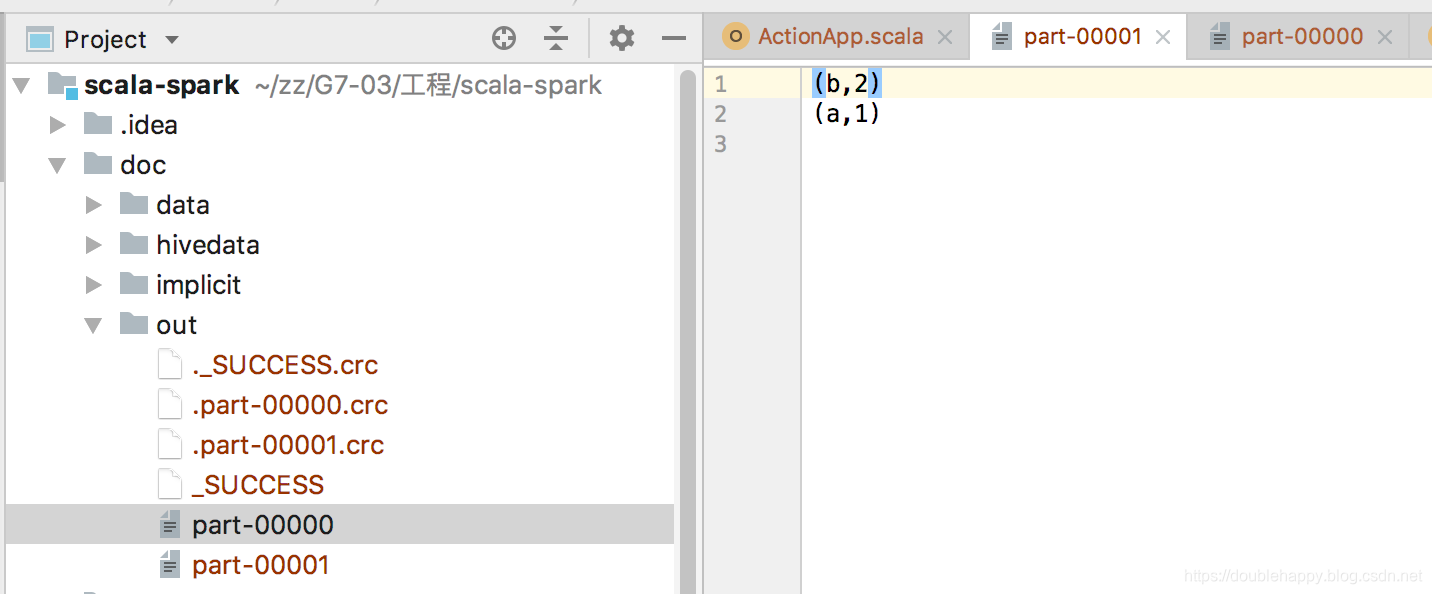
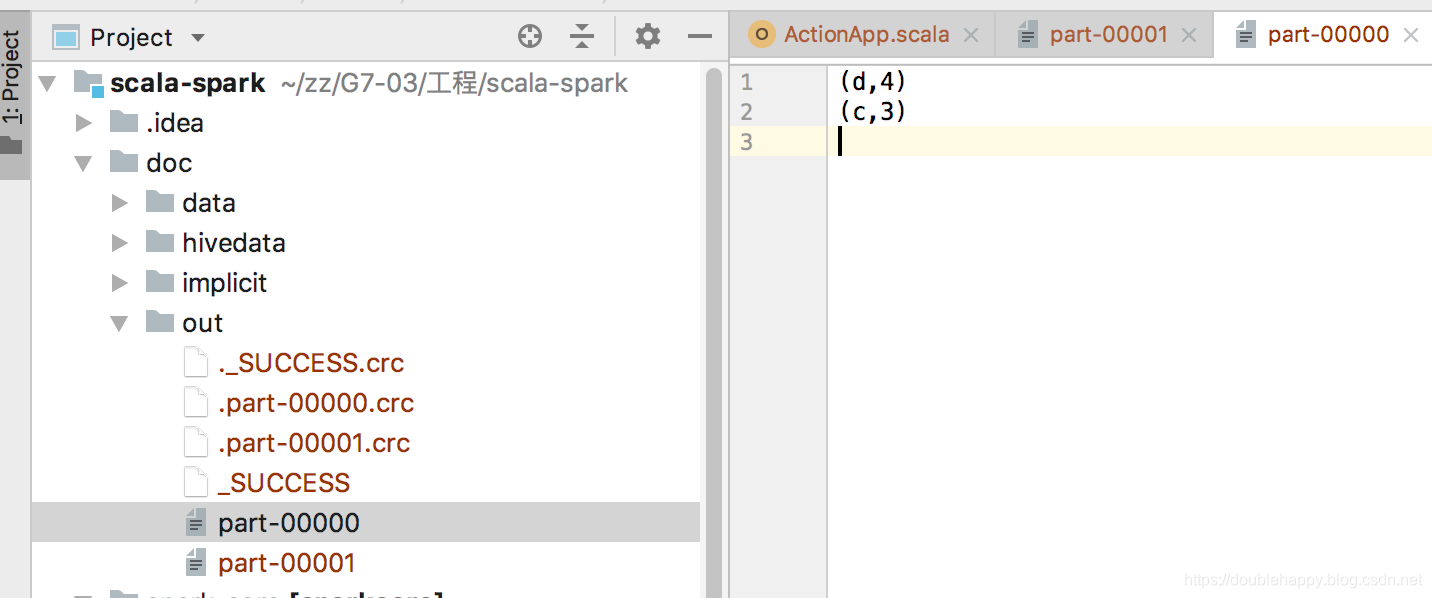
难道真的是分区排序么?在进行测试。
1 | scala> rdd2.sortBy(_._2,false).foreach(println) |
为什么rdd2.sortBy(.2,false).foreach(println)的结果不一样?
所以使用foreach在这里根本看不出来sortBy是全局排序还是分区排序
因为 rdd2是两个分区的 ,foreach执行的时候 不确定是哪个task先println 出来 明白吗?
所以sortBy 到底是什么排序?
全局排序 你看idea里的
所以你测试的时候 sortBy 后面不能跟着 foreach 来测试 要输出文件
通过 读取文件 来测试
(3)count
1 | /** |
1 | scala> val rdd = sc.parallelize(List(1,2,3,4,5)) |
(4) reduce 两两做操作
1 | scala> val rdd = sc.parallelize(List(1,2,3,4,5)) |
(5) first
1 | /** |
(6)take
1 | /** |
first底层调用take方法
1 | scala> val rdd = sc.parallelize(List(1,2,3,4,5)) |
(7) top
里面肯定是做了排序的
1 | /** |
1 | scala> val rdd = sc.parallelize(List(1,2,3,4,5)) |
(8)zipWithIndex
给你一个算子 你怎么知道他是 action还是 transformation??
action算子里面是有sc.runJob()方法的
eg:
所以zipWithIndex 它不是action算子
1 | /** |
1 | scala> val rdd = sc.parallelize(List(1,2,3,4,5)) |
(9)countByKey
这是action算子
1 | /** |
(10)collectAsMap 针对kv类型的
1 | /** |
1 |
|
Action算子官网:Action 算子