1 | 这个问题我在SparkSQL001里面提出过这个问题 |
数据格式和内容
1 | object TextFileApp { |
1 | object UDFUtils { |
1 | 上面的解决办法明白了吗 ? |
1 | 这个问题我在SparkSQL001里面提出过这个问题 |
数据格式和内容
1 | object TextFileApp { |
1 | object UDFUtils { |
1 | 上面的解决办法明白了吗 ? |
1 | 一台机器能运行多少个container 到底是由谁决定的 ? |
1 | 生产上一台机器: |
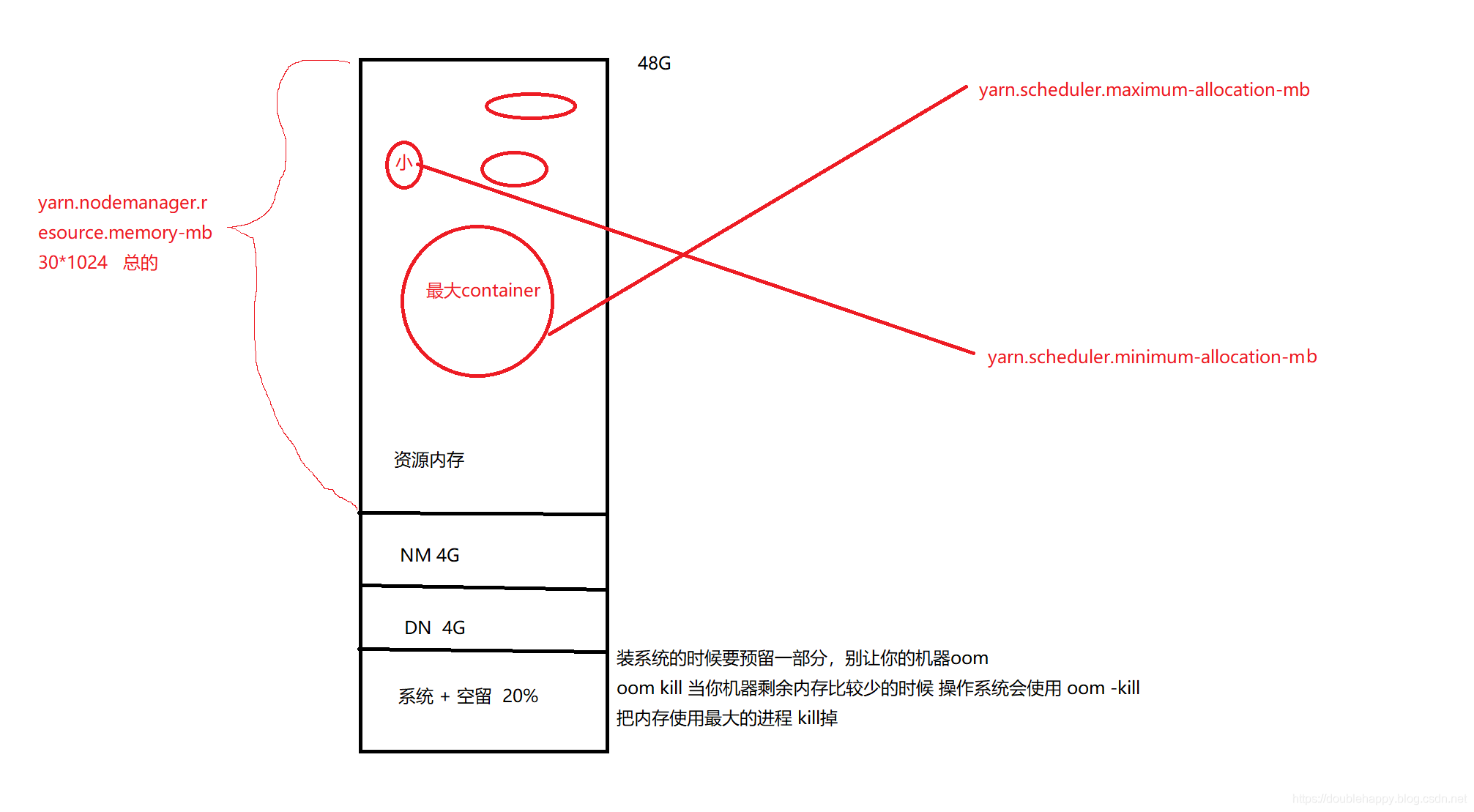
内存:
1 | 生产一: |
1 | 生产二: |
1 | 生产三: |
cpu
1 | CPU: |
1 | 之前的ss程序都是运行在idea |
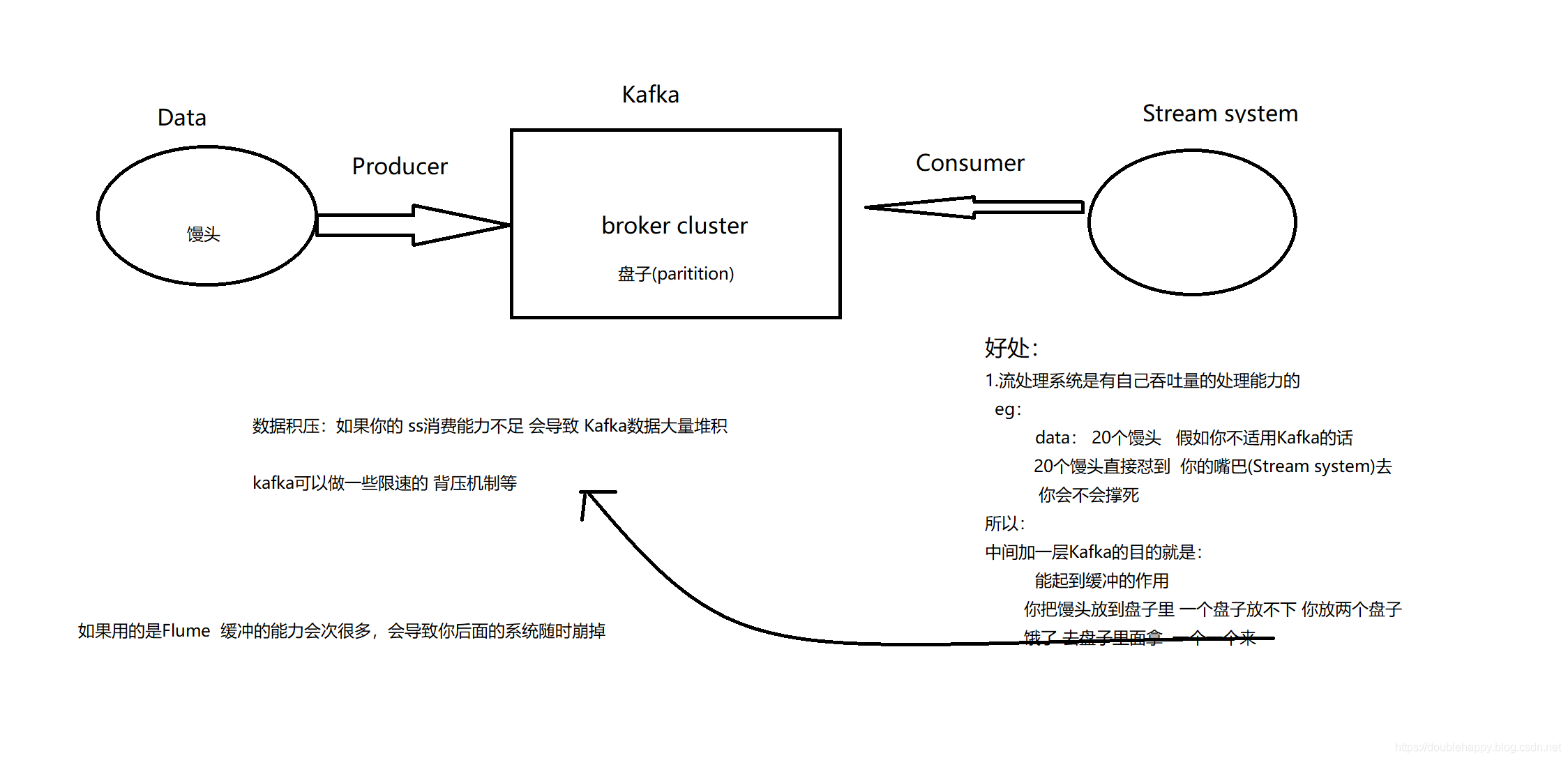
1 | 数据从Kafka过来然后 ss消费到 把wc统计出来: |
1 | 运行结果: |
1 | 提交命令: |
1 | [double_happy@hadoop101 bin]$ ./spark-submit \ |
1 | 注意: |
Deploying:部署
As with any Spark applications, spark-submit is used to launch your application.
For Scala and Java applications, if you are using SBT or Maven for project management, then package spark-streaming-kafka-0-10_2.12 and its dependencies into the application JAR. Make sure spark-core_2.12 and spark-streaming_2.12 are marked as provided dependencies as those are already present in a Spark installation. Then use spark-submit to launch your application (see Deploying section in the main programming guide).
这种方式不好 换一个
1 | 因为需要把这个spark-streaming-kafka-0-10_2.11包 传到服务器上 |
1 | 那么刚刚packages 有小问题 那么怎么办呢 ? |
1 | 注意: |
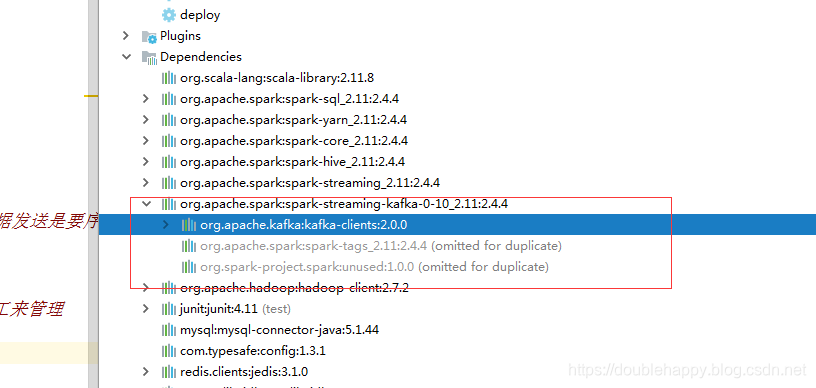
1 | 因为sparkStreaming-kafka包里面包含kafka-client |
1 | [double_happy@hadoop101 bin]$ ./spark-submit --master local[2] --name StreamingKakfaDirectYarnApp --jars /home/double_happy/lib/spark-streaming-kafka-0-10_2.11-2.4.4.jar,/home/double_happy/lib/kafka-clients-2.0.0.jar --class com.ruozedata.spark.ss04.StreamingKakfaDirectYarnApp /home/double_happy/lib/spark-core-1.0.jar hadoop101:9092,hadoop101:9093,hadoop101:9094 double_happy_offset double_happy_group3 |
transformation
1 | 之前写的算子 都是按照每一个批次来处理的 或者是可以累计的等 |
Window Operations
As shown in the figure, every time the window slides over a source DStream, the source RDDs that fall within the window are combined and operated upon to produce the RDDs of the windowed DStream. In this specific case, the operation is applied over the last 3 time units of data, and slides by 2 time units. This shows that any window operation needs to specify two parameters.
window length - The duration of the window (3 in the figure).
sliding interval - The interval at which the window operation is performed (2 in the figure).
These two parameters must be multiples of the batch interval of the source DStream (1 in the figure).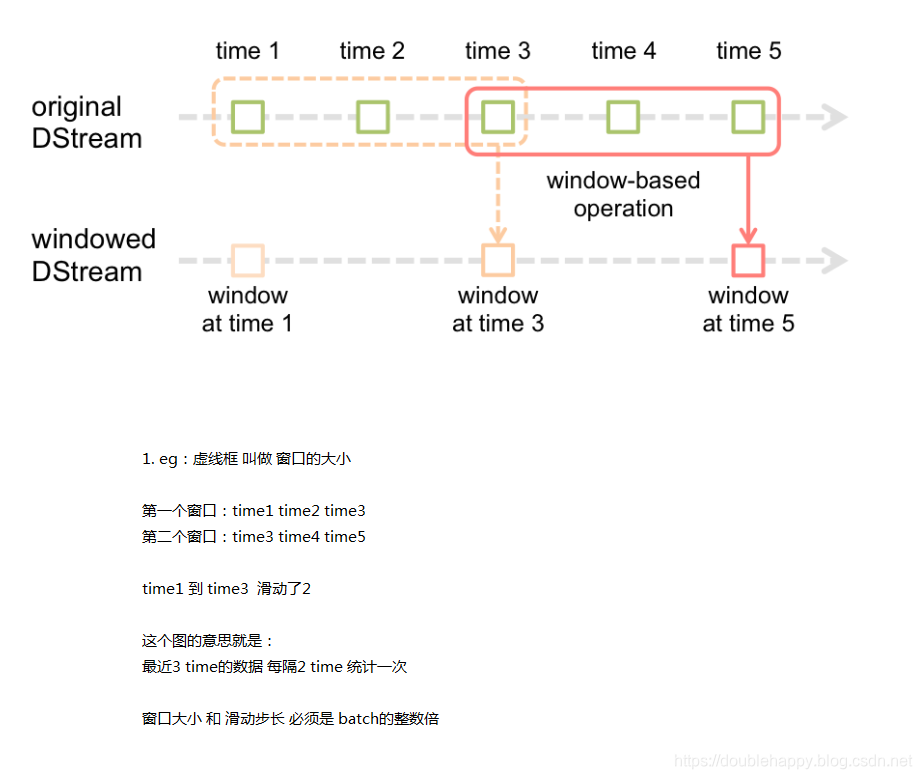
案列
1 | /** |
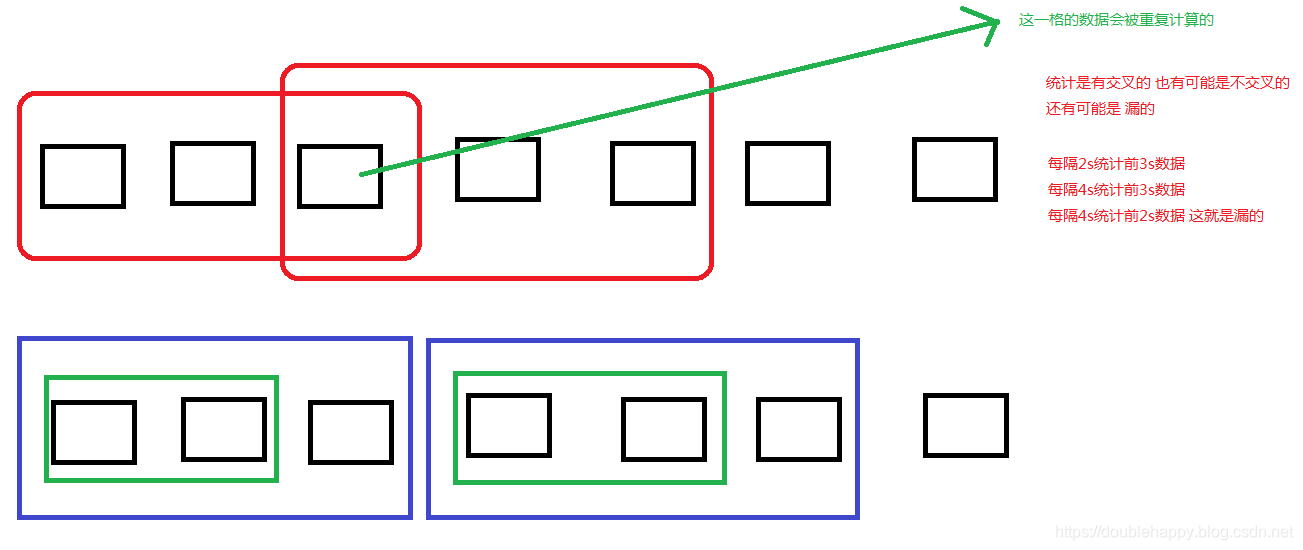
1 | 5秒的批次 每隔5秒统计前10秒 |
DataFrame and SQL Operations
DataFrame and SQL Operations
这是批流一体带来的非常大的好处
1 | object StreamingSqlApp { |
消费语义****
Definitions
The semantics of streaming systems are often captured in terms of how many times each record can be processed by the system. There are three types of guarantees that a system can provide under all possible operating conditions (despite failures, etc.)
1.At most once: Each record will be either processed once or not processed at all.
2.At least once: Each record will be processed one or more times. This is stronger than at-most once as it ensure that no data will be lost. But there may be duplicates.
3.Exactly once: Each record will be processed exactly once - no data will be lost and no data will be processed multiple times. This is obviously the strongest guarantee of the three.
1 | 1.流系统中 你的数据被处理了多少次 根据处理多少次 分为三大类 |
Semantics of output operations
Output operations (like foreachRDD) have at-least once semantics, that is, the transformed data may get written to an external entity more than once in the event of a worker failure. While this is acceptable for saving to file systems using the saveAsFiles operations (as the file will simply get overwritten with the same data), *additional effort may be necessary to achieve exactly-once semantics. There are two approaches.
1.Idempotent updates: Multiple attempts always write the same data. For example, saveAs*Files** always writes the same data to the generated files.
2.Transactional updates: All updates are made transactionally so that updates are made exactly once atomically. One way to do this would be the following.
Use the batch time (available in foreachRDD) and the partition index of the RDD to create an identifier. This identifier uniquely identifies a blob data in the streaming application.
Update external system with this blob transactionally (that is, exactly once, atomically) using the identifier. That is, if the identifier is not already committed, commit the partition data and the identifier atomically. Else, if this was already committed, skip the update.
