调优点:
为什么要使用压缩呢?
1 | 1.节省空间 (数据在hdfs上以3副本存储 如果采用压缩 占用空间会少一些) |
但是注意的是如果采用压缩,对机器的cpu的要求高,所以压缩的使用场景
1 | 1.存储数据的空间不够 |
如果core不够还采用压缩,那么还是别采用压缩啦。
压缩的技术
有损压缩(lossy compression) : 适用于图片和视频 允许丢失几帧
无损压缩(lossless compression):原始数据解压缩数据是没有丢失的
对称和非对称:就是压缩和解压的时间相同叫对称 ,反义。
压缩的使用场景结合mapreduce
数据压缩 map端输出可以用,reduce端输出也可以使用
1 | input |
spark、flink同样的
凡事都有两面性
空间和时间 ok
cpu 耗费 cpu的利用率会高 而且整个作业的处理时长会略微长一些
1 | 使用的压缩: |
常见的压缩格式
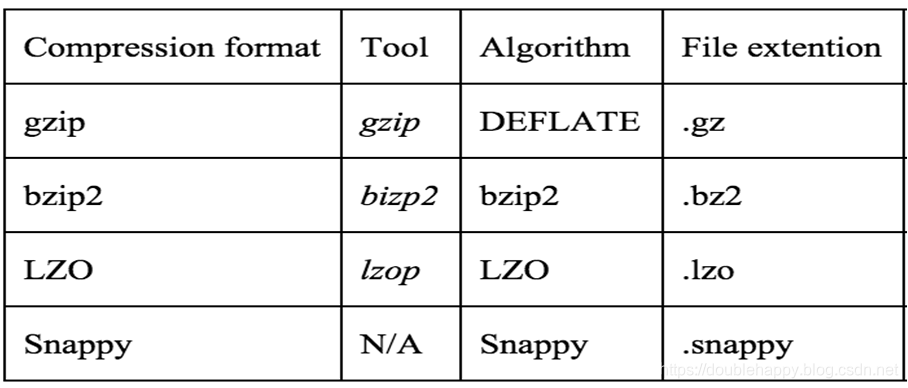
还有LZ4