1 | dstream.foreachRDD { (rdd, time) => //time就是你当前批次的时间 |
1 | Output operations (like foreachRDD) have at-least once semantics |
1 | 1.减少每隔批次处理的时间 |
1 | object StreamingTuningApp { |
华丽——————————————————————————————————
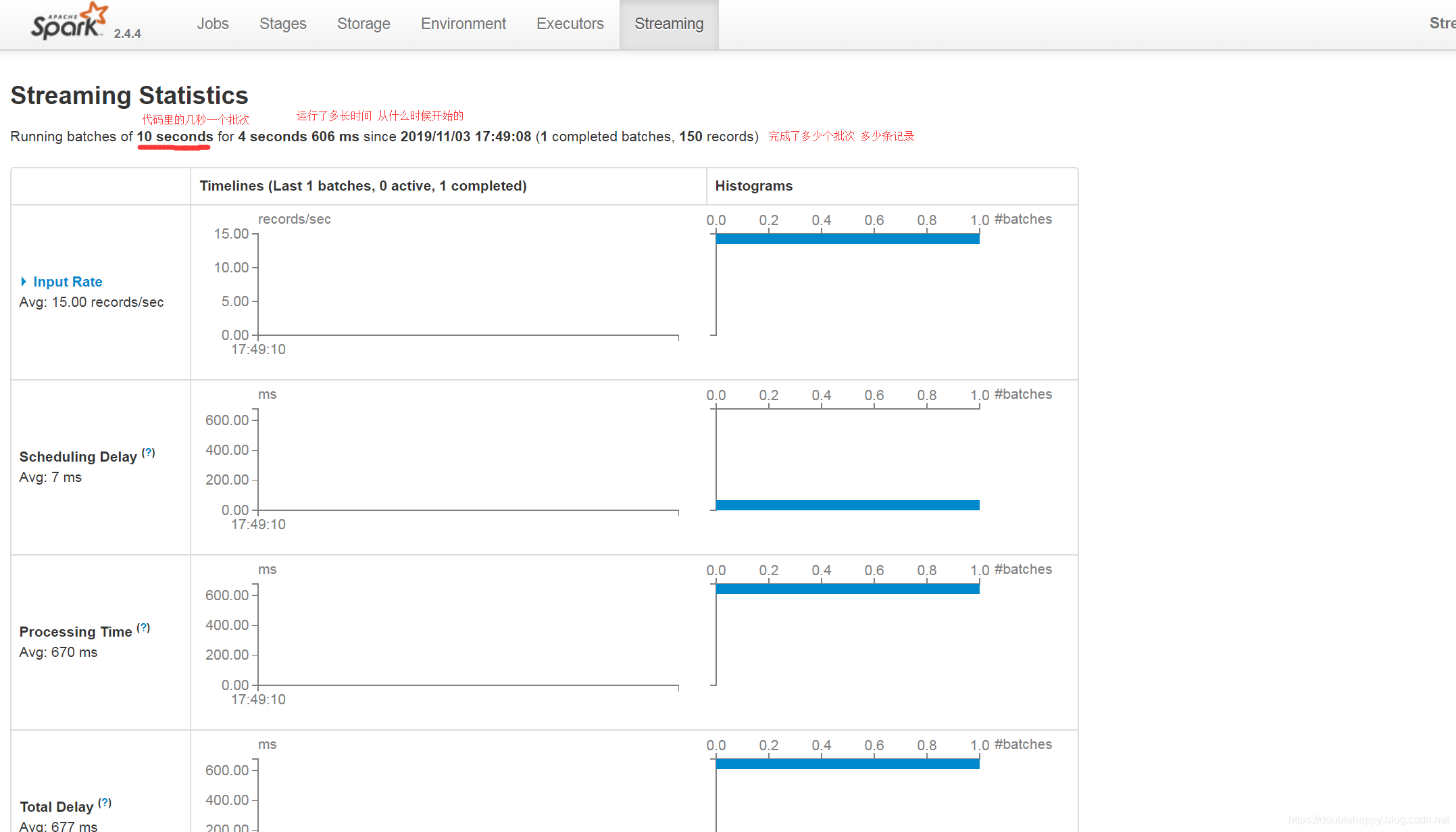
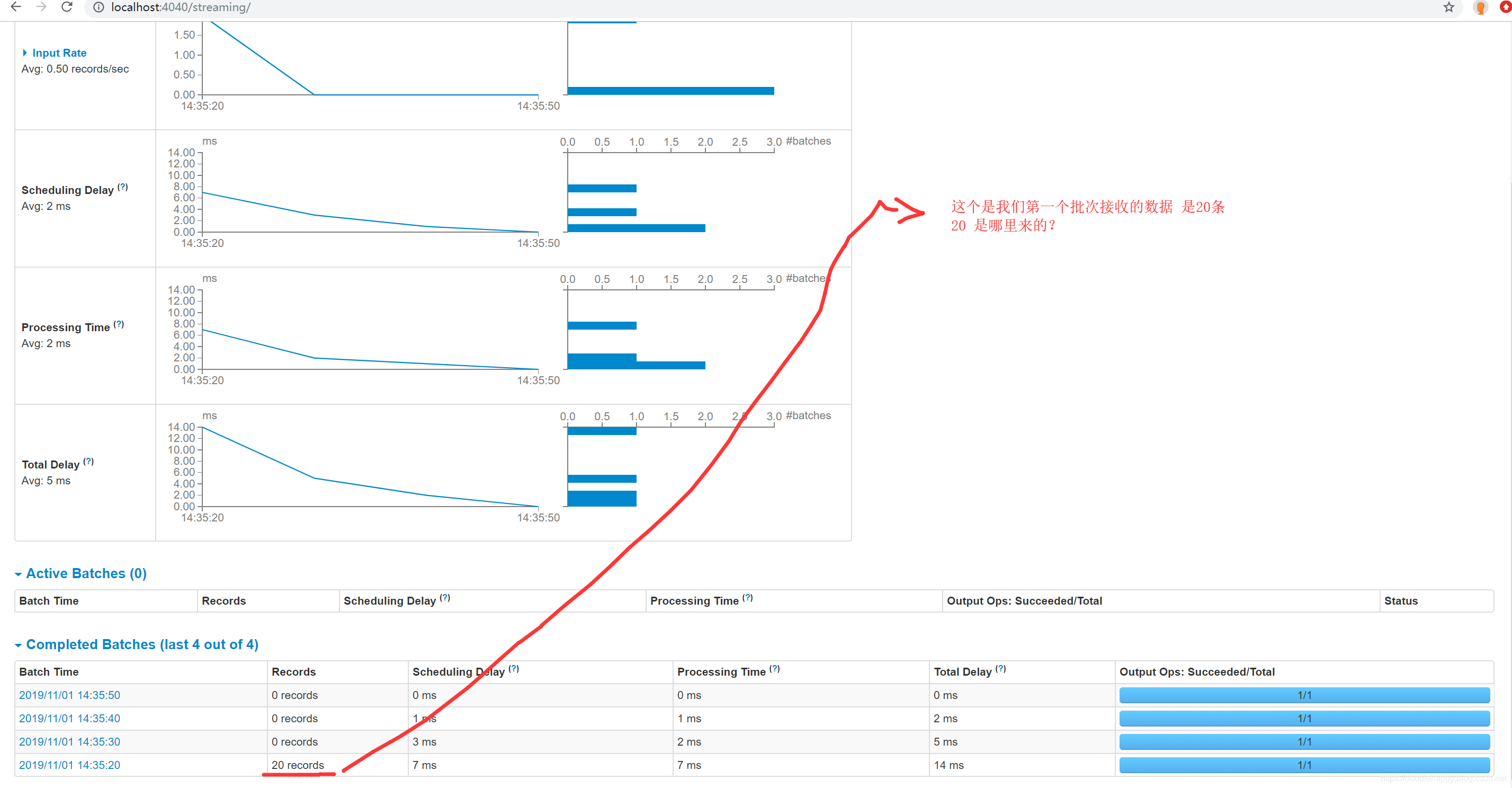
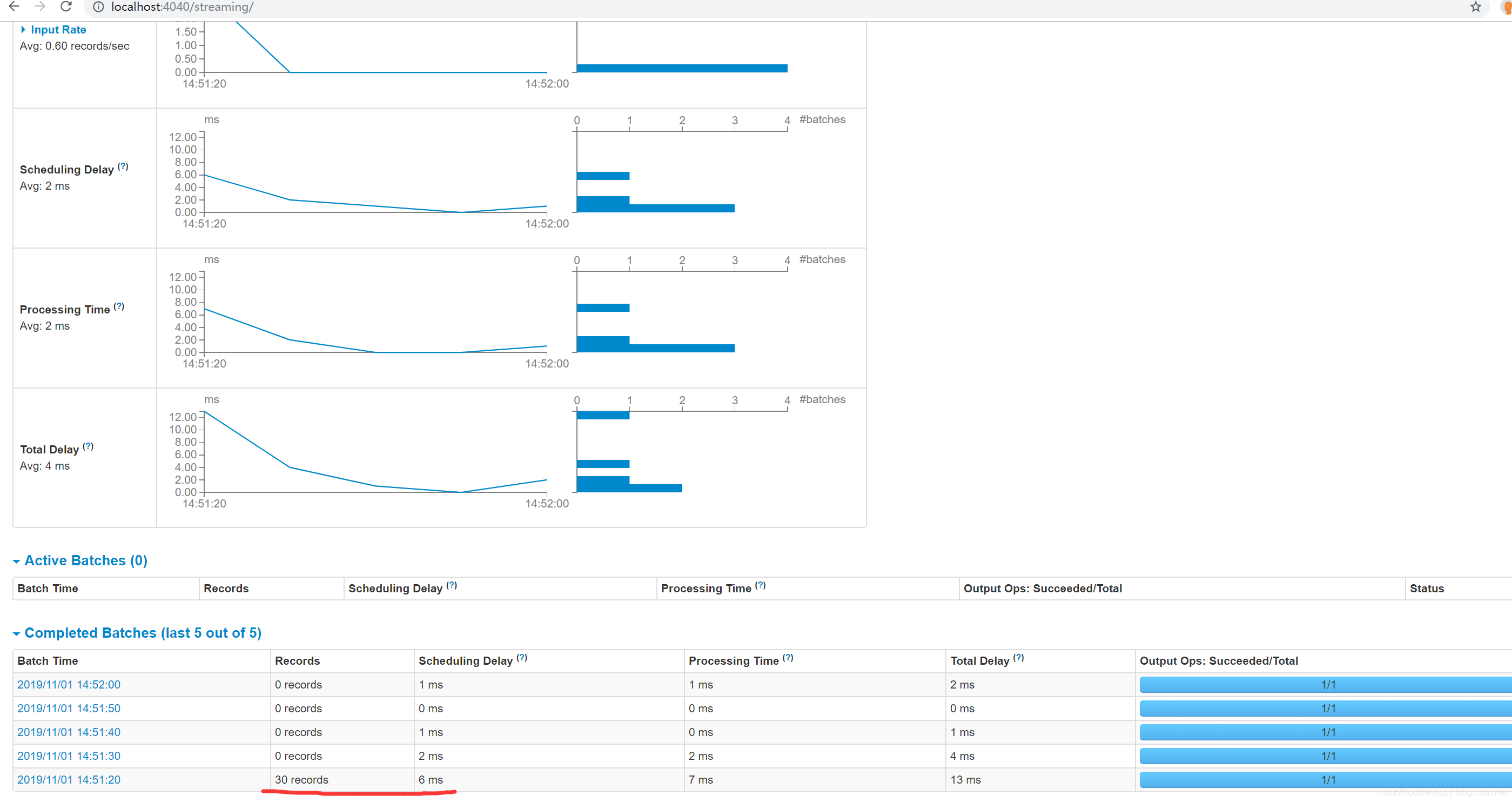
1 | ok 我们往kafka写10条数据 |
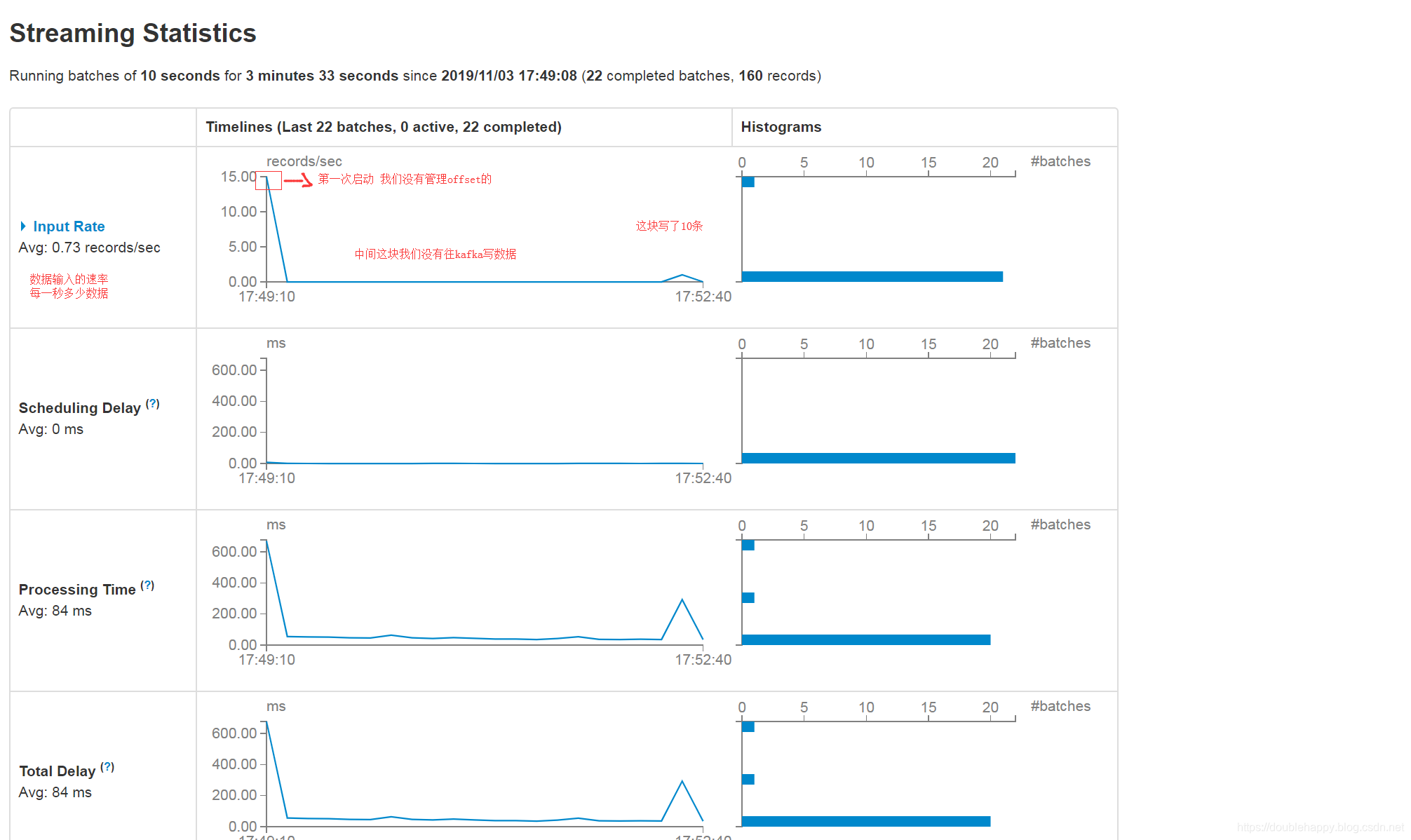
华丽——————————————————————————————————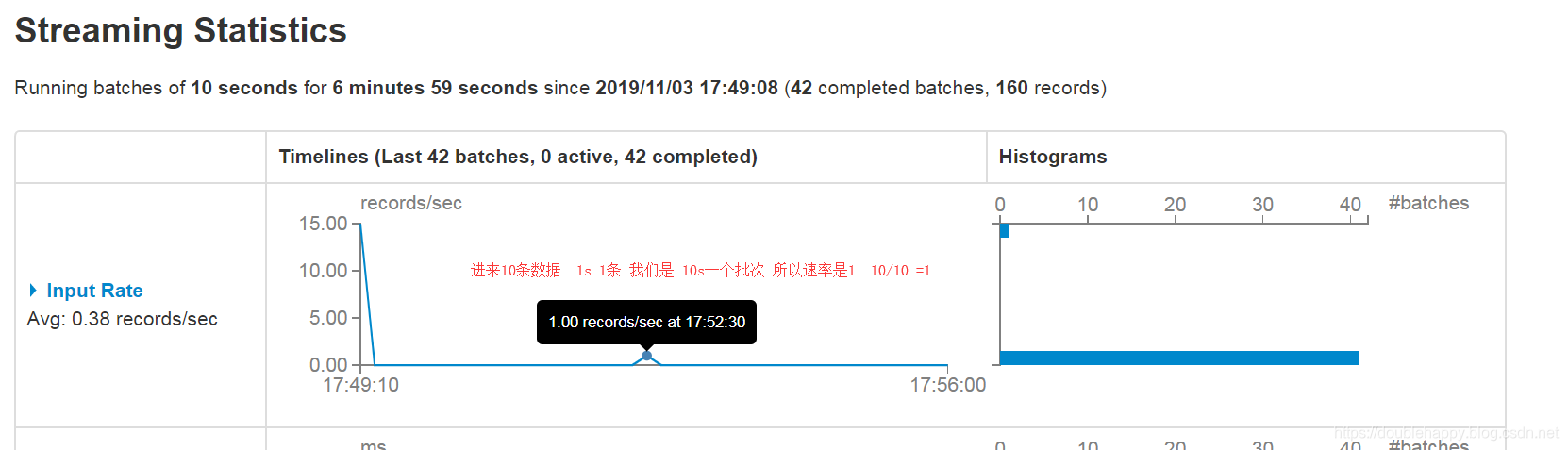
华丽——————————————————————————————————
1 | Input Rate:数据输入的速率 |
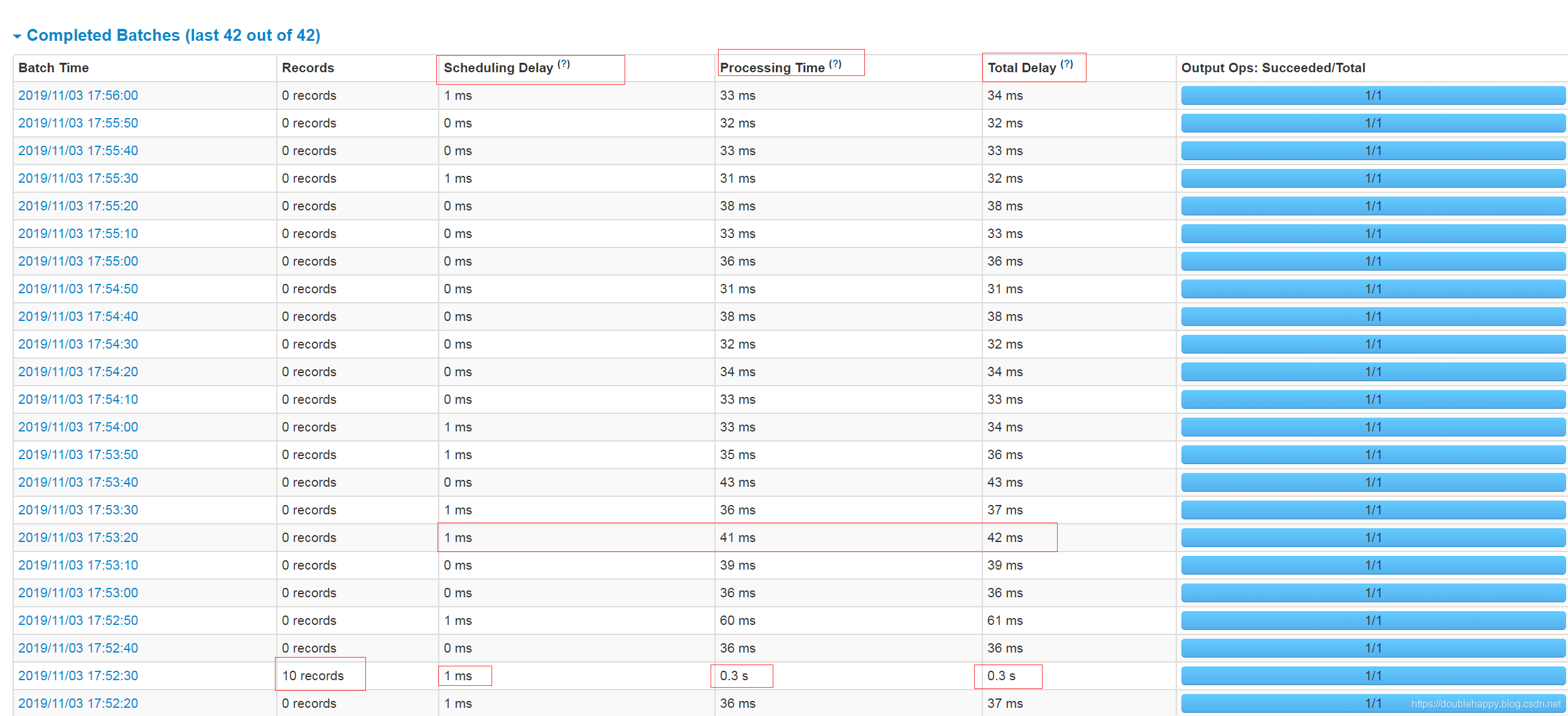
1 | 最佳实践: |
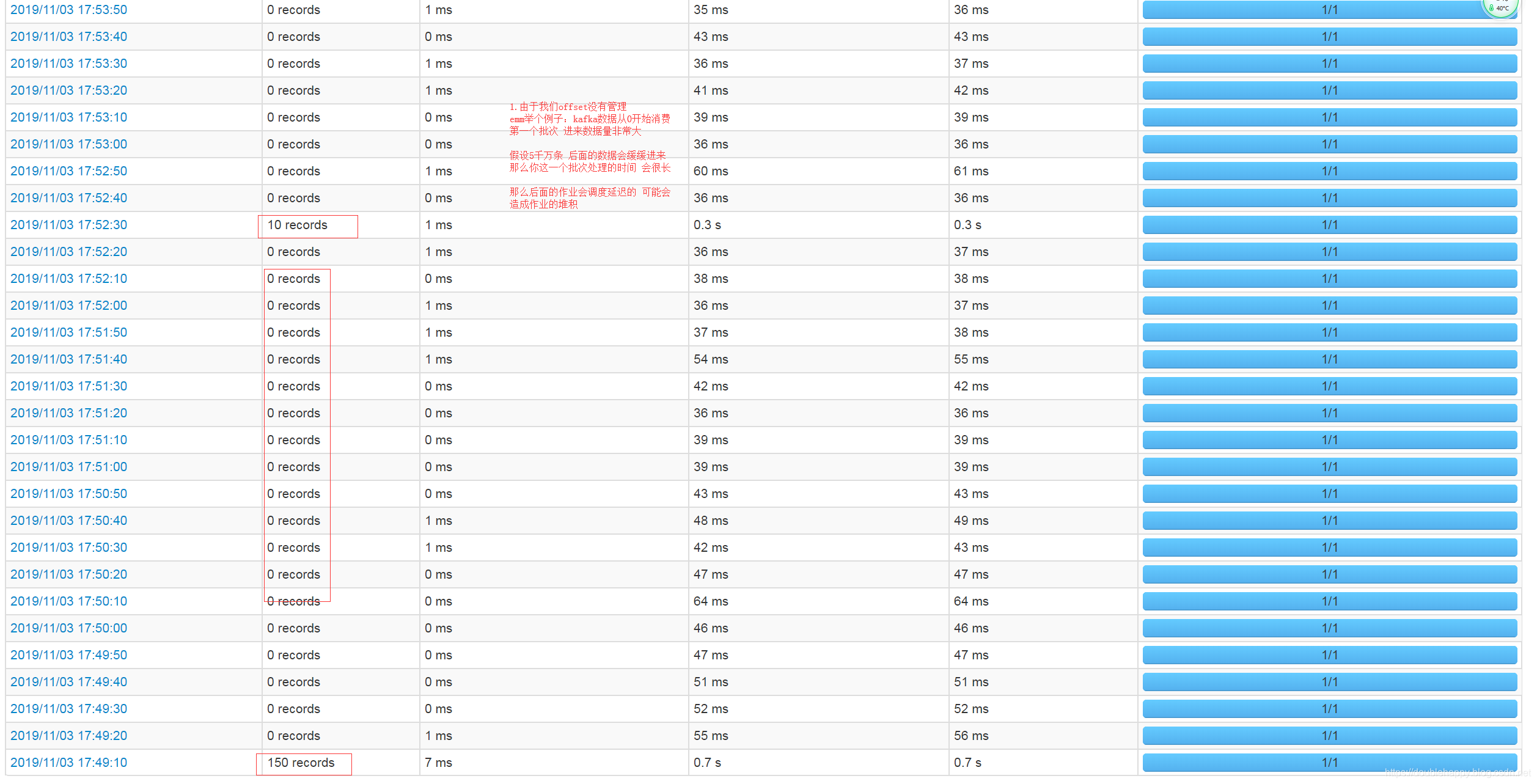
1 | 这个地方kafka是有一个限速的 |
1 | 修改代码: |
1 | 先测试没有修改前的: |
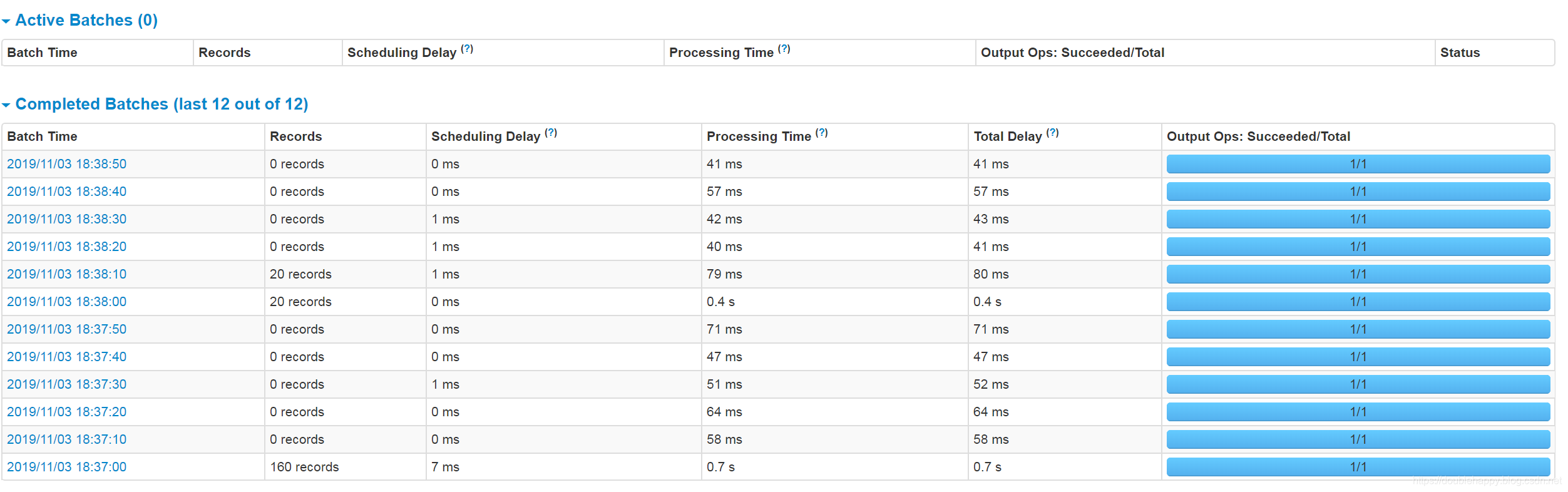
1 | 测试修改后的 |

1 | 说明这个参数没有生效 emm |
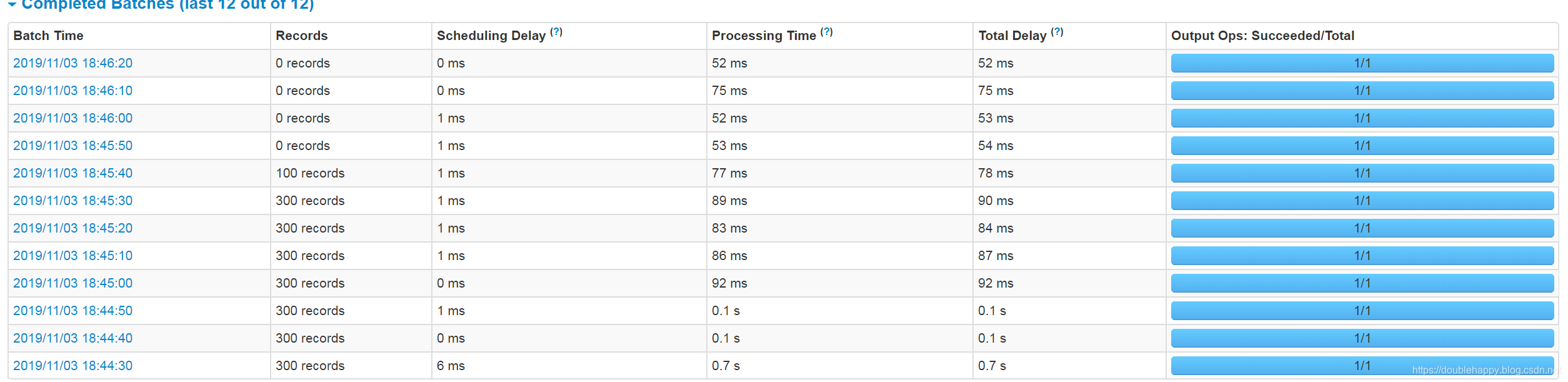
1 | 看 说面限速成功了 这样第一次处理就很好的限制你能处理的范围内 |
1 | 背压机制 : backpressure 1.5版本引进来的 |
1 | 背压:它是根据当前批次决定后一个批次 |

1 | 如果按照官方这个描述 数据是从receiver过来的 |
1 | 我设置为150 |

不能使用
1 | 那么该怎么办呢? 自己找找答案 |
1 | spark.streaming.stopGracefullyOnShutdown |
1 | def getStreamingContext(appname: String, batch: Int, defalut: String = "local[2]") = { |
1 | 批流一体:未来的发展趋势 |
1 | Spark Streaming provides two categories of built-in streaming sources. |
1 | Some of these advanced sources are as follows. |
Kafka整合
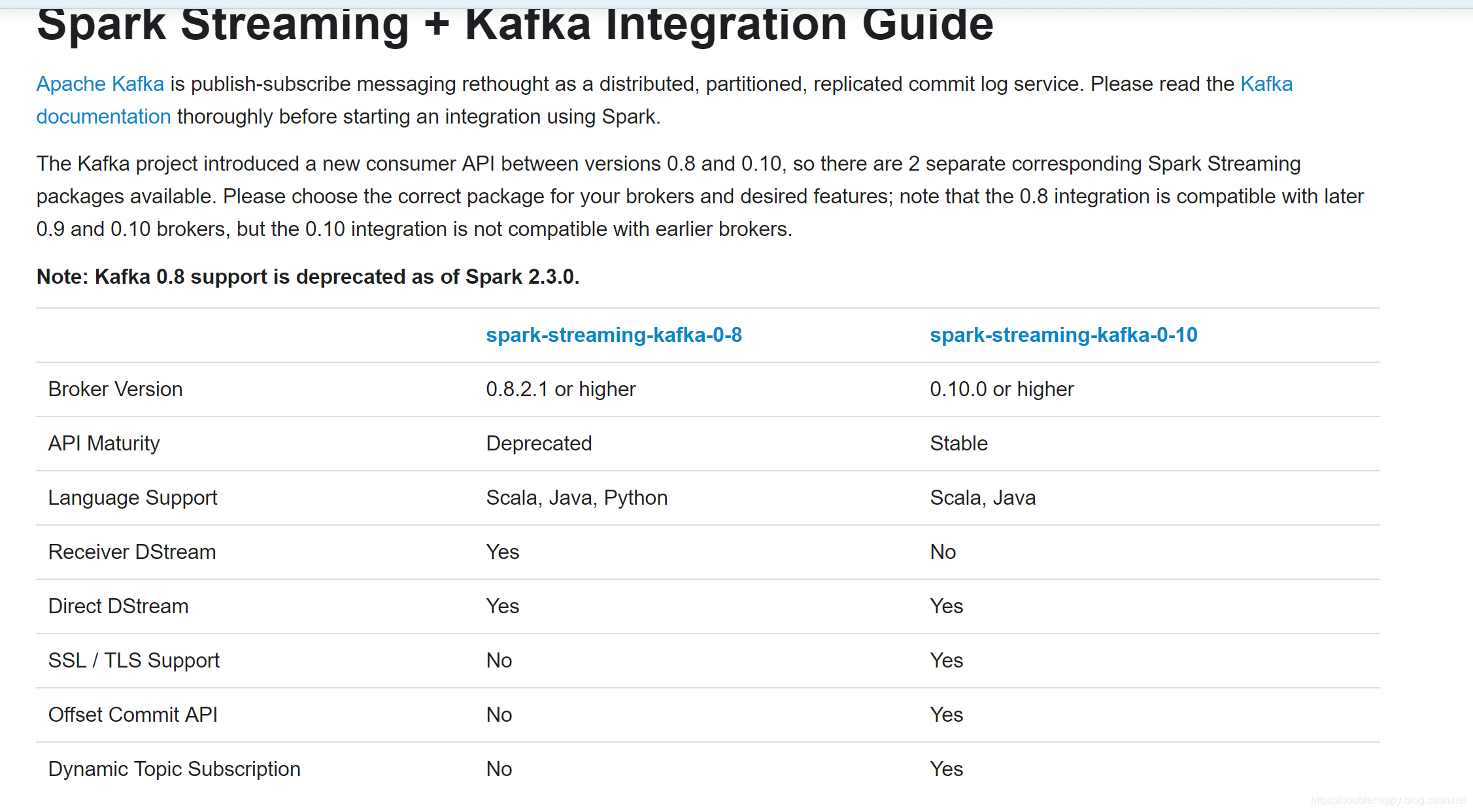
Spark Streaming + Kafka Integration Guide
The Kafka project introduced a new consumer API between versions 0.8 and 0.10, so there are 2 separate corresponding Spark Streaming packages available. Please choose the correct package for your brokers and desired features; note that the 0.8 integration is compatible with later 0.9 and 0.10 brokers, but the 0.10 integration is not compatible with earlier brokers.
1 | 1.高阶Api |
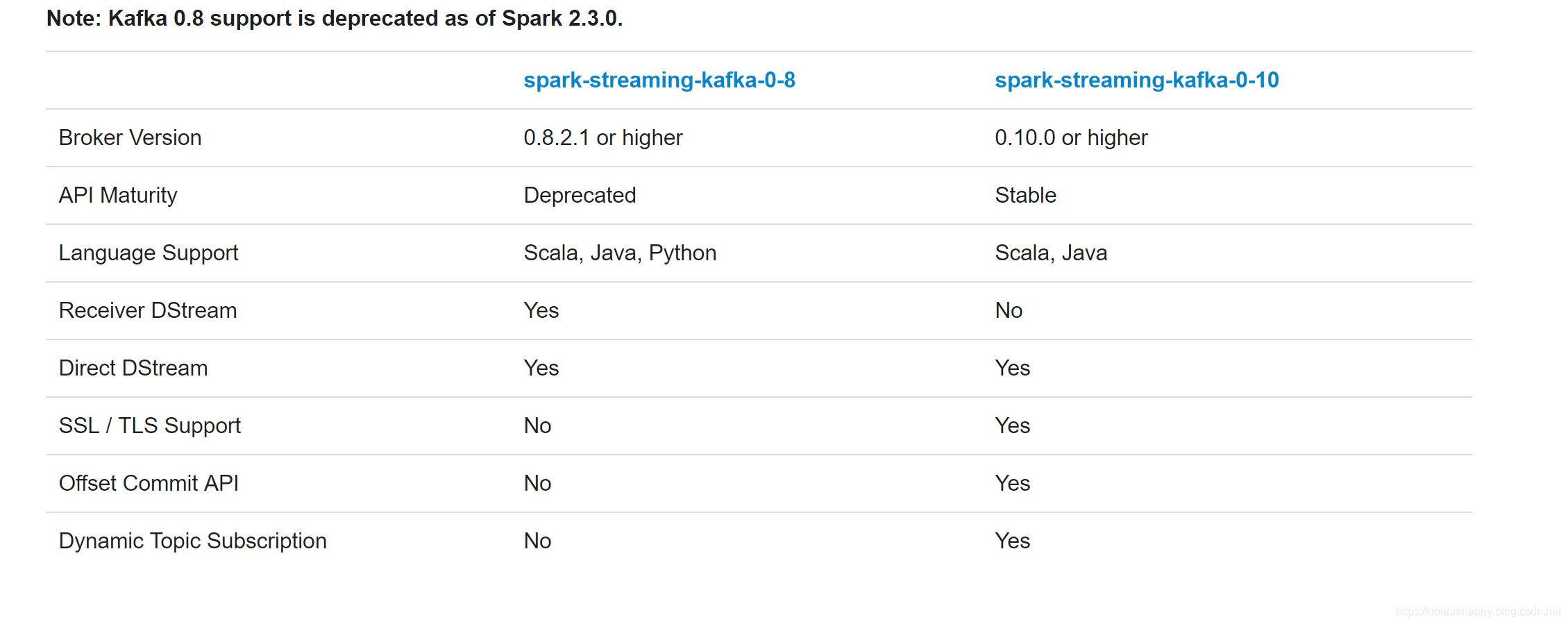
1 | 一定要用这个: |
1 | spark-streaming-kafka-0-8: |
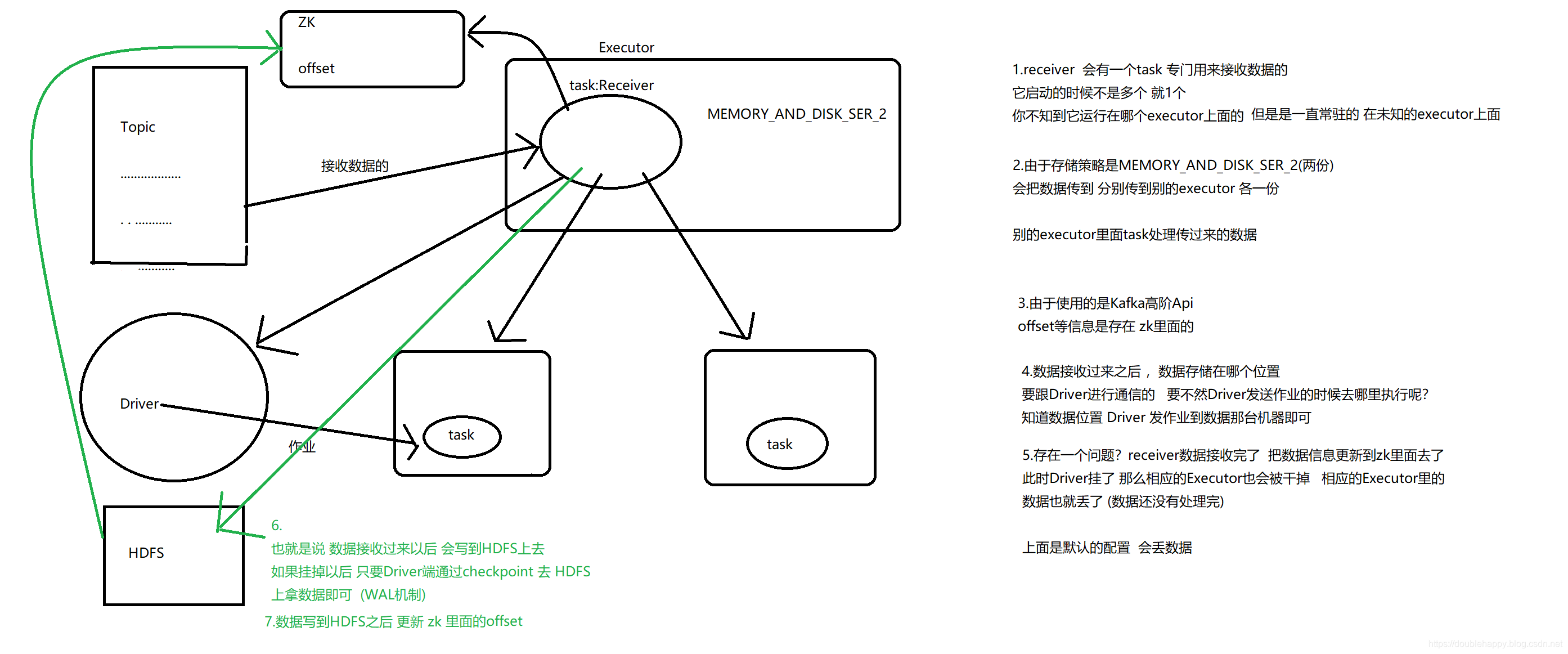
华丽的分割线———————————————————————————————————————-
However, under default configuration, this approach can lose data under failures (see receiver reliability. To ensure zero-data loss, you have to additionally enable Write-Ahead Logs in Spark Streaming (introduced in Spark 1.2). This synchronously saves all the received Kafka data into write-ahead logs on a distributed file system (e.g HDFS), so that all the data can be recovered on failure. See Deploying section in the streaming programming guide for more details on Write-Ahead Logs.
1 | WAL机制:先把日志记录下来 这里就是数据 |
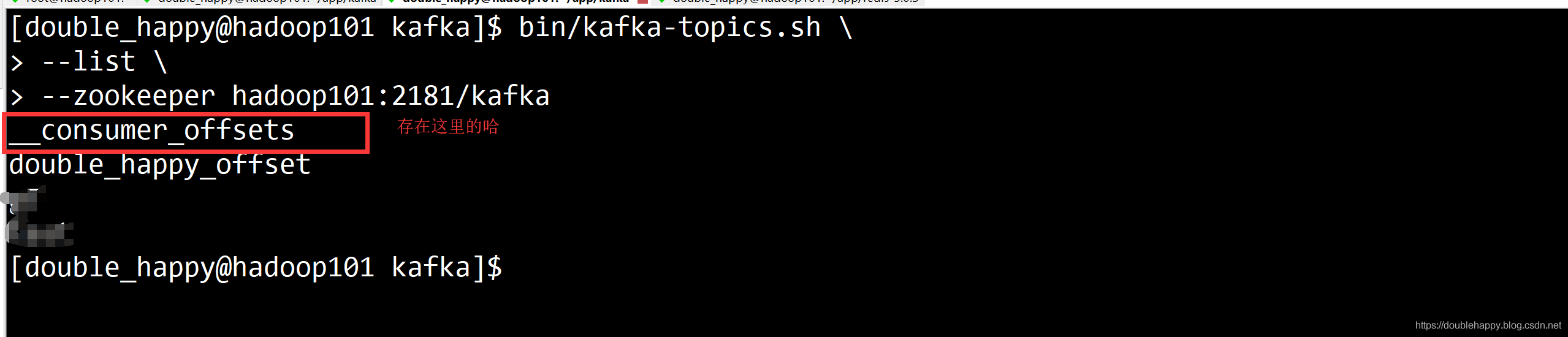
1 | 注意:Kafka的整合只有一个工具类 叫KafkaUtils |

Points to remember:
Topic partitions in Kafka do not correlate to partitions of RDDs generated in Spark Streaming. So increasing the number of topic-specific partitions in the KafkaUtils.createStream() only increases the number of threads using which topics that are consumed within a single receiver. It does not increase the parallelism of Spark in processing the data. Refer to the main document for more information on that.
1 | Topic是有partition的 |
Multiple Kafka input DStreams can be created with different groups and topics for parallel receiving of data using multiple receivers.
1 | 总结: |
spark-streaming-kafka-0-10 重点
spark-streaming-kafka-0-10
The Spark Streaming integration for Kafka 0.10 is similar in design to the 0.8 Direct Stream approach. It provides simple parallelism, 1:1 correspondence between Kafka partitions and Spark partitions, and access to offsets and metadata. However, because the newer integration uses the new Kafka consumer API instead of the simple API, there are notable differences in usage. This version of the integration is marked as experimental, so the API is potentially subject to change.