如何选择呢,这么多压缩的格式 压缩比和解压缩度
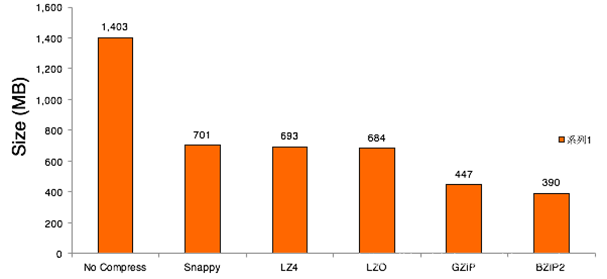
相同配置的机器测试看看
压缩比:压缩前和压缩后的比值
1 | 压缩比 Bzip2 30% Gzip (两者之间) ,snappy \lzo50% |
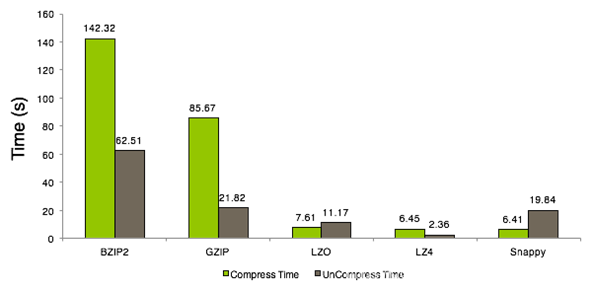
压缩能否分片
hadoop作业是io密集型的,所以他的作业尽可能的采用压缩
spark、flink作业是pipline型的
注意:压缩又的是java写的,有的是native的,
所以你要在Hadoop里使用LZO(native的) 需要下载一些native的依赖
1 | Splitable: |
压缩是否支持分割
1 | 分割: 注意是压缩过后的压缩文件是否支持分割的 |
是否能分割对使用哪个压缩有很大的影响意义
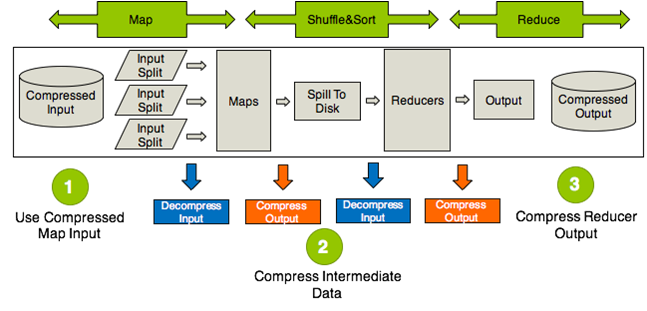
上图三个部分使用压缩:mapreduce的流程使用压缩的部分
1 | input: |