1 | Offset管理的时候不同 |
1 | Direct |
案例
1 | Producer: console (测试的时候 ) 就是使用KafkaApi代码实现 |
1 | KafkaProducer: |
1 | 怎么发送呢? |
1 | [double_happy@hadoop101 kafka]$ bin/kafka-console-consumer.sh \ |
对接
1 | /** |
1 | object StreamingKakfaDirectApp { |
1 | object StreamingKakfaDirectApp { |
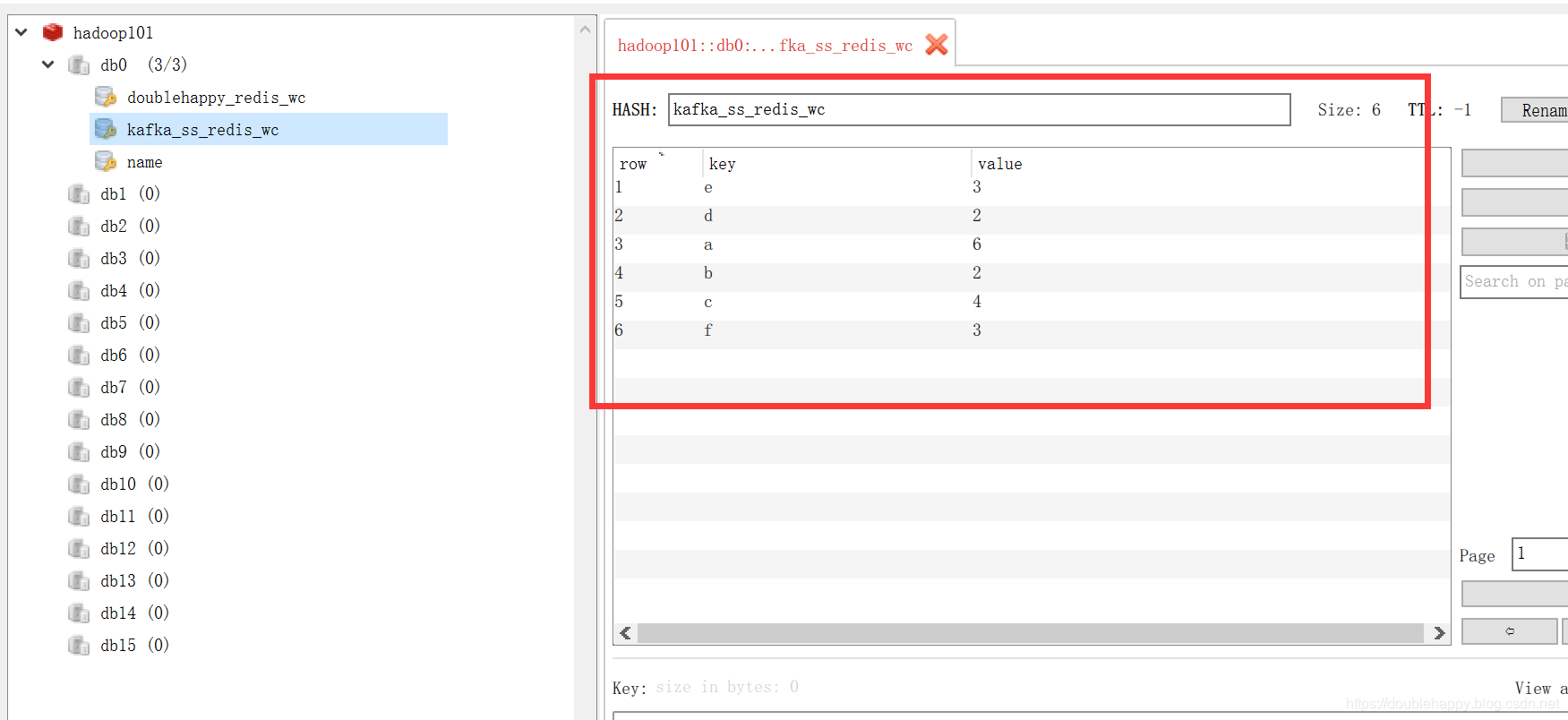
1 | hadoop101:6379> keys * |
1 | 这个时候 把实时代码关掉 : |
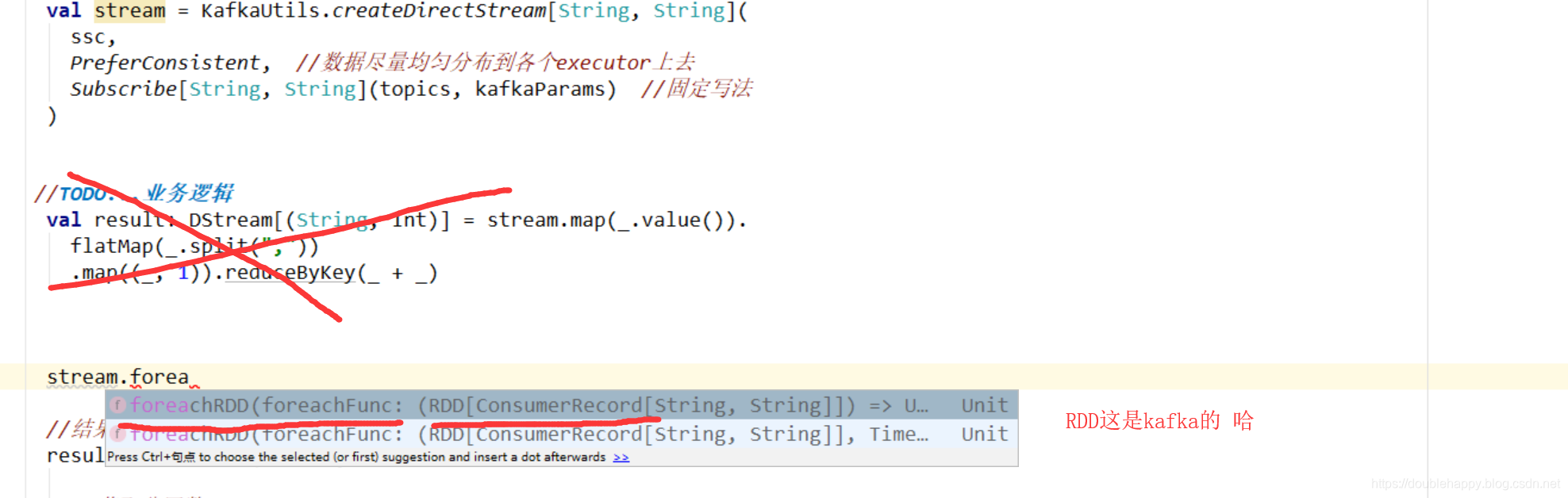
1 | trait HasOffsetRanges { |
1 | 获取offset: |
1 | 为什么报错呢? ***** 而且分区数还是2 说明不对 |
1 | 获取offset: |
1 | ${x.topic} ${x.partition} ${x.fromOffset} ${x.untilOffset} |
1 | 很多方式 : |
1 | 2.Kafka itself : |
第二次 重启之后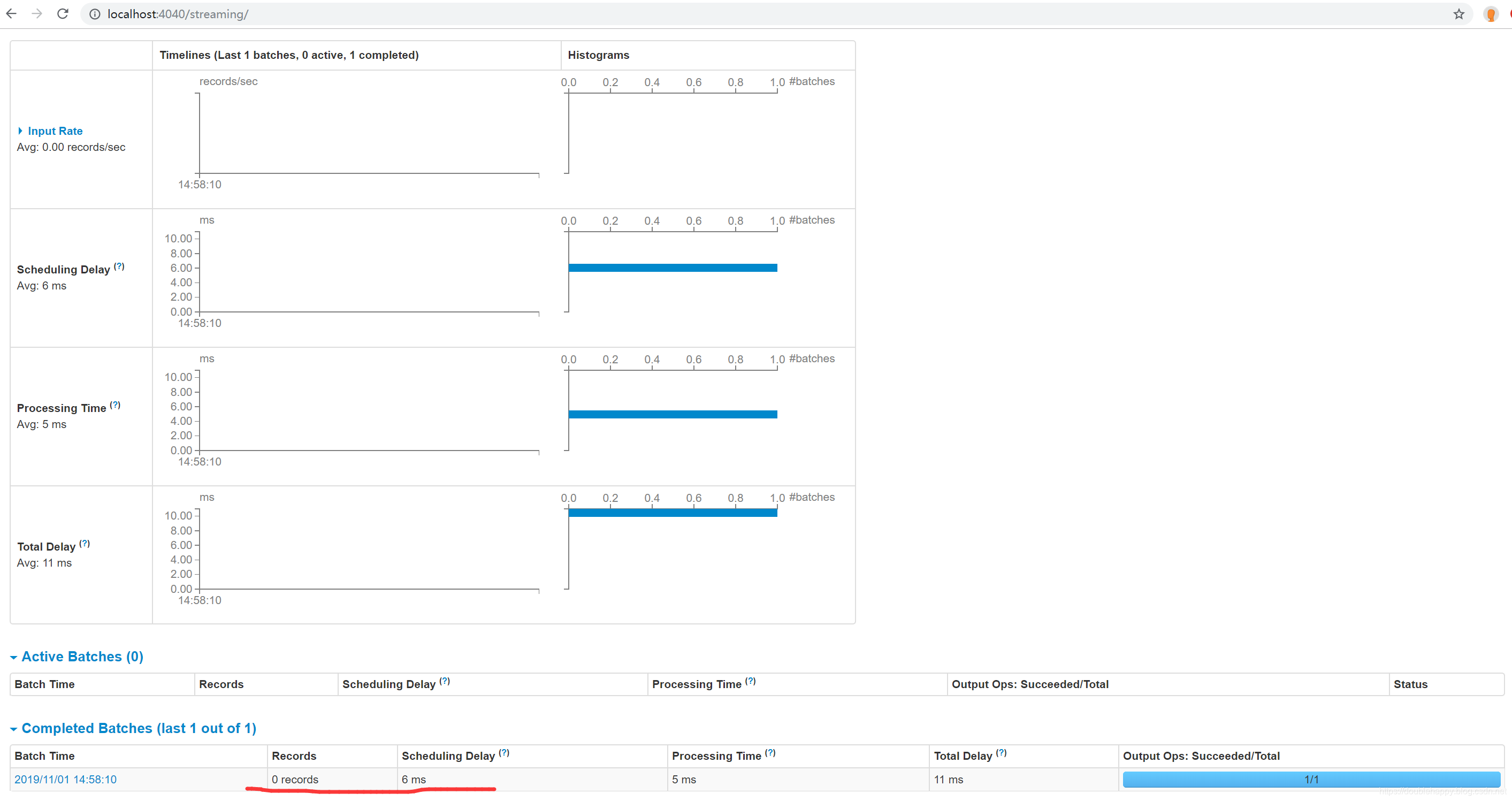
1 | 数据是0 对吧 因为数据已经提交过了 |
However, you can commit offsets to Kafka after you know your output has been stored, using the commitAsync API. The benefit as compared to checkpoints is that Kafka is a durable store regardless of changes to your application code. However, Kafka is not transactional, so your outputs must still be idempotent.
1 | 1.你的业务逻辑完成之后再提交offset |
3.Your own data store
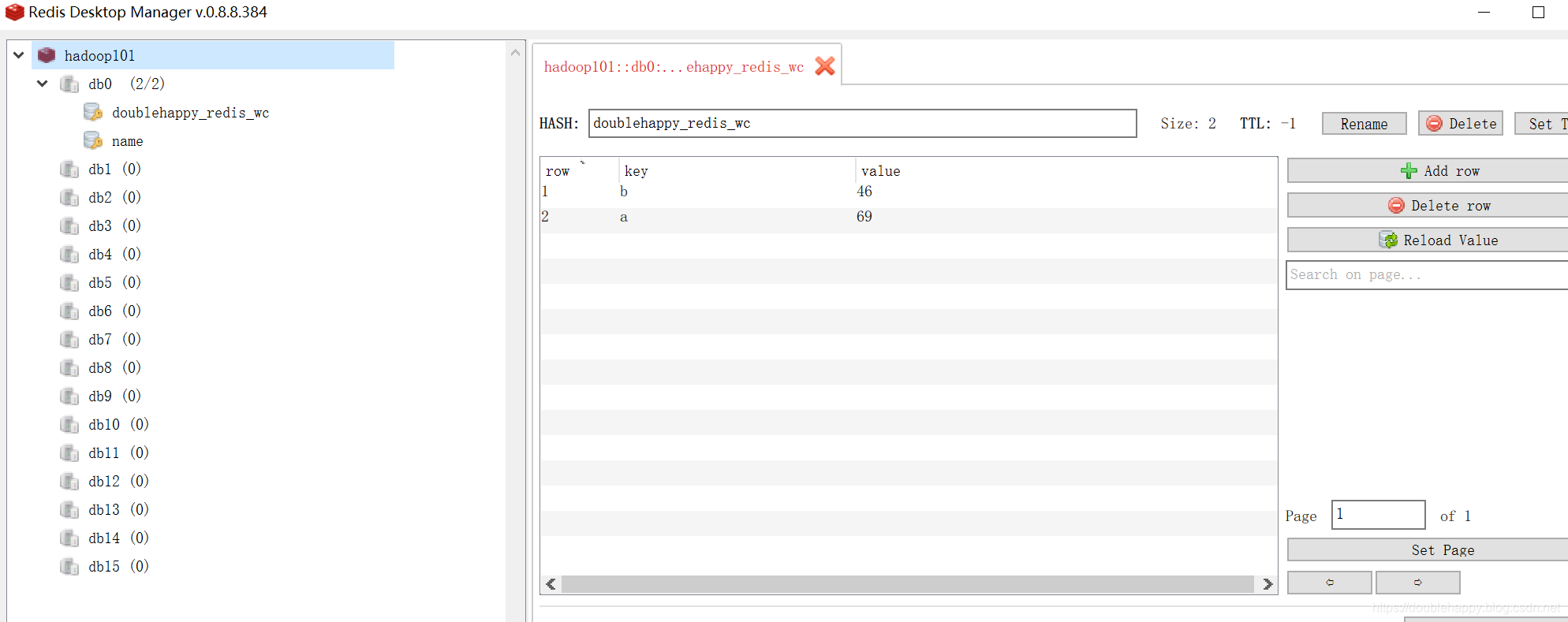
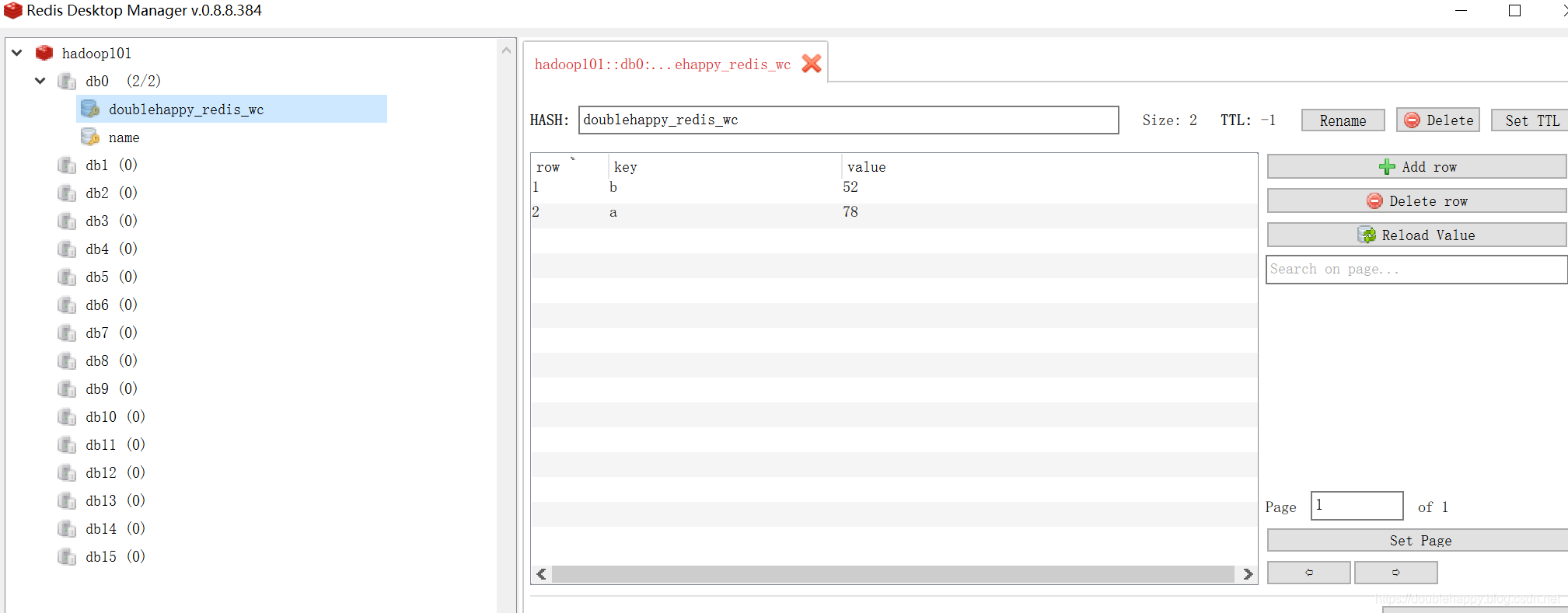
1 | 这里我使用redis 你选择MySQL也是可以的 为了测试换一个groupid 让他重新消费 |
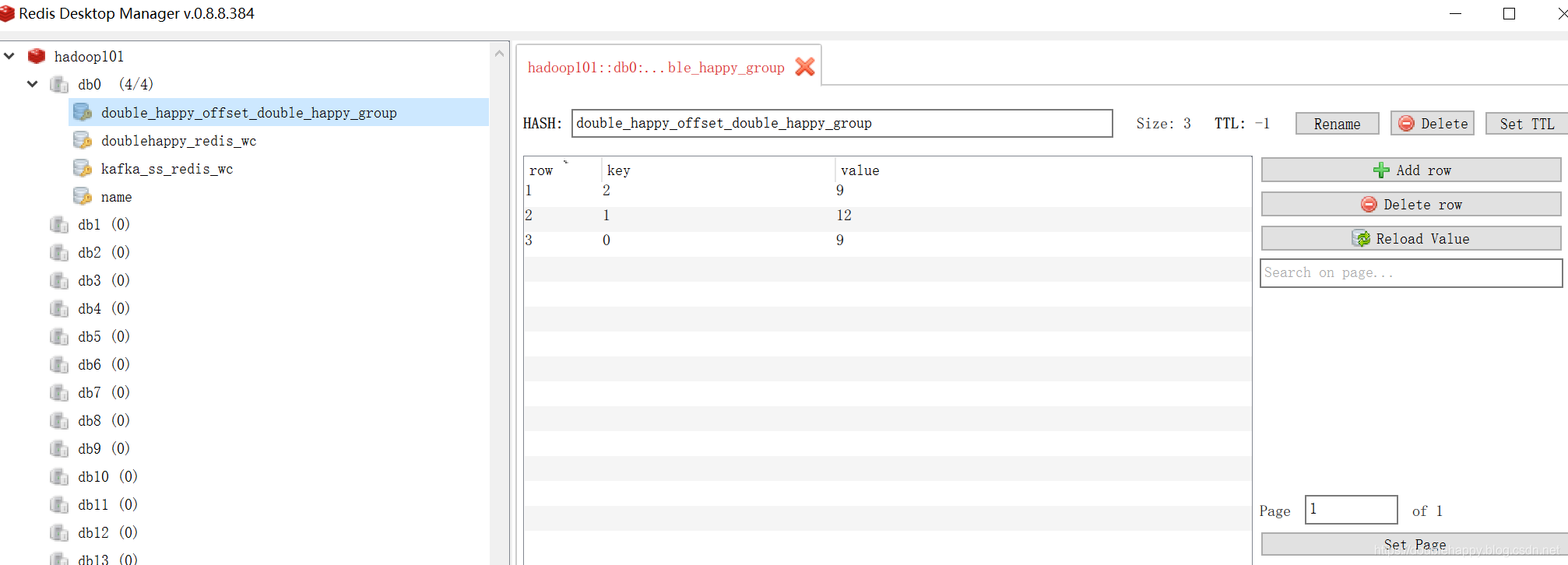
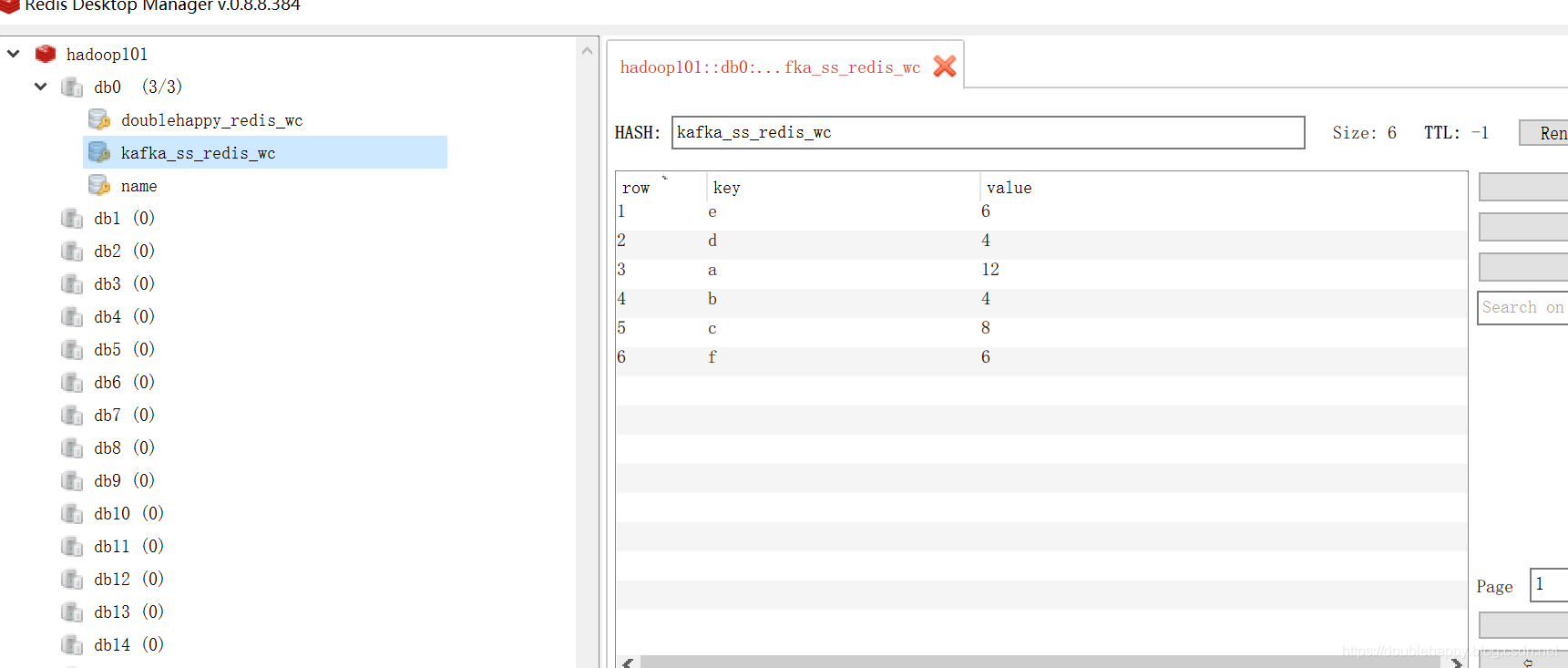
1 | 再生产一批数据 查看结果: |
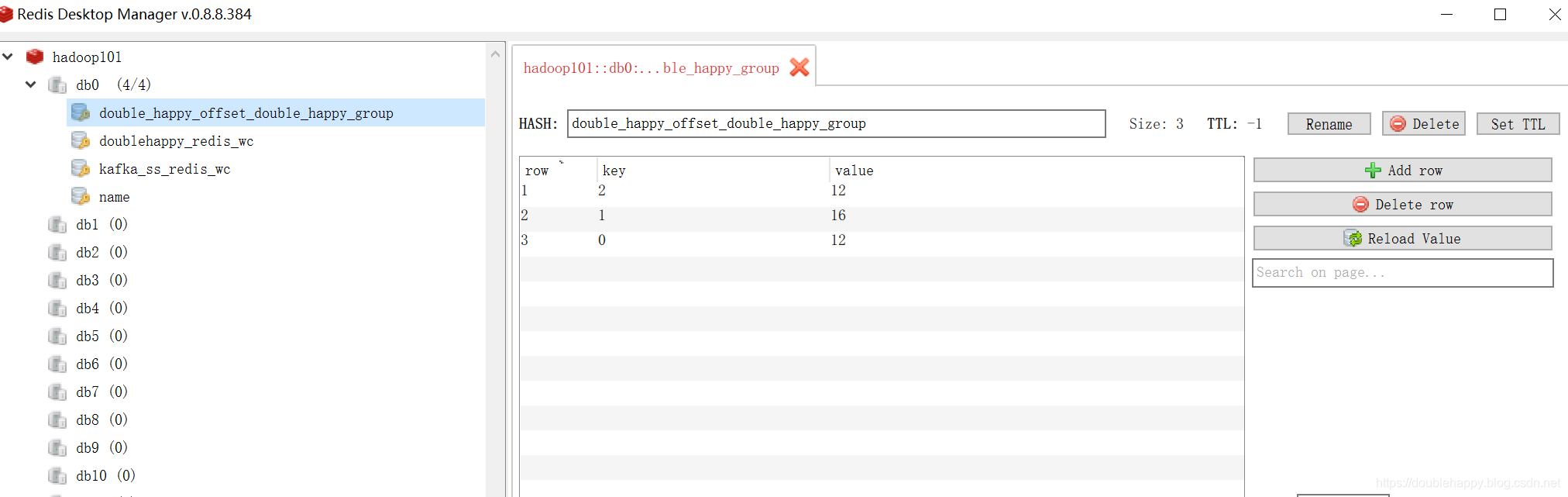
1 | 我把程序关掉 先生成两个批次的数据 再把程序打开 查看结果 |
1 | 测试:取出 offset 从redis |
1 | object RedisOffsetApp { |
1 | 所以我们再测试实时的代码 : |
1 | 总结: |
总结
1 | 1. "auto.offset.reset" -> "earliest" |
1 | updateStateByKey: |
1 | [double_happy@hadoop101 ~]$ nc -lk 9999 |
1 | object StreamingWCApp01 { |
The updateStateByKey operation allows you to maintain arbitrary state while continuously updating it with new information. To use this, you will have to do two steps.
1.Define the state - The state can be an arbitrary data type.
2.Define the state update function - Specify with a function how to update the state
using the previous state and the new values from an input stream.
In every batch, Spark will apply the state update function for all existing keys, regardless of whether they have new data in a batch or not. If the update function returns None then the key-value pair will be eliminated.
Let’s illustrate this with an example. Say you want to maintain a running count of each word seen in a text data stream. Here, the running count is the state and it is an integer. We define the update function as:
1 | updateStateByKey operation : |
案例:
1 | 1. |
1 | object StreamingWCApp01 { |
修改代码
1 | [double_happy@hadoop101 ~]$ nc -lk 9999 |
1 | object StreamingWCApp01 { |
1 | ok 现在我把程序关掉 重启以后 是多少呢? |
1 | 最好直接看官网:我只是截取我认为重要的 |
1 | object StreamingWCApp02 { |
1 | [double_happy@hadoop101 ~]$ nc -lk 9999 |
1 | 结果: |
1 | Stream + Kafka == CP |
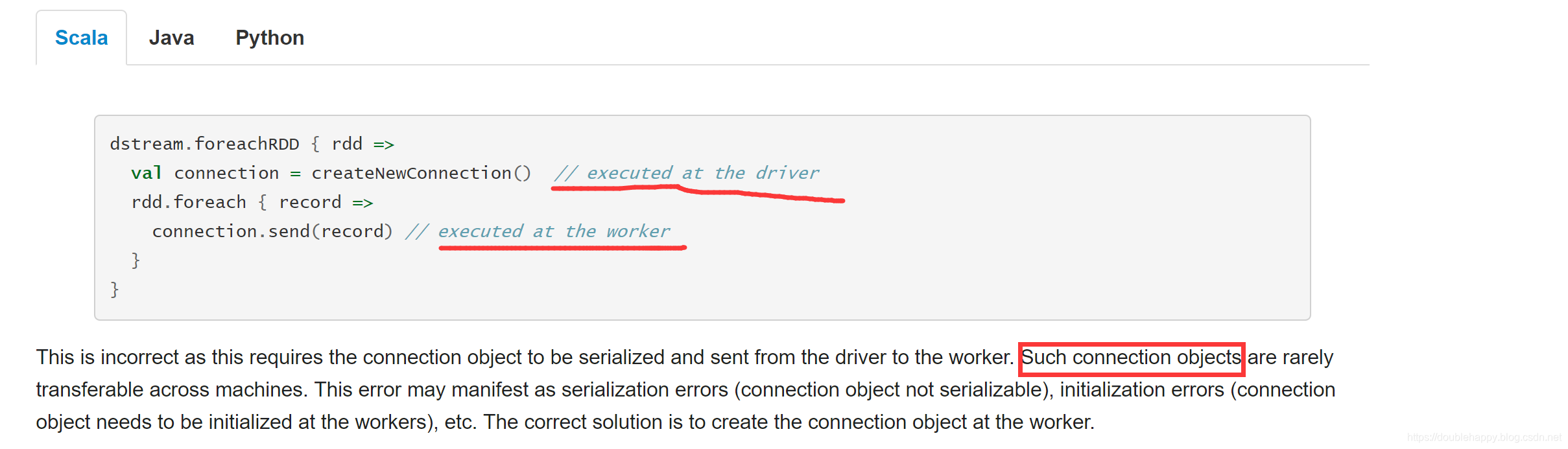
把数据写出去: ****
1 | foreachRDD: |
把数据写到MySQL
1 | MySQL底层引擎有几种?各自什么区别? |
咱们一步一步来 由劣到优
1 | object StreamingWCApp03 { |
华丽的分割线————————————————————————————————————
1 | 上面的错误明白之后 那么什么叫做闭包? |
1 | 闭包:在函数内部 引用了一个外部的变量 |
修改:
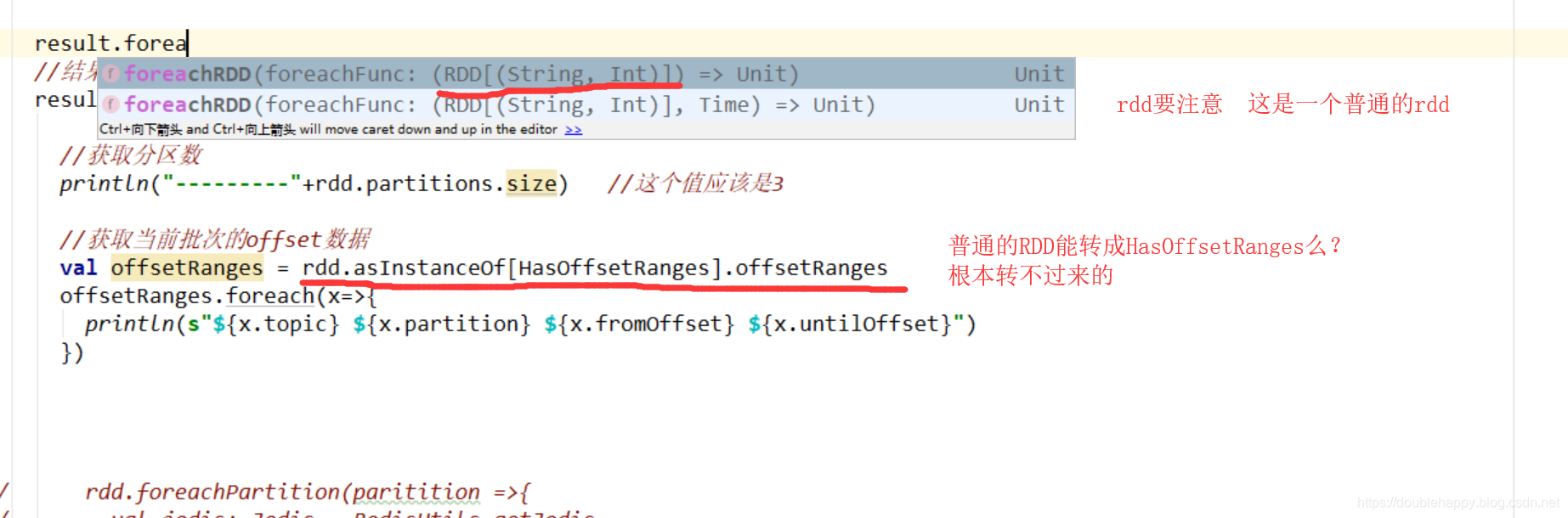
1 | result.foreachRDD( rdd =>{ |
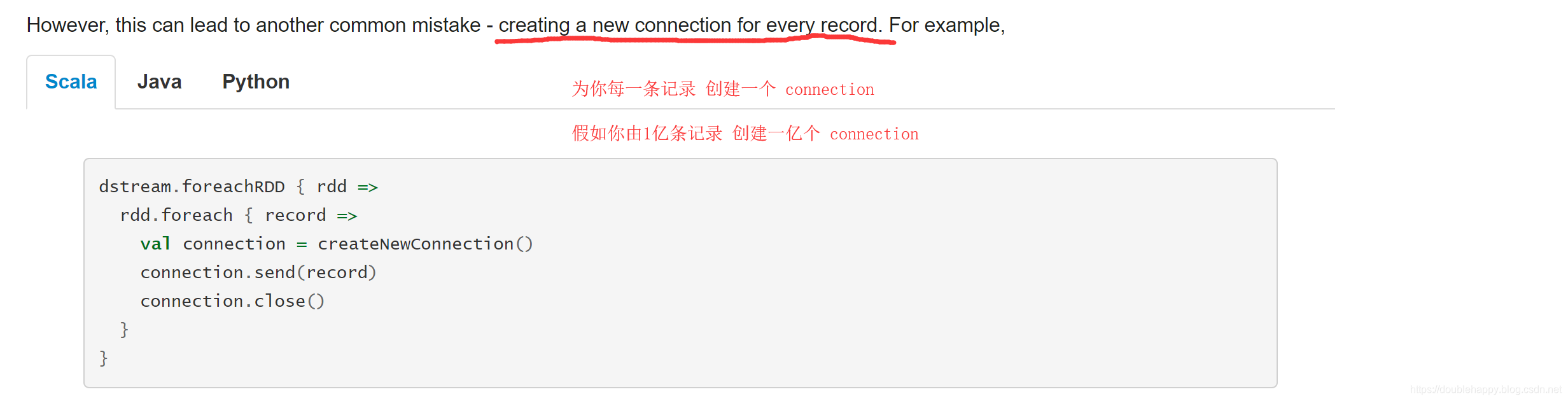
优化
1 | object StreamingWCApp03 { |
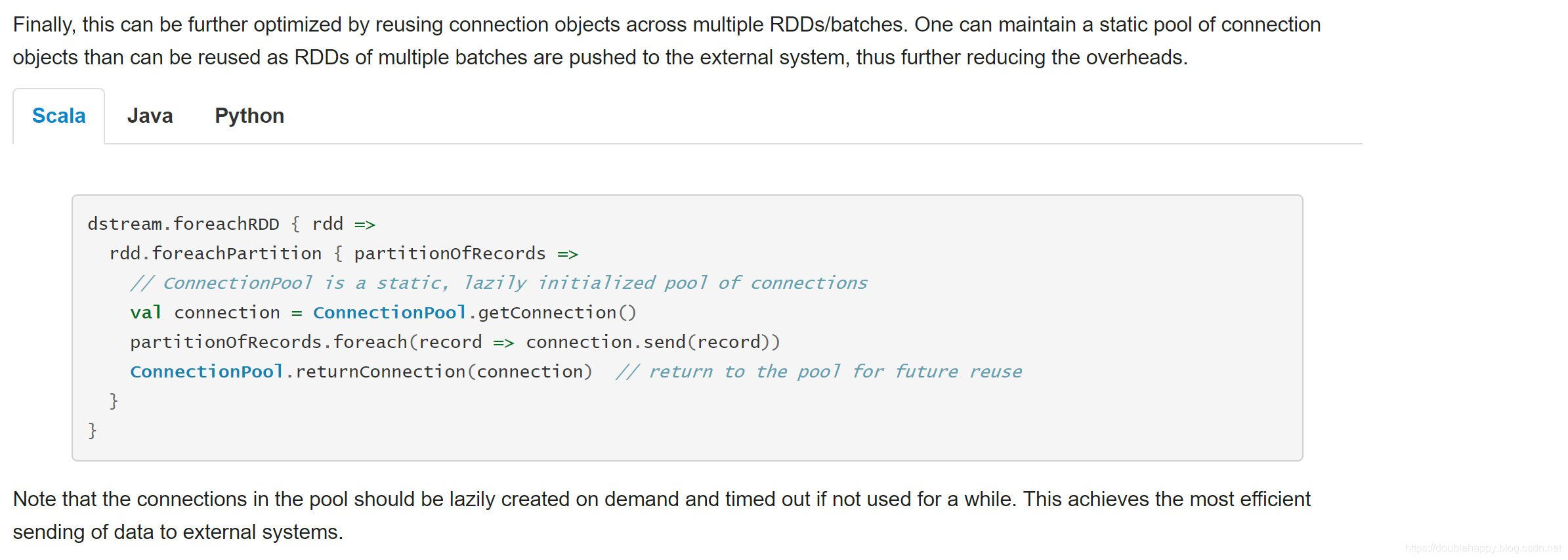
1 | 正确的写法会写了 但是 |
还有一种写法 建议使用它
scalikejdbc 自带Connection Pool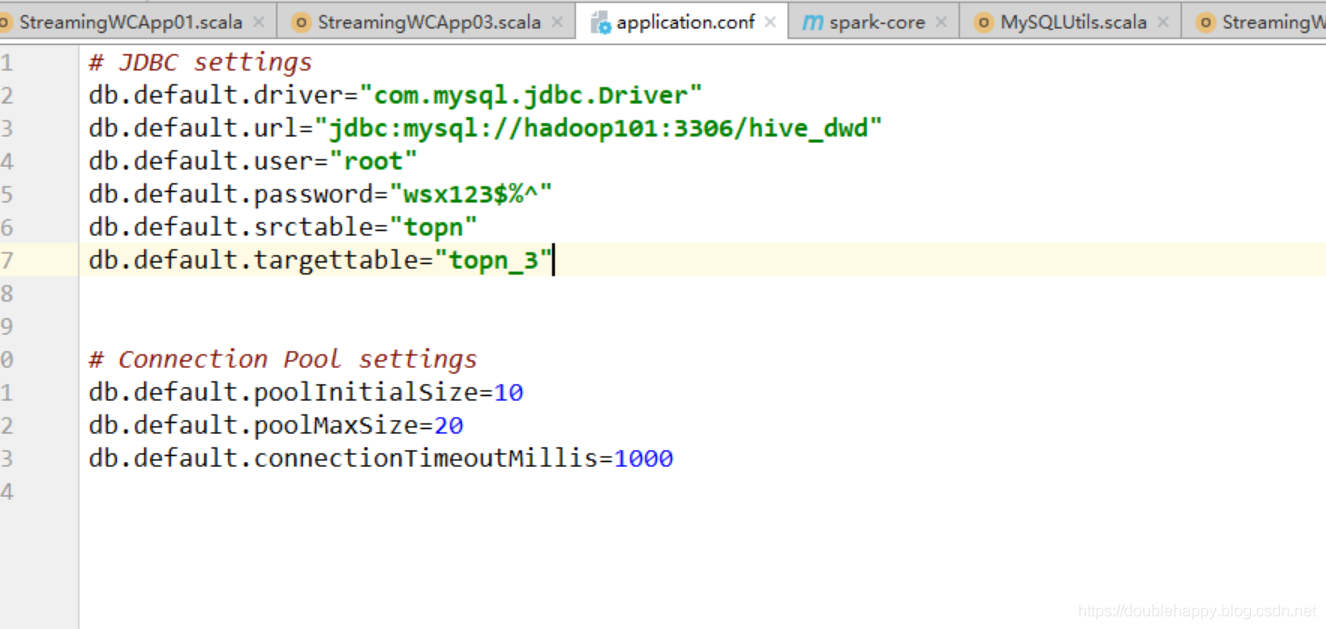
1 | object StreamingWCApp03 { |
1 | 之前 我们用state 进行累计的 |
1 | object StreamingWCApp03 { |
1 | 再放一些数据 |
说明结果ok的哈
transform
transform
1 | transform(func) ; |
例子
黑名单
目的:
只要由黑名单里的东西 把黑名单的数据全部过滤掉
1 | 先用core的方式; |
1 | ssc:很重要 |
1 | Fault Tolerance: |
1 | 流处理 |
1 | 1. Spark Streaming is an extension of the core Spark API |
1 | ss: |

1 | Spark Streaming 的编程模型: |
1 | 所以RDD算子一点要熟练掌握 |
案列代码准备
1 |
|
1 | 封装一个工具类: |
1 | object AppName { |
案例
socket:
1 | 有三个 :用哪个呢?有什么区别呢?看下面 |
1 | 数据源:socket |
测试:
1 | [double_happy@hadoop101 ~]$ nc -lk 9999 |
1 | object StreamingWCApp01 { |
1 | [double_happy@hadoop101 ~]$ nc -lk 9999 |
1 | After a context is defined, you have to do the following. |
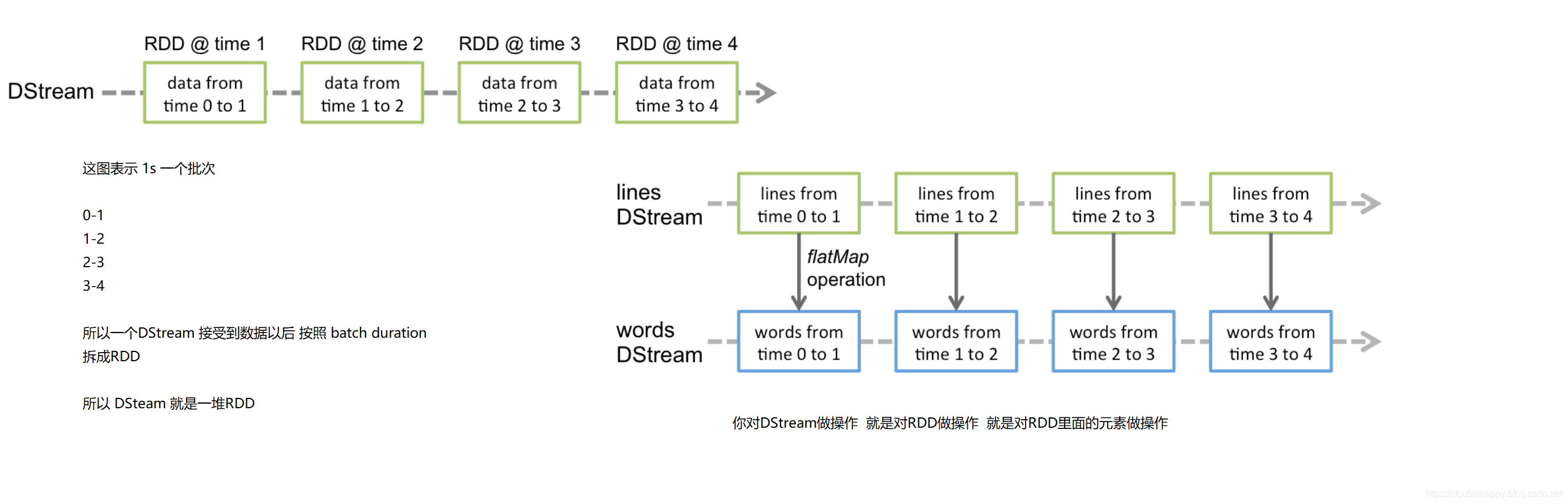
1 | 上面案例讲解: |
Input DStreams are DStreams representing the stream of input data received from streaming sources. In the quick example, lines was an input DStream as it represented the stream of data received from the netcat server. Every input DStream (except file stream, discussed later in this section) is associated with a Receiver (Scala doc, Java doc) object which receives the data from a source and stores it in Spark’s memory for processing.