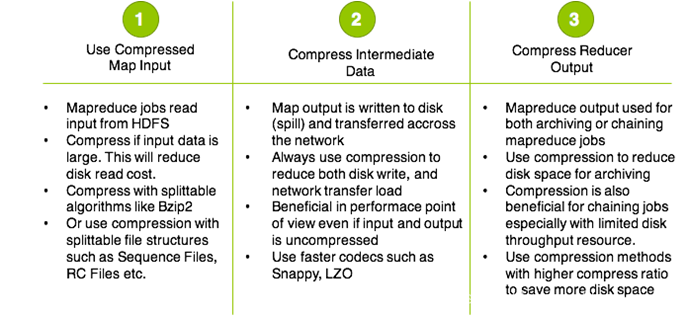
1 | 三个地方使用的压缩推荐: |
MapReduce作业使用压缩实战
在Hadoop的core-site.xml里配置压缩 ,mapreduce-site.xml配置你采用压缩的位置(map的输出和reduce的输出)
1 | core-site.xml: |
1 | mapreduce-site.xml: |
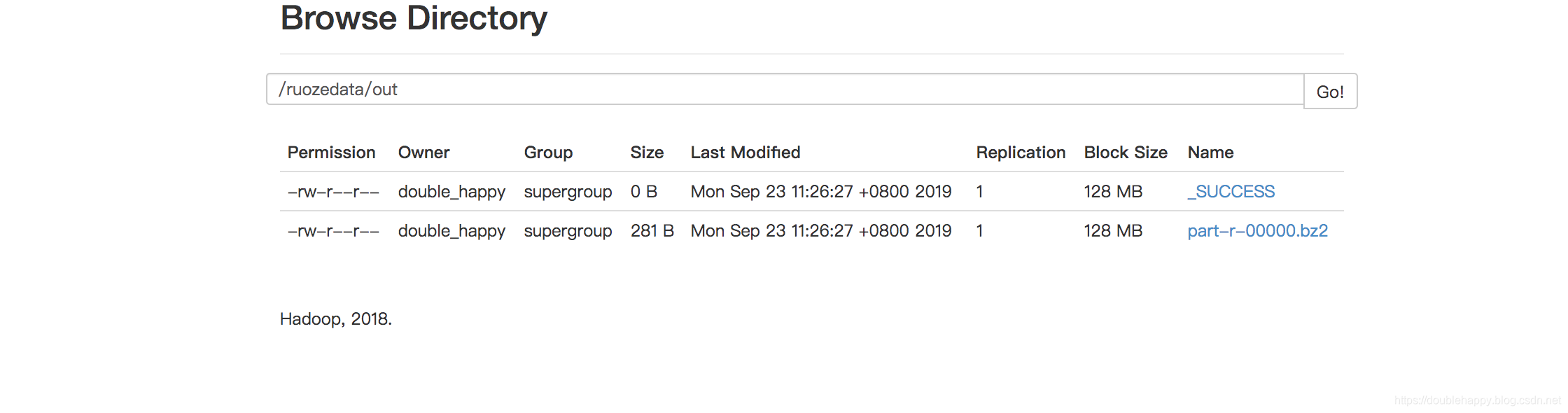
测试:
wc
hdfs最后生成的结果是以bzip结尾的
Hive的压缩使用
1 | 1.创建表: |
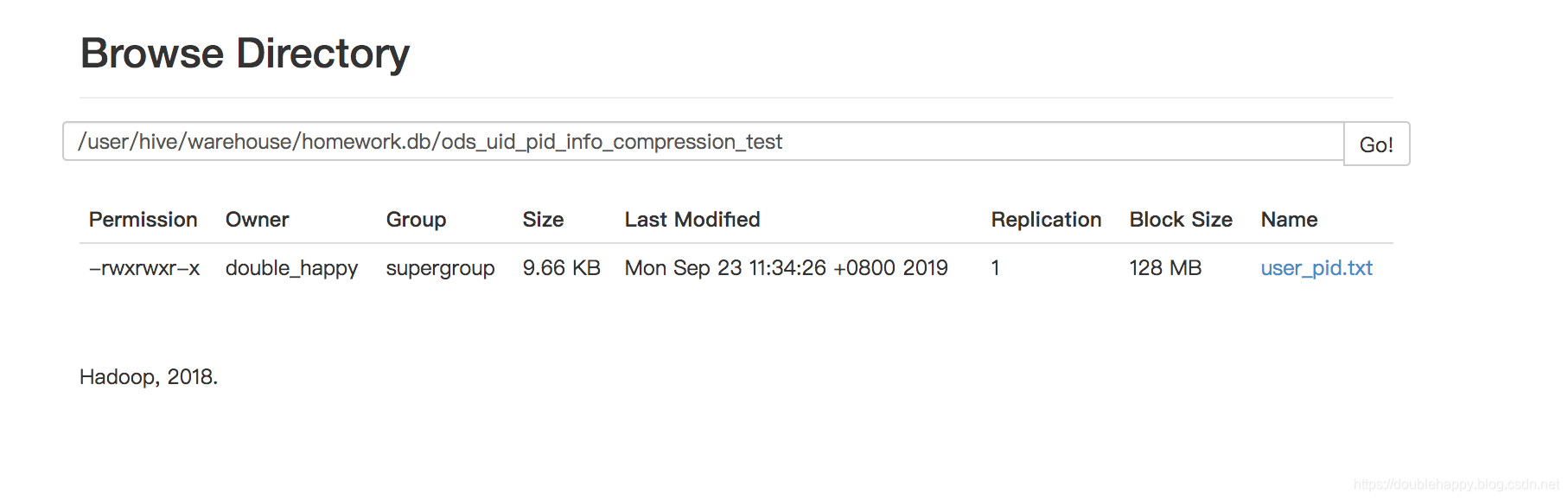
1 | 使用压缩: |
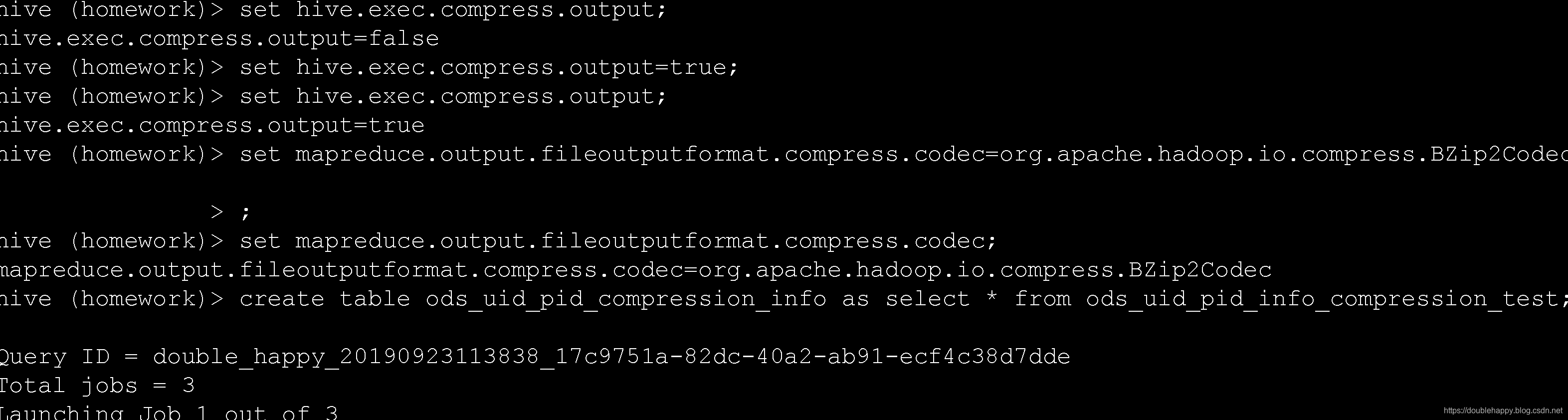
查看hdfs上数据大小: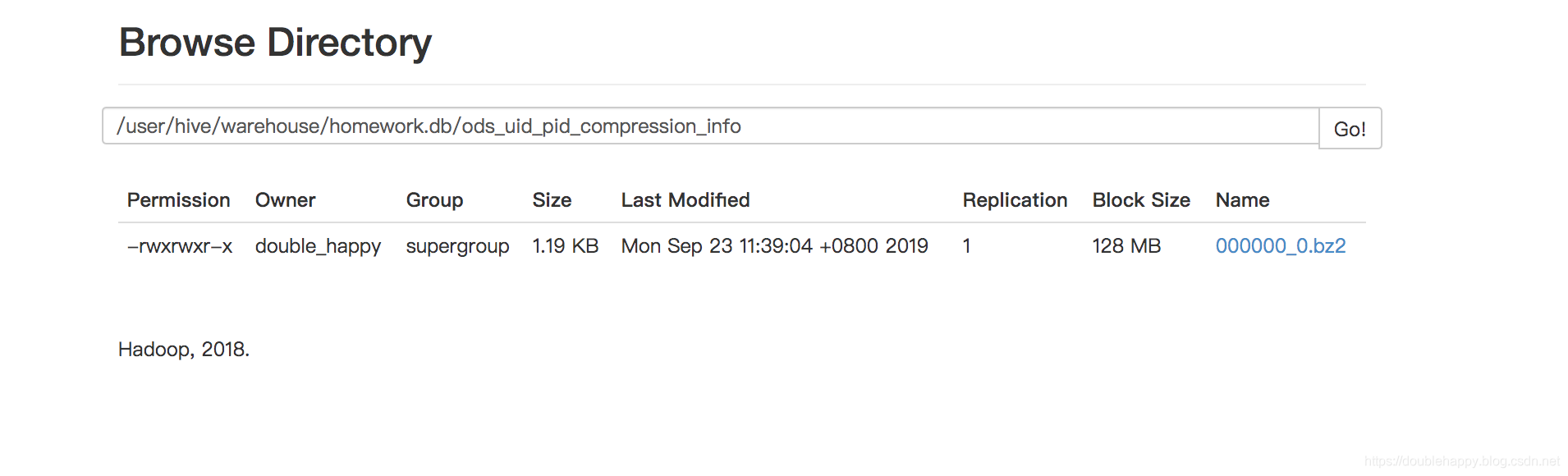
可以对比一下 数据小了。
1 | 注意: |