1 | 1. lines was an input DStream |

1 | where > n 因为 有些业务是需要多个流处理的 |
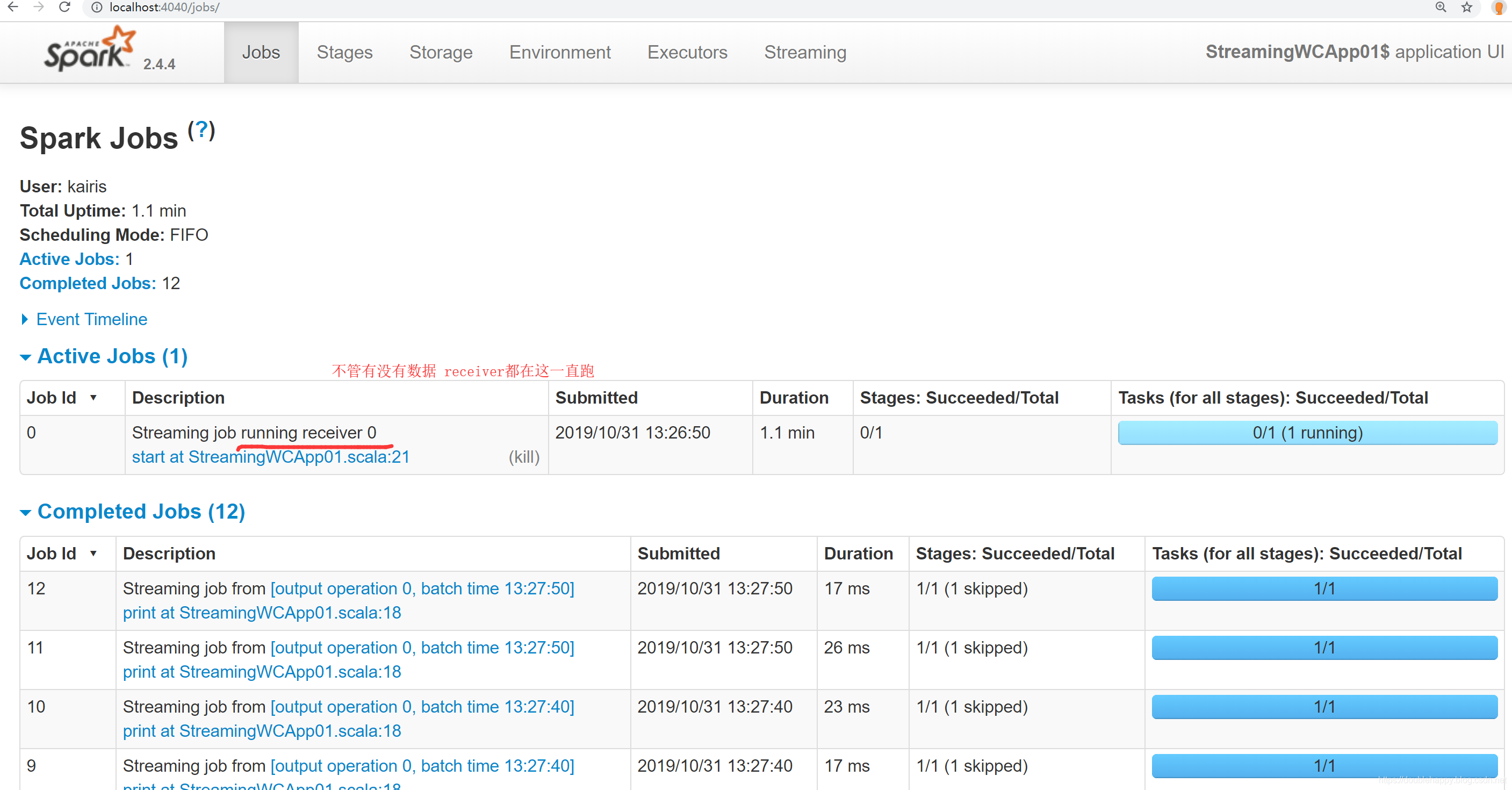
1 | active job : receiver 是接收数据用的 一直在跑 |
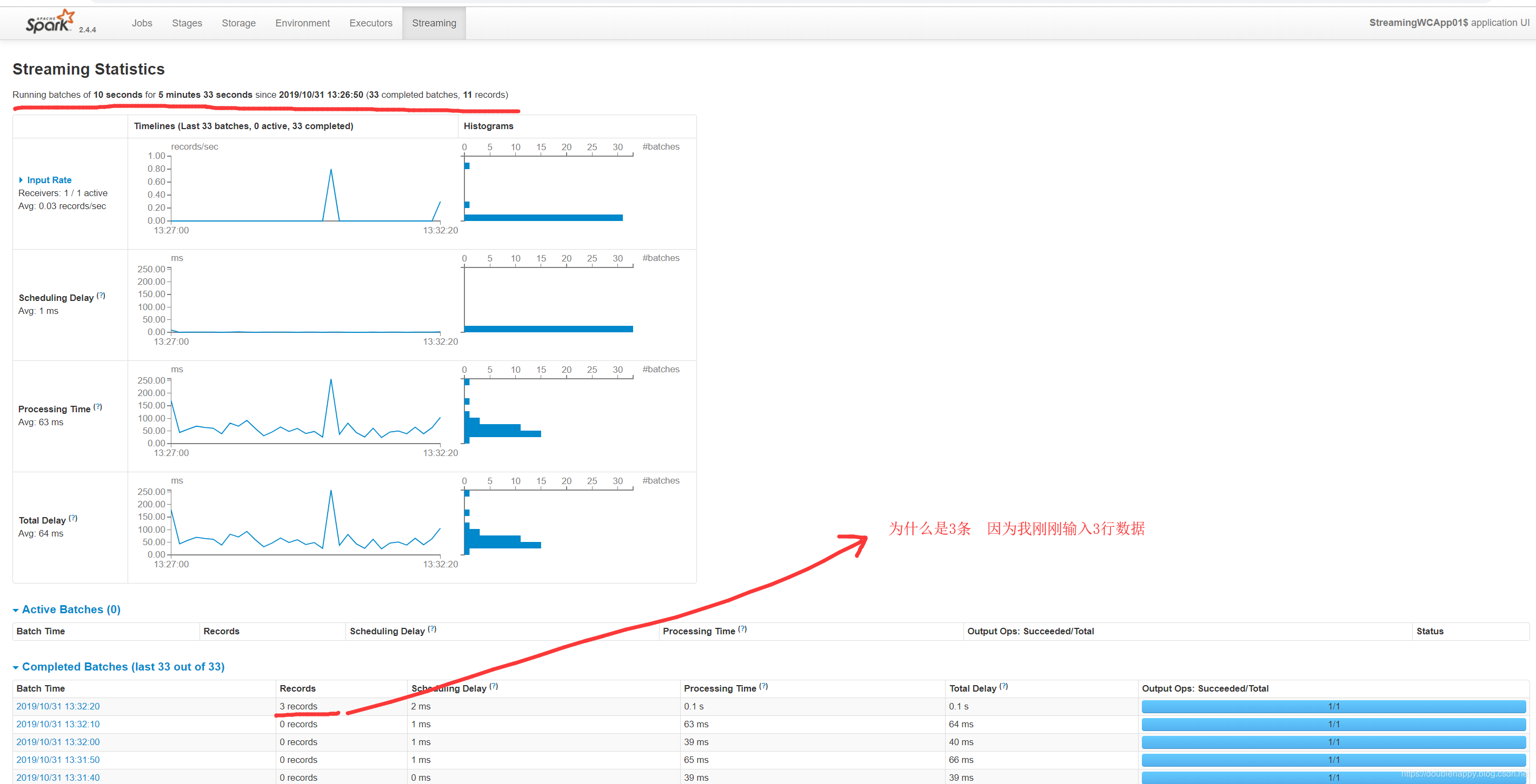
1 | 这幅图 调优的时候详细讲解 |
*操作讲解 *
Transformations on DStreams
只有最后两个和RDD算子不一样 其他的都一样
1 | [double_happy@hadoop101 ~]$ nc -lk 9999 |
1 | object StreamingWCApp01 { |
1 | [double_happy@hadoop101 ~]$ nc -lk 9999 |
1 | object StreamingWCApp01 { |
1 | /** |
1 | Spark Streaming provides two categories of built-in streaming sources. |
1 | 流处理系统 一般对接的是 kafka 读文件用的少 |
1 | 1.发布和订阅 |
1 | 1.发布和订阅 |
CDK:
CDK官网
1 | CDH版本的Kafka :Kafka是需要自定义部署的 |

1 | Kafka的版本的选择 要基于 Spark |
1 | 这里我下载最新版本 |
1 | kafka: |
启动成功
查看zk:
1 | [zk: localhost:2181(CONNECTED) 4] ls / |
1 | [double_happy@hadoop101 kafka]$ jps |
Kafka概念:
1 | 4.几个概念 |
1 | 常用命令: |
1 | 1.创建topic |
华丽的分割线—————————————————————————————————————————–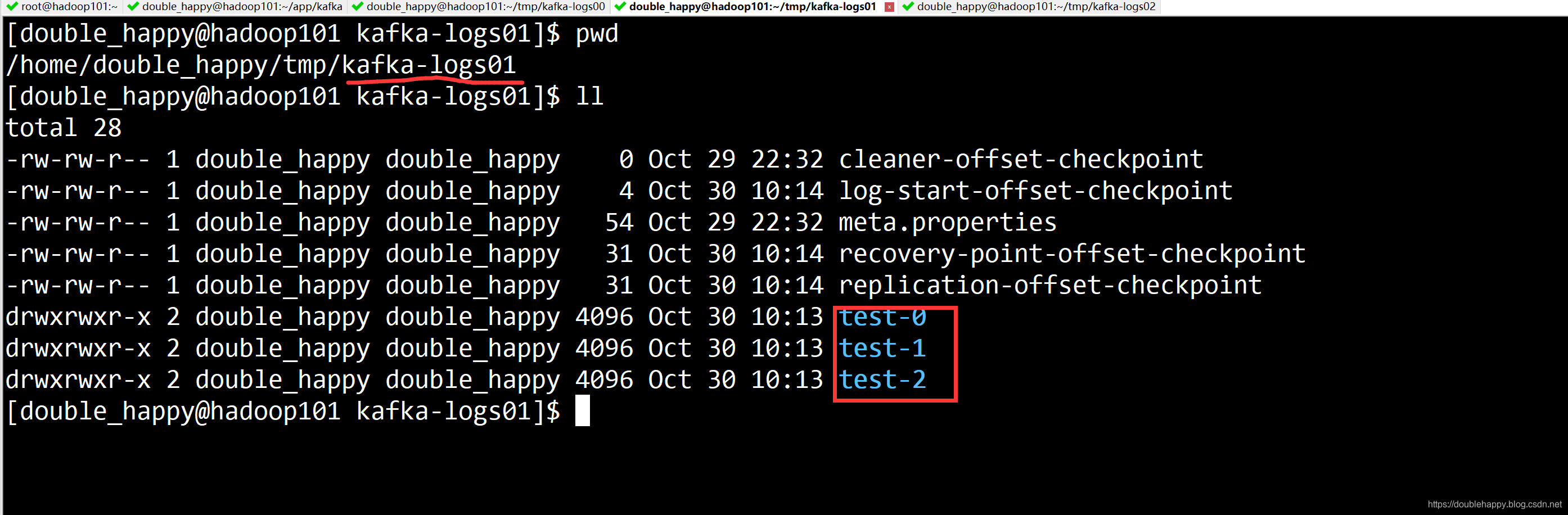
华丽的分割线—————————————————————————————————————————–
华丽的分割线—————————————————————————————————————————–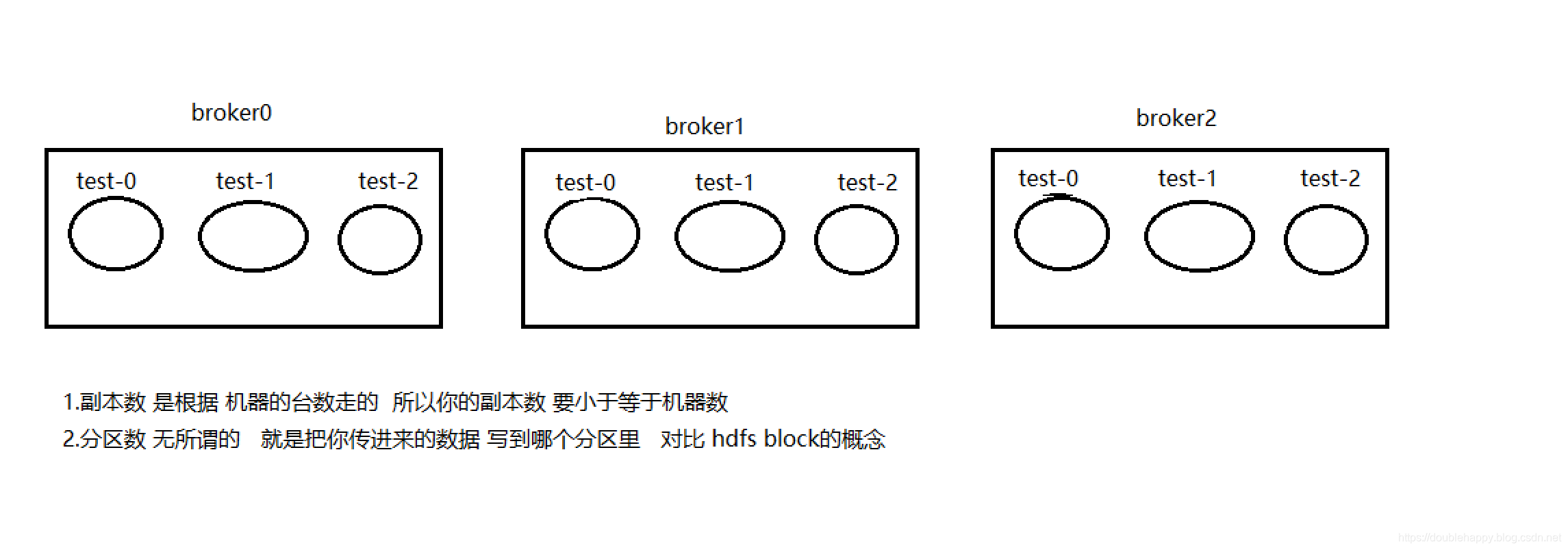
华丽的分割线—————————————————————————————————————————–
1 | 注意: |
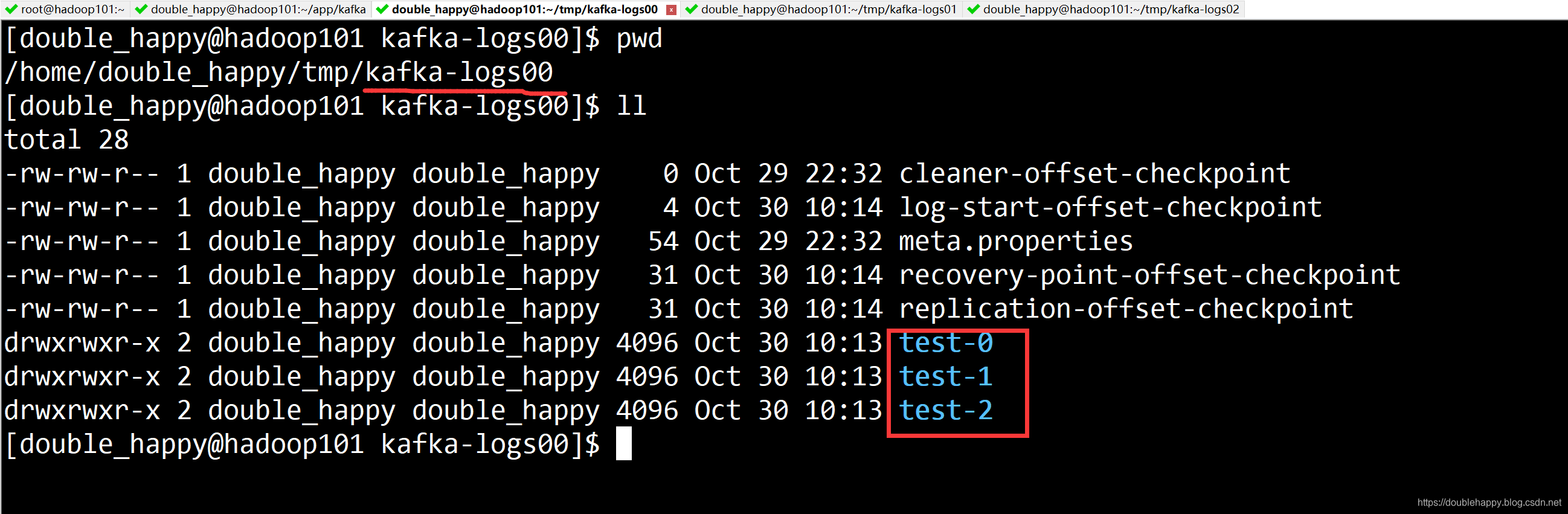
1 | 2.查看我们的topic : 查看我当前的kafka集群有多少个Topic |
1 | 3.查看 topic 明细 *** |
1 | 测试:isr |
1 | 很巧 瞎kill一个真的把 1 broker kill掉了 |
1 | 重启 broker 1 : |
1 | 4.删除 Topic |
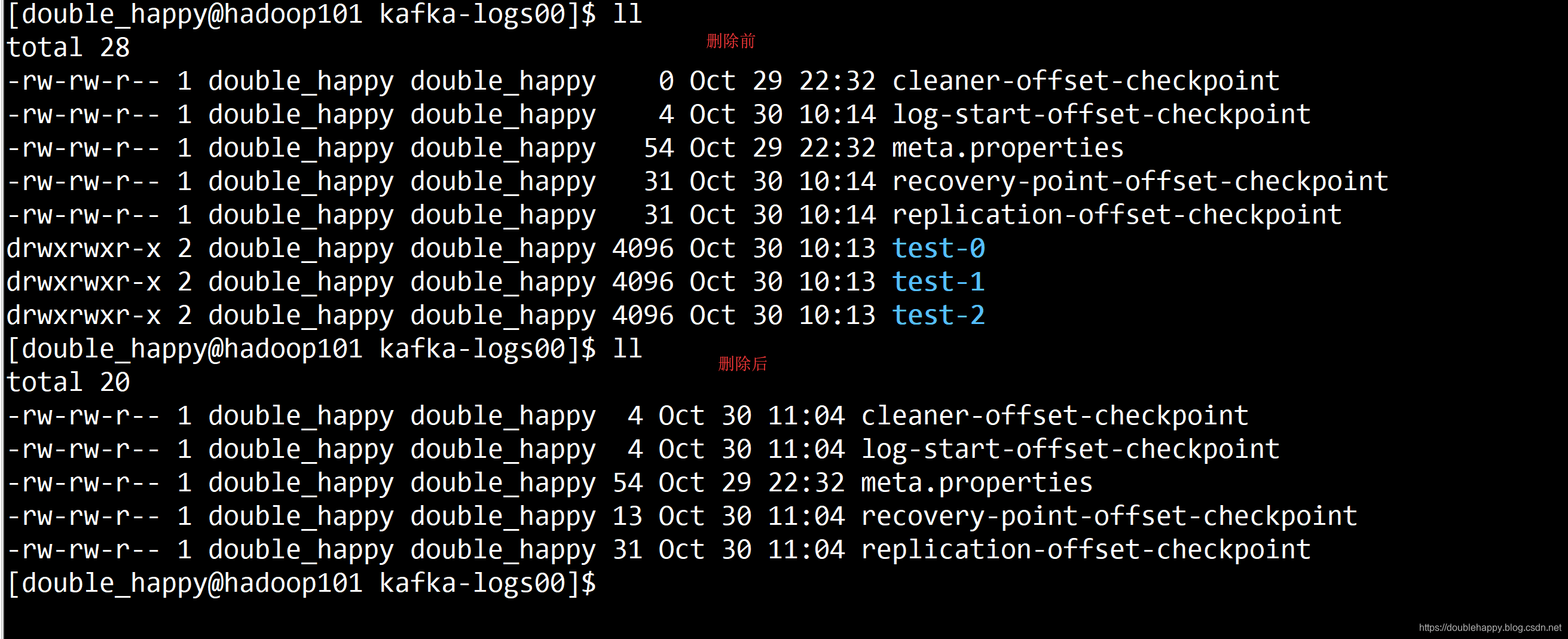
1 | 正常应该由 delete 标识的 等重启Kafak之后 会彻底删除 delete 标识的文件夹 |

1 | 我想总结的是这个 删除topic 可能会导致kafka故障? |
1 | [zk: localhost:2181(CONNECTED) 0] ls / |
1 | 5..修改topic |
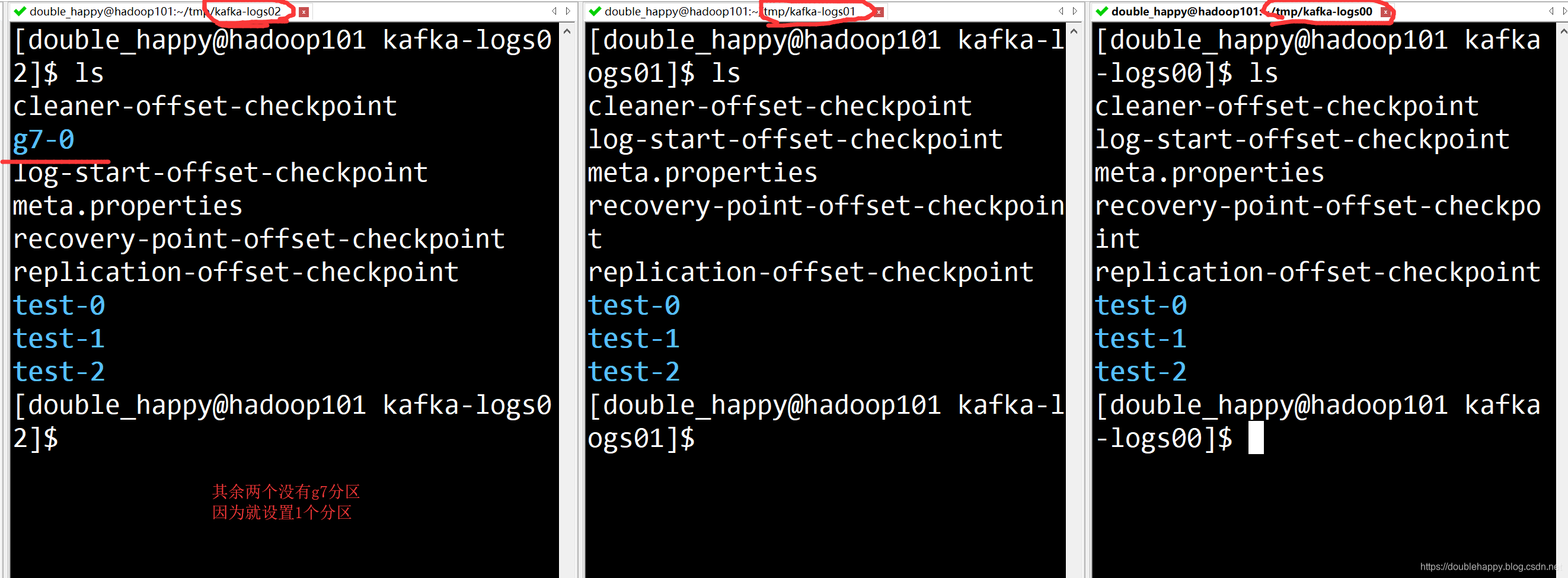
华丽的分割线————————————————————————————————————
添加分区之后: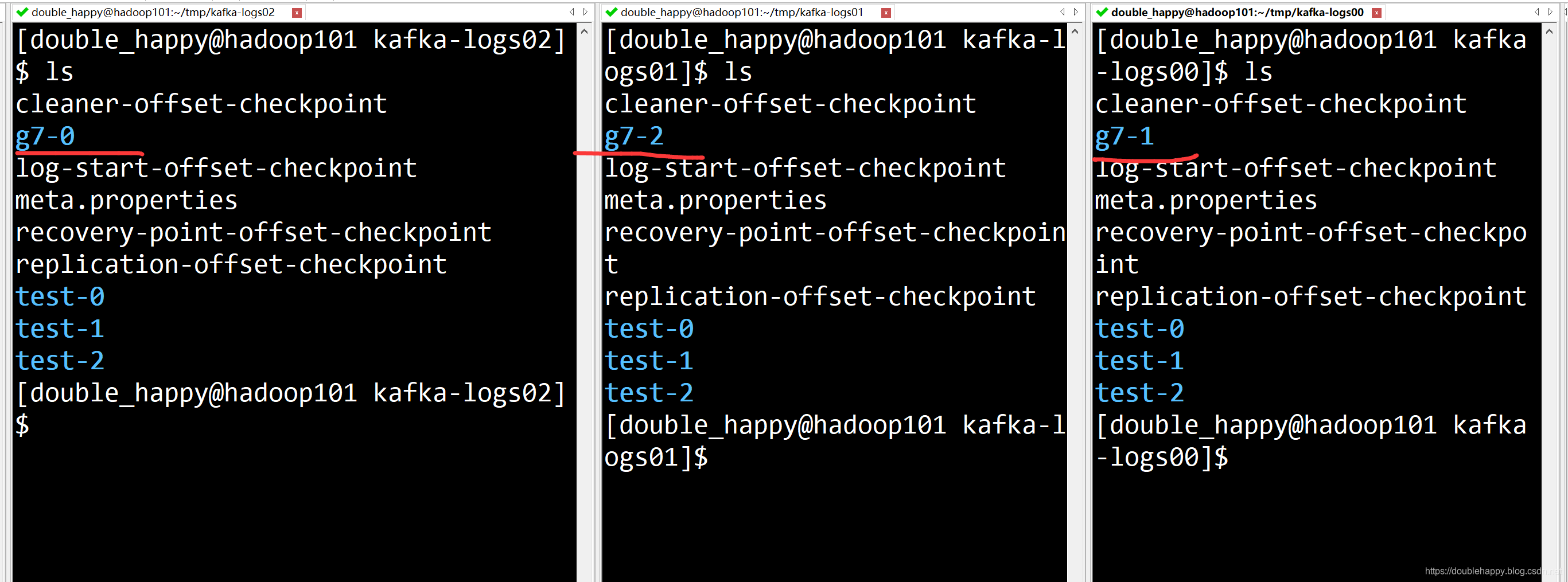
1 | 没有 g7-1 g7-2 |
1 | 查看明细: |
1 | 6.自动迁移数据到 新的节点 : |
1 | 1. kafka-reassign-partitions.sh 使用这个脚本 |

1 | 工作时候 用的很少 一般都是事先规划好的 机器 |
1 | 7.console案例 很简单 |
1 | 生产者: |
1 | 消费者: |
1 | 那么我把消费者 打断 重新 起来 : |
故障案例:
异构平台Kafka对接使⽤
http://blog.itpub.net/30089851/viewspace-2152671/
是NoSQL的
官网
1 | Redis: |
操作:
1 | [double_happy@hadoop101 src]$ ls redis-server |
1 | 启动: |
1 | 后台运行:需要对redis.conf 文件进行简单的配置 配置一下 logfile位置 |
1 | 客户端操作: 需要把redis.conf 里的 bind 去掉 或者 配置成 0.0.0.0 |
1 | Redis多数据库特性: |
1 | Redis 切换库 黑窗口: |
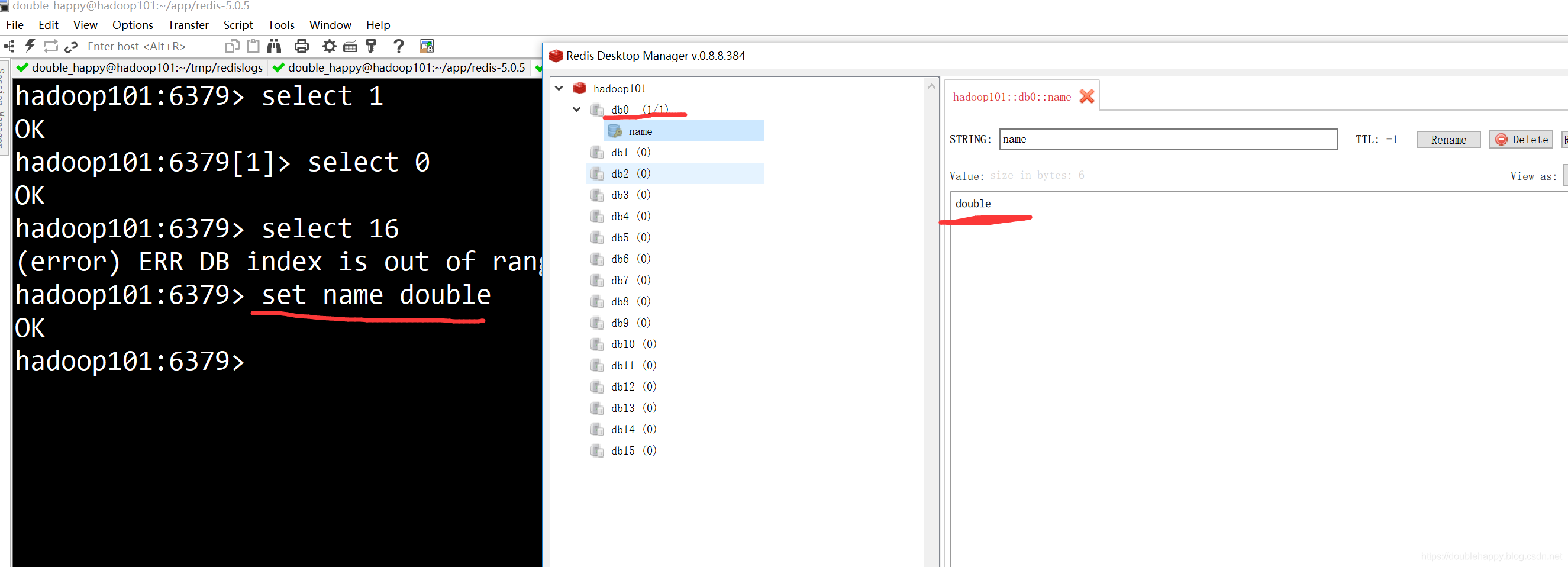
1 | 1. 通常情况下 数据库之间是 隔离的 |
1 | redis里的基础命令: |
1 | 2.判断某一个key 存不存在 |
1 | 3.删除 |
命令太多了 看官网
Commands
1 | 查看 key的类型: |
1 | 但是真的记不住怎么办? |
1 | eg: |
数据类型:
这个需要掌握的
1 | String类型: |
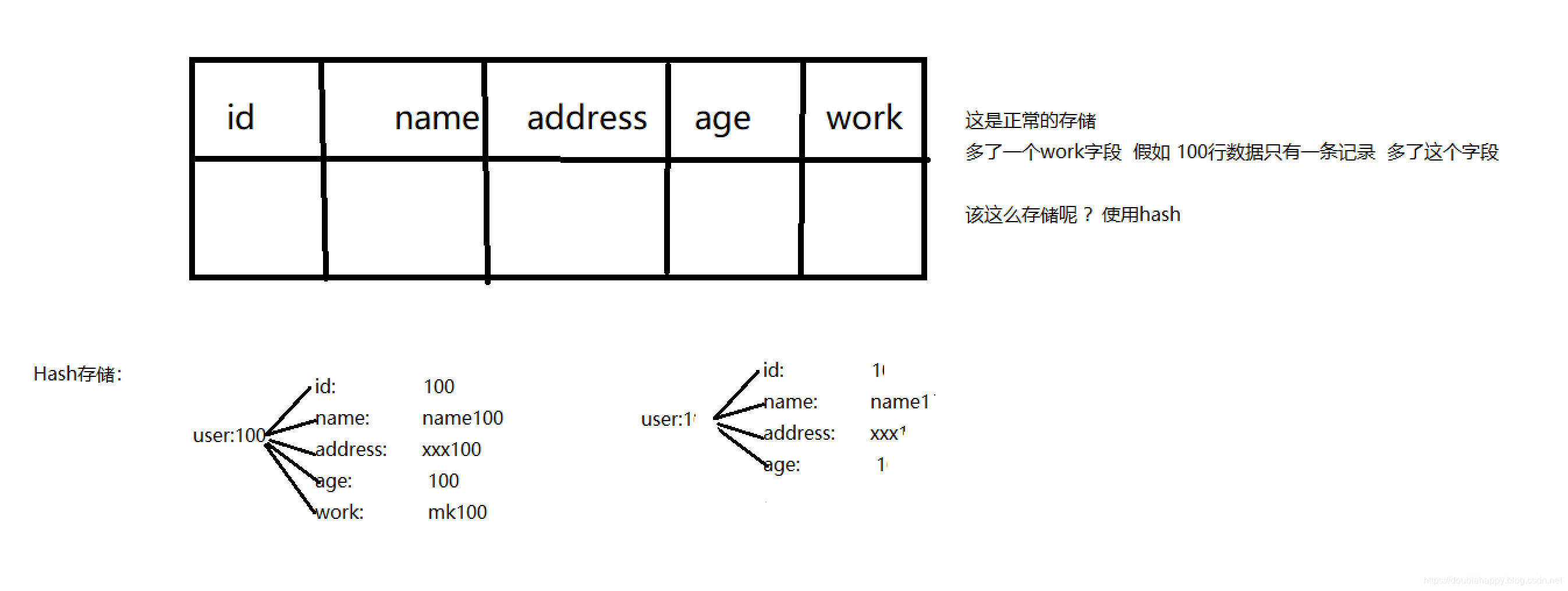
idea开发
1 | public class RedisApp { |
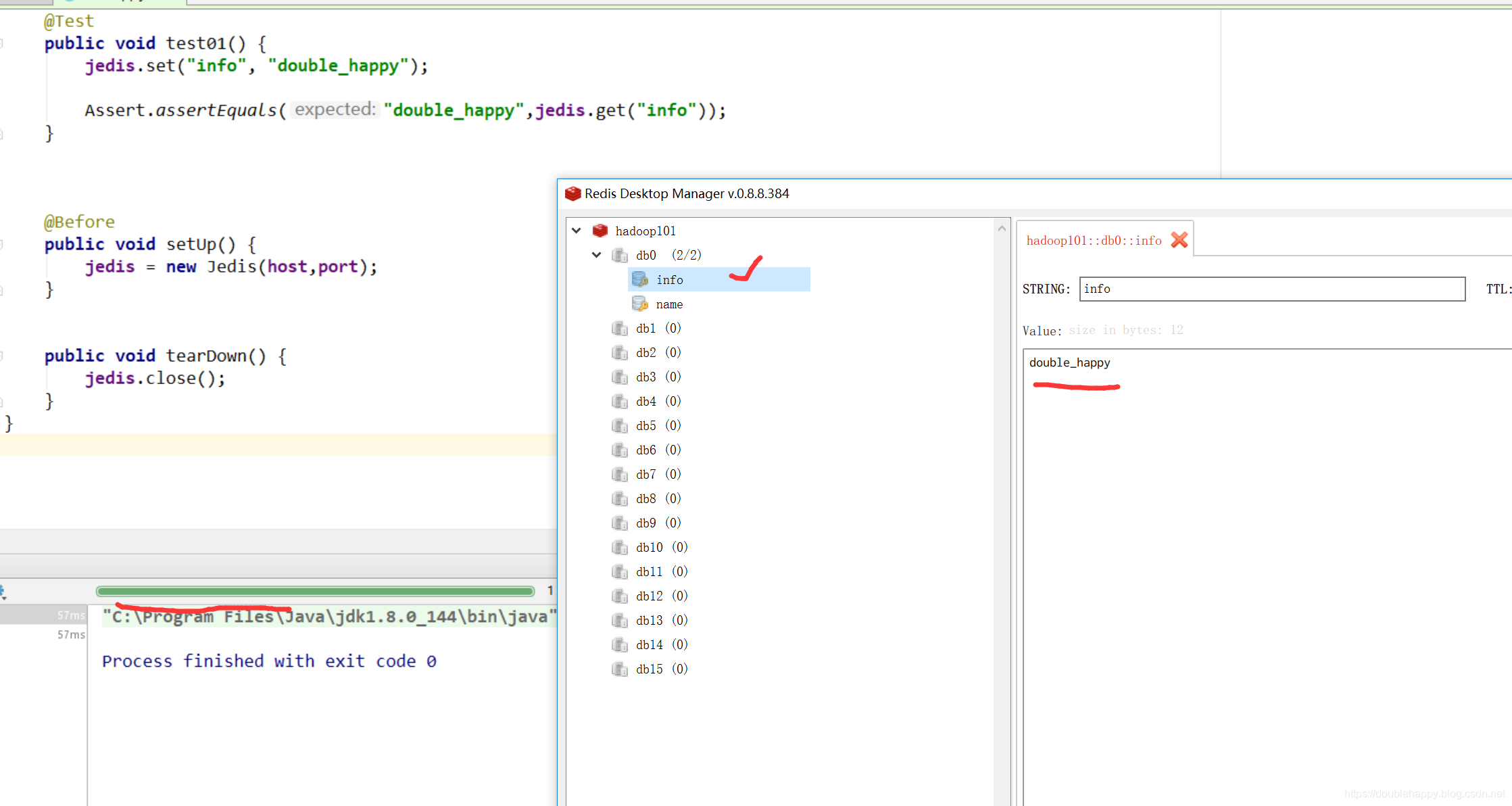
1 | 在object LogApp { |
演示上面代码可能的问题
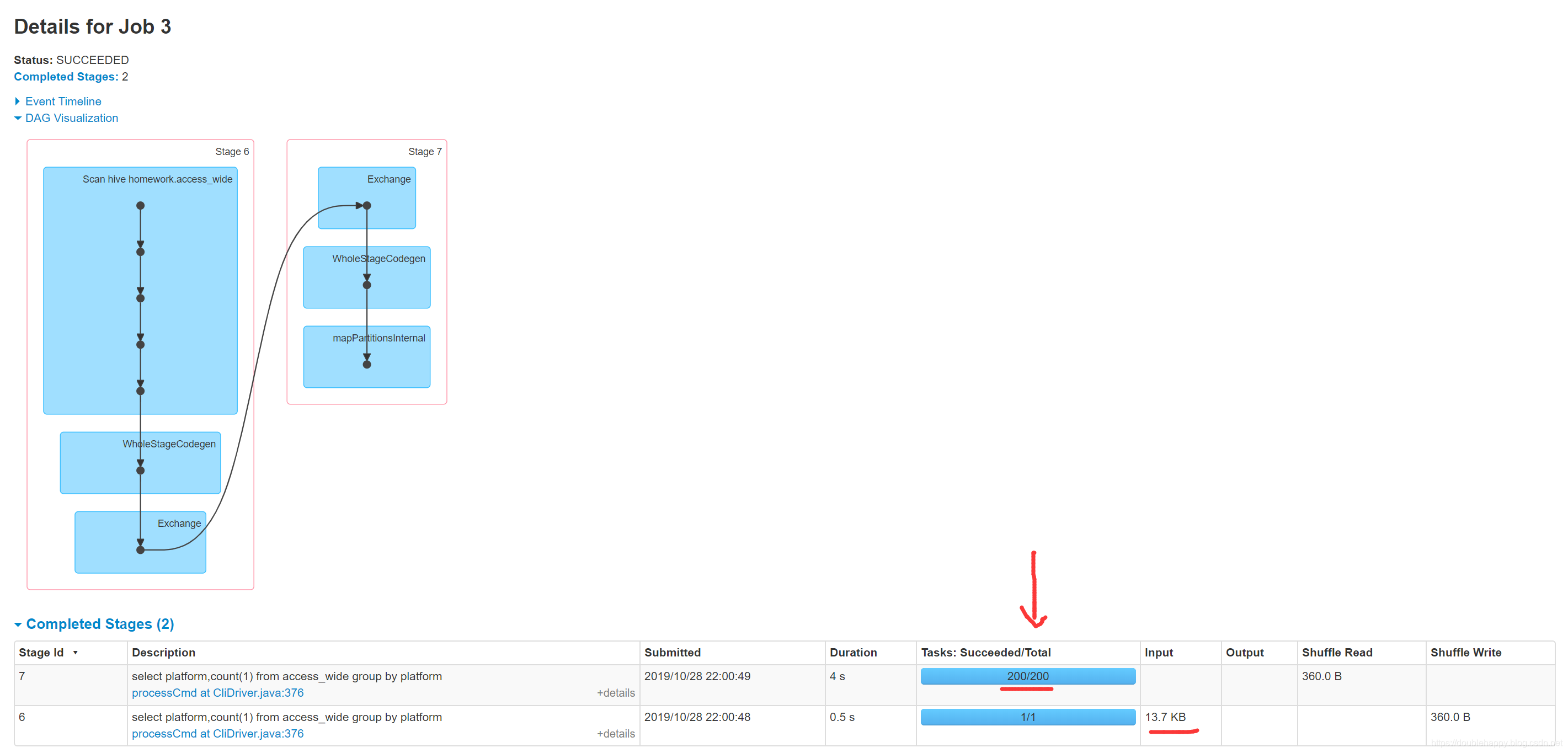
1 | 这200 哪里来的 ? |
1 | 还有一点就是: |
ETL
1 | ETL |
1 | 行式存储:MySQL |
1 | 列式:Orc Parquet |
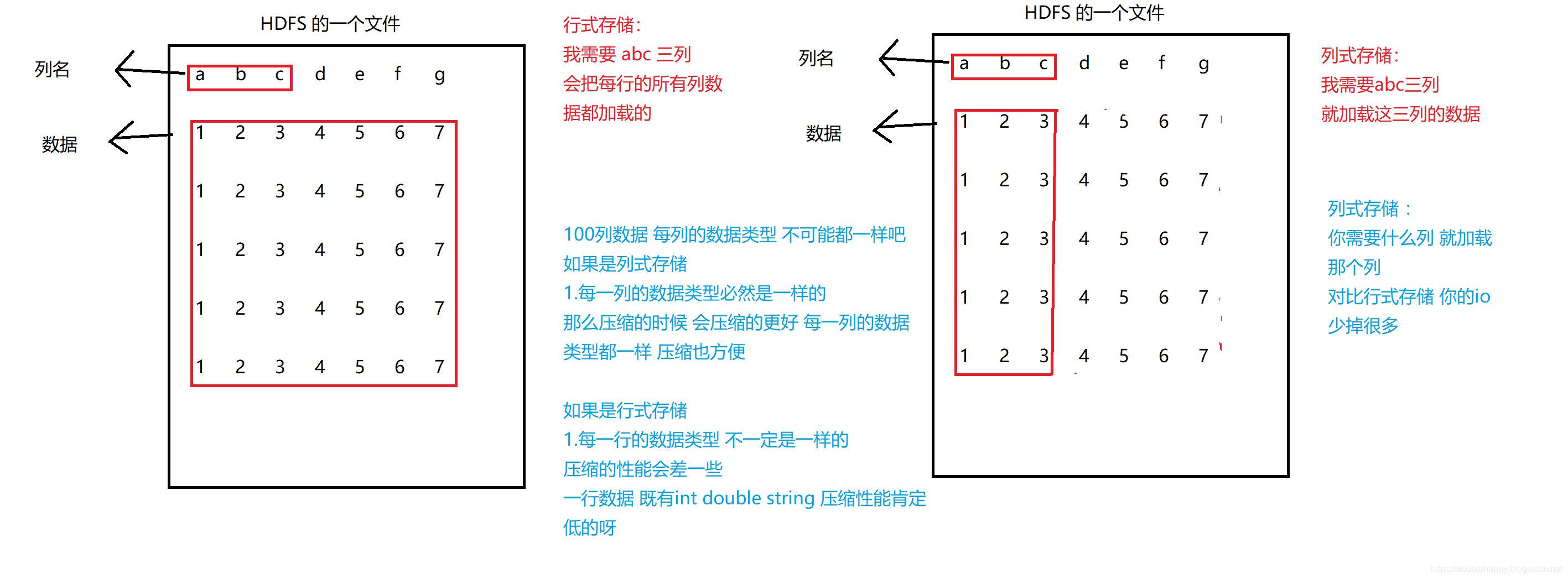
1 | 使用行式存储 spark跑程序的时候官网也列举了很多问题 |
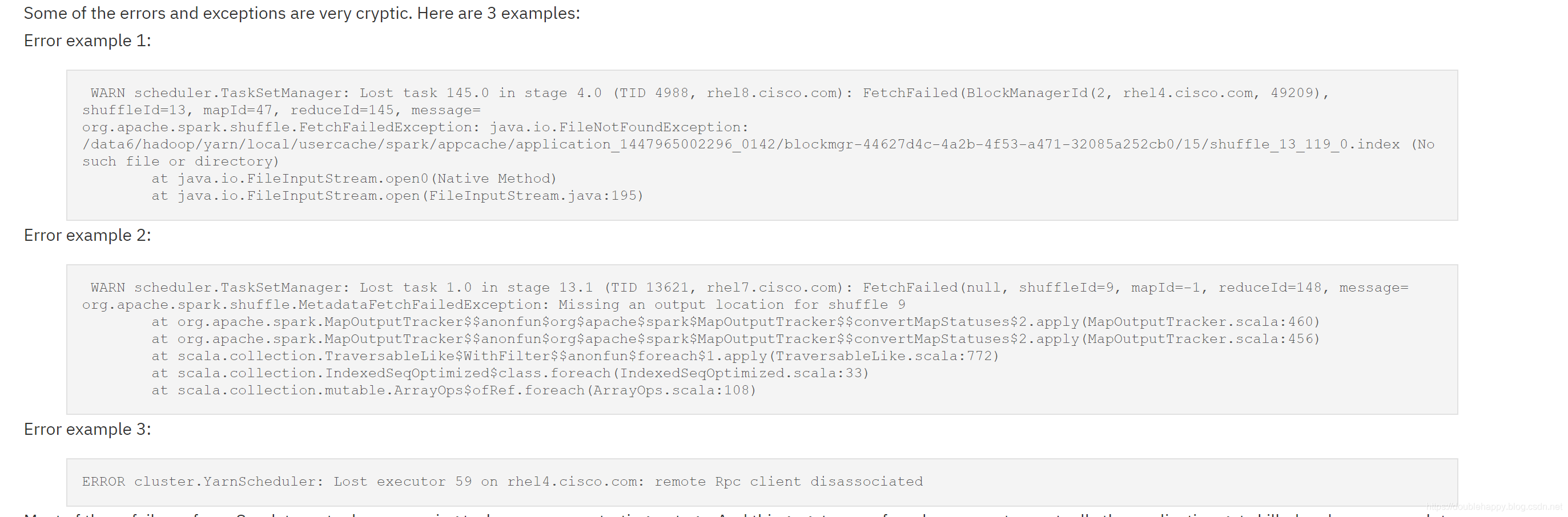
1 | 那么Most of these failures force Spark to re-try by re-queuing tasks: |
1 | 存储是结合 压缩来用的 eg:orc + lzo |
生产上是用的
1 | hiveserver2 beeline/jdbc Hive里的 |
1 | [double_happy@hadoop101 sbin]$ ./start-thriftserver.sh --jars ~/software/mysql-connector-java-5.1.47.jar |
1 | [double_happy@hadoop101 sbin]$ tail -200f /home/double_happy/app/spark/logs/spark-double_happy-org.apache.spark.sql.hive.thriftserver.HiveThriftServer2-1-hadoop101.out |
1 | 说明 thriftserver 启动起来了 |
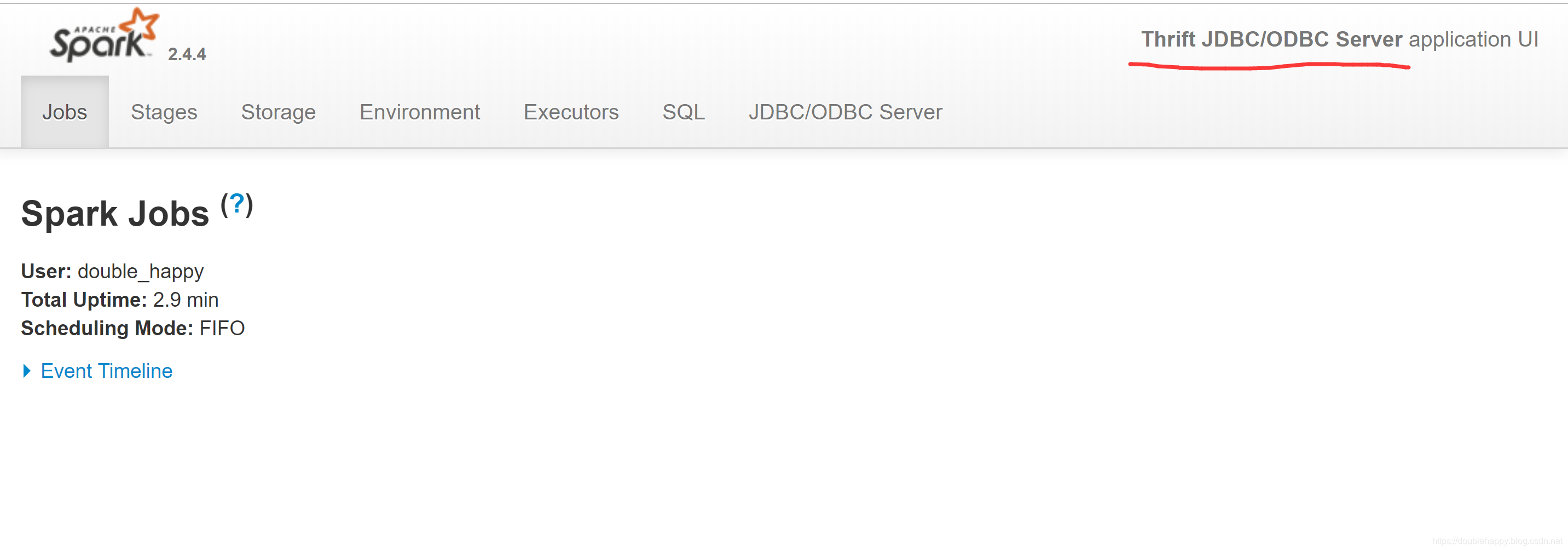
1 | 这是 thriftserver 端起来了 说明服务端有了 |
1 | [double_happy@hadoop101 bin]$ ./beeline -u jdbc:hive2://hadoop101:10000/ruozedata_g7 -n double_happy |
1 | [double_happy@hadoop101 bin]$ ./beeline -u jdbc:hive2://hadoop101:10000/homework -n double_happy |
1 | 这个东西适用在哪里呢? |
Spark On Yarn
Running Spark on YARN
There are two deploy modes that can be used to launch Spark applications on YARN. In cluster mode, the Spark driver runs inside an application master process which is managed by YARN on the cluster, and the client can go away after initiating the application. In client mode, the driver runs in the client process, and the application master is only used for requesting resources from YARN.
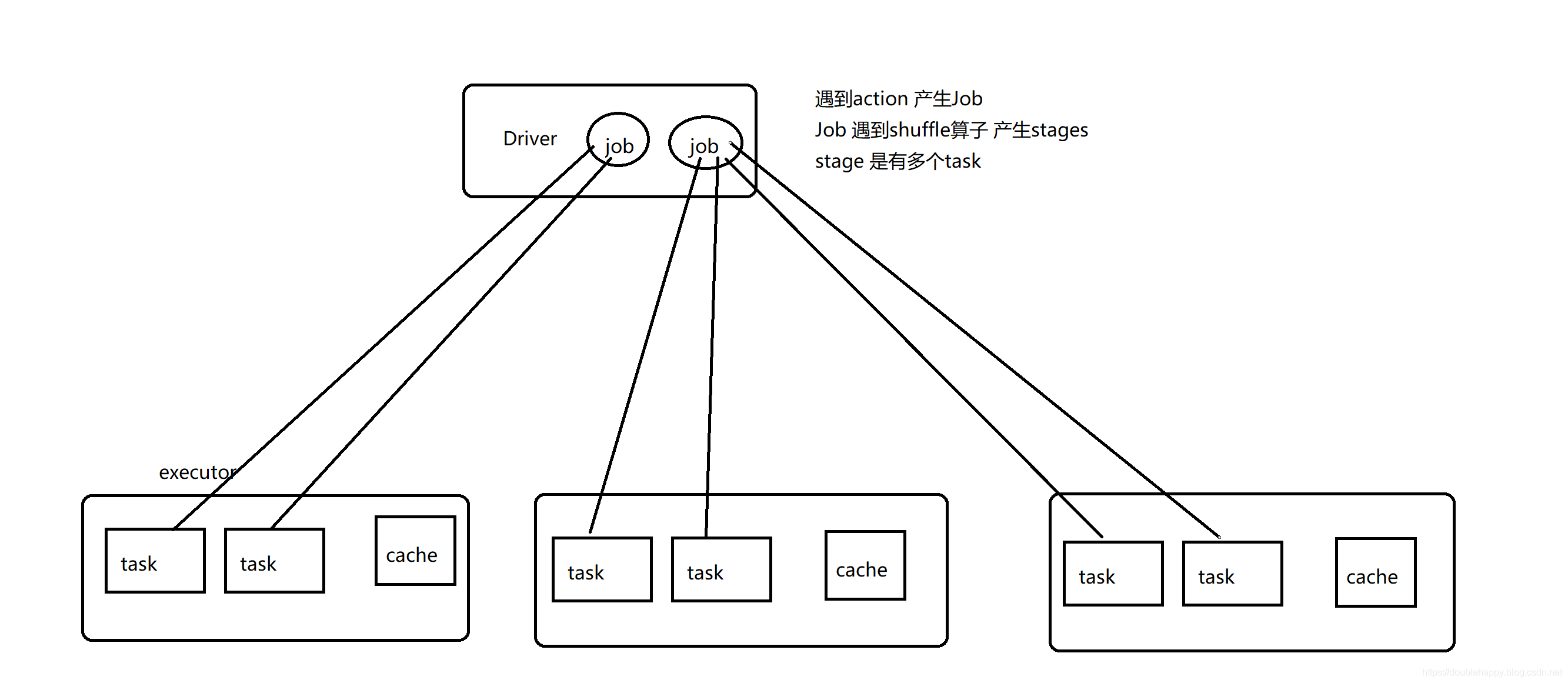
client模式:
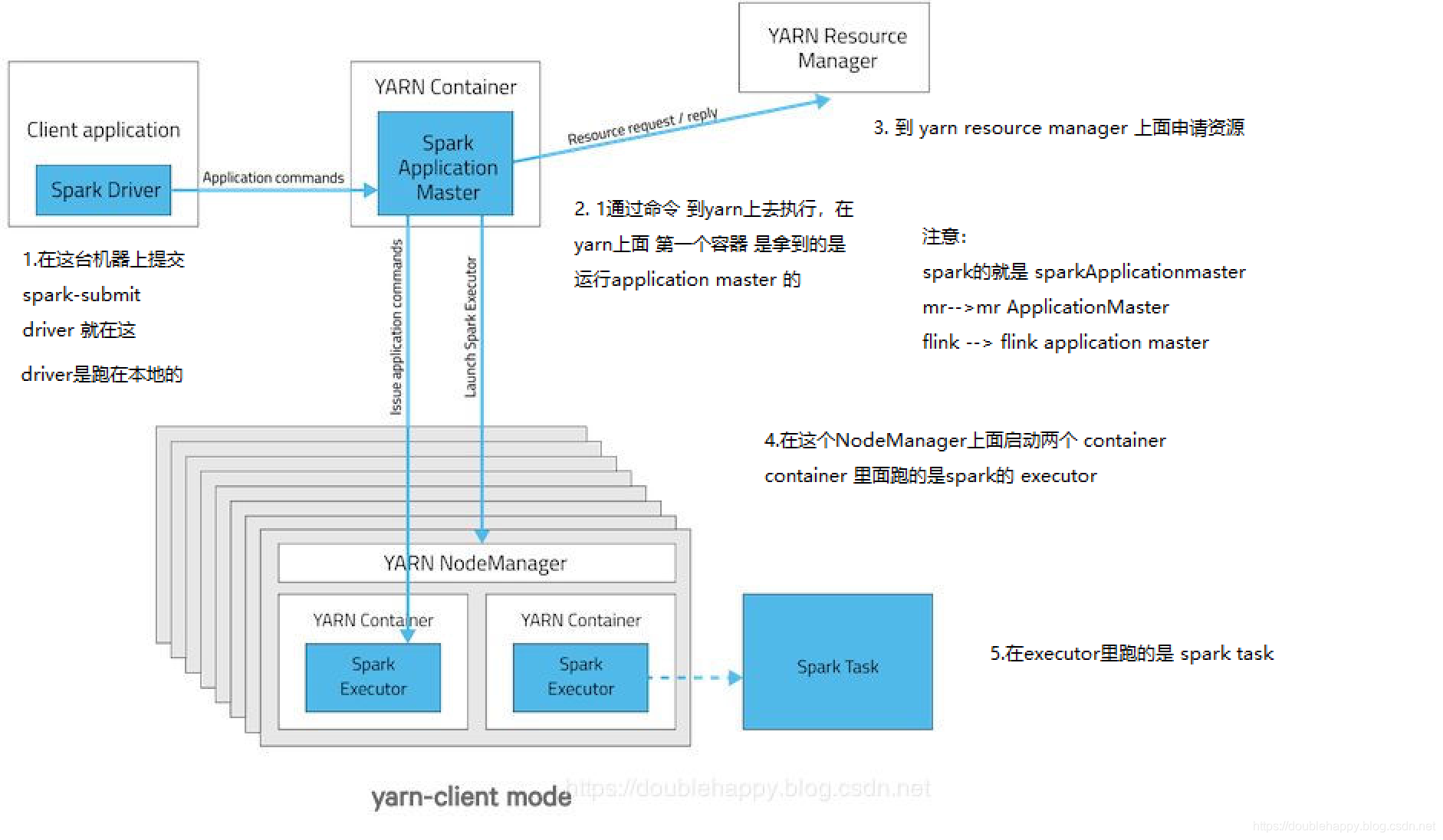
1 | 在Spark on YARN中 是没有Worker的概念,是Standalone中的 |
cluster模式:
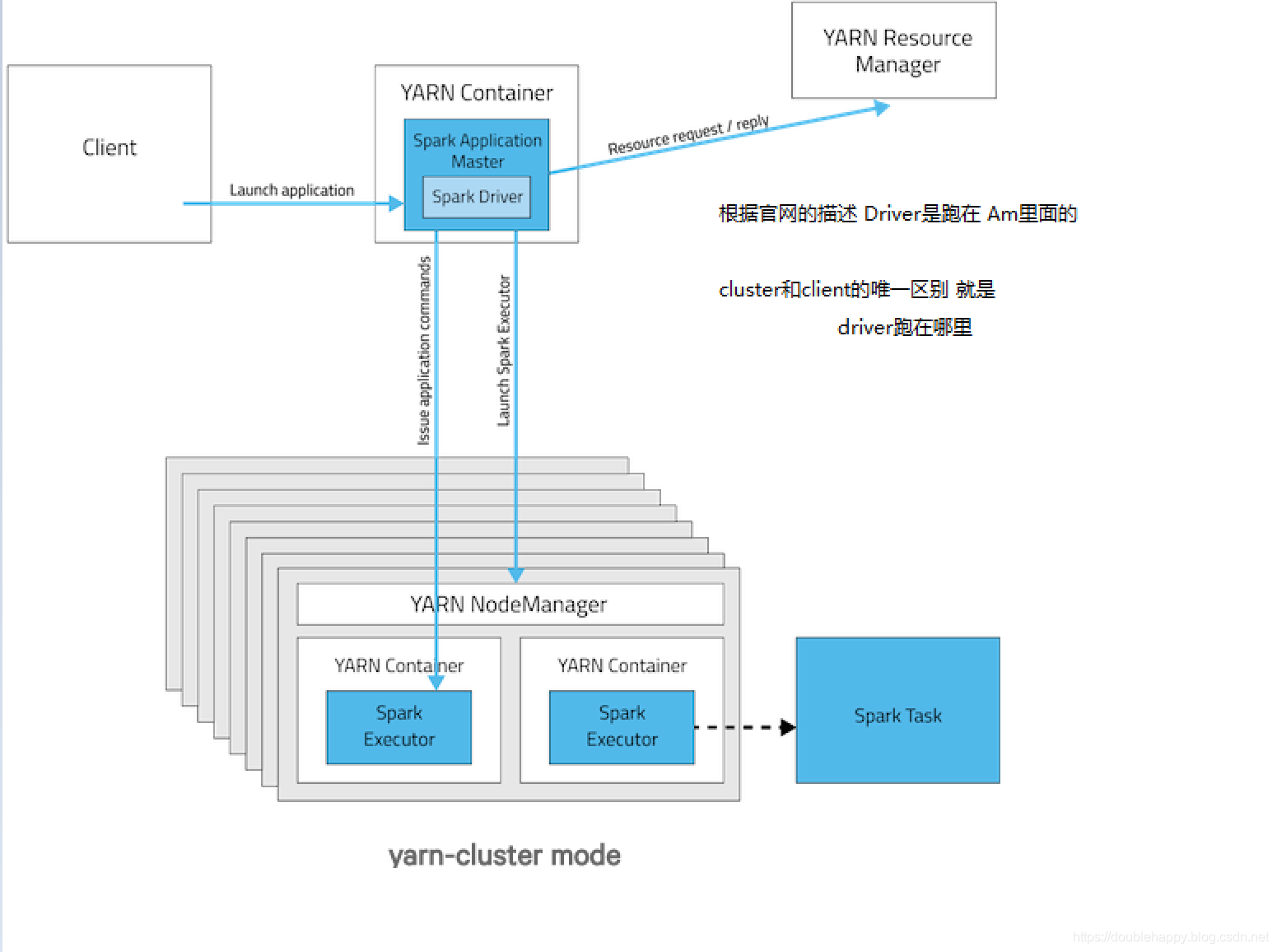
1 | spark on yarn 总结: |
测试:
1 | [double_happy@hadoop101 ~]$ spark-shell --help |
1 | --deploy-mode DEPLOY_MODE Whether to launch the driver program locally ("client") or |
client模式:测试
1 | [double_happy@hadoop101 ~]$ spark-shell --master yarn |
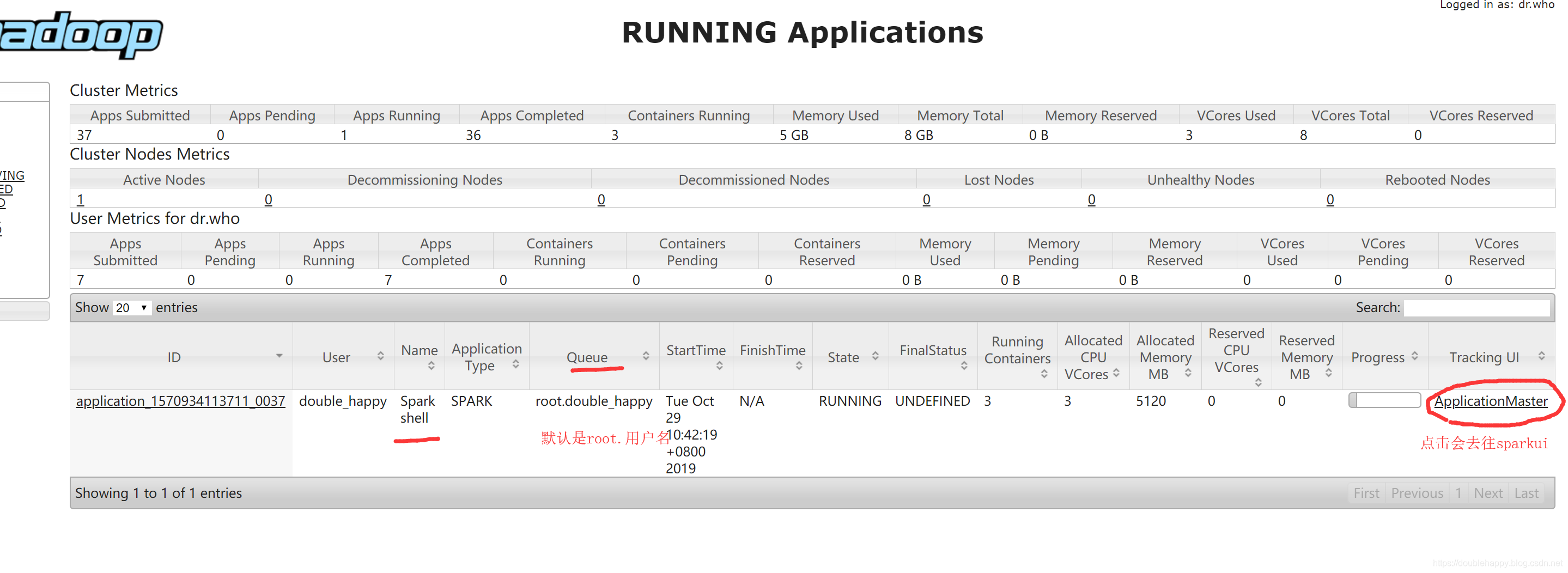
1 | 注意: |

1 | [double_happy@hadoop101 ~]$ spark-sql --jars ~/software/mysql-connector-java-5.1.47.jar --master yarn |
1 | 打开这个地址看一眼: |
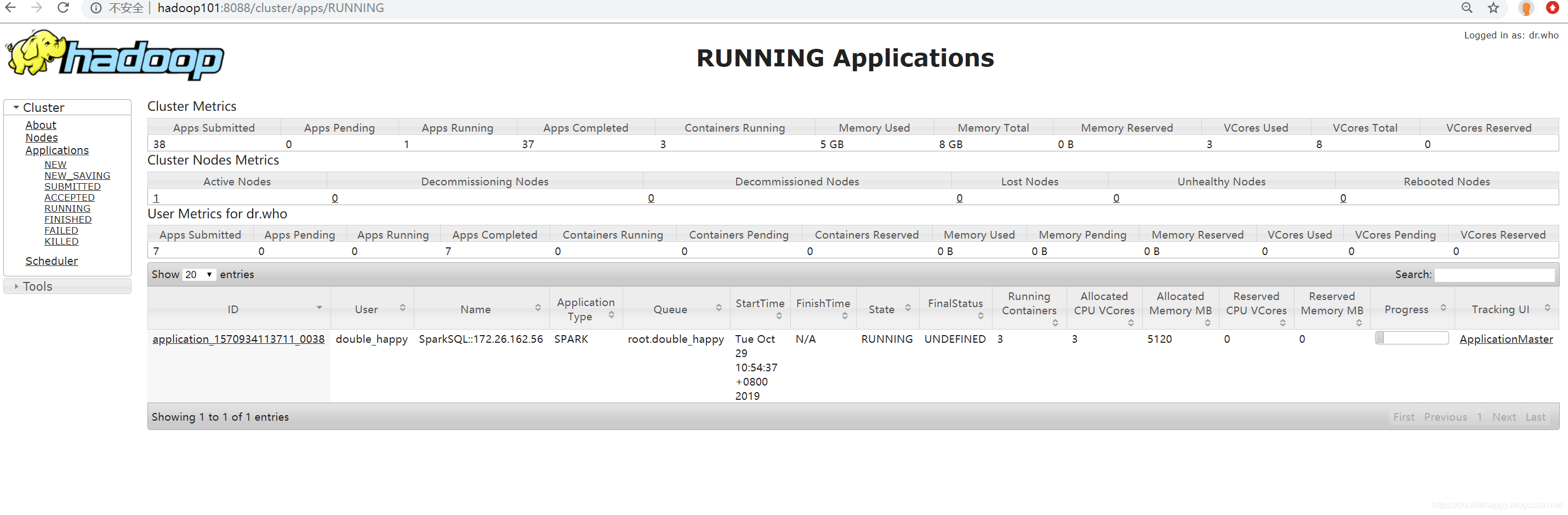
1 | spark-shell 和spark-sql 都可以 这不是主要的 主要的是下面的 |
1 | [double_happy@hadoop101 ~]$ spark-shell --master yarn --deploy-mode cluster |
1 | object SparkSessionApp { |
大部分人使用spark开发 Hive是使用 spark.sql(“ sql “)
可以的 我不喜欢 我还是喜欢使用api的方式 各有所爱
1 | 全局排序:这是使用sql的方式写的 |
1 | 全局排序 : Api方式 我喜欢的 |
1 | object LogApp { |
1 | api方式 开发 你要注意的是: |
1 | 分组:Top n |
1 | object LogApp { |
Catalog
非常非常重要 spark2.0之后才有的 我开发了一个csv入Hive 就用到了它
1 | 你Hive的元数据存在 MySQl里面的 |
开启spark-shell –jars MySQL驱动
1 | scala> val catalog = spark.catalog |
给你一个使用上面catalog的场景
做一个页面:

DataSet
这个东西很简单的
Untyped Dataset = Row
1 | DataSet就是你可以把它当作rdd来操作 |
Interoperating with RDDs
Interoperating with RDDs
和RDD的交互操作
1 | DS --》 DF 通过 DS.toDF("列名。。") |
1 | 1.反射的方式 RDD -》 DF |
1 | 2.编程的方式 |
1 | object RDDApp { |
UDF
1 | object UDFApp { |