操作Hive
1 | object SparkSessionApp { |
大部分人使用spark开发 Hive是使用 spark.sql(“ sql “)
可以的 我不喜欢 我还是喜欢使用api的方式 各有所爱
1 | 全局排序:这是使用sql的方式写的 |
1 | 全局排序 : Api方式 我喜欢的 |
1 | object LogApp { |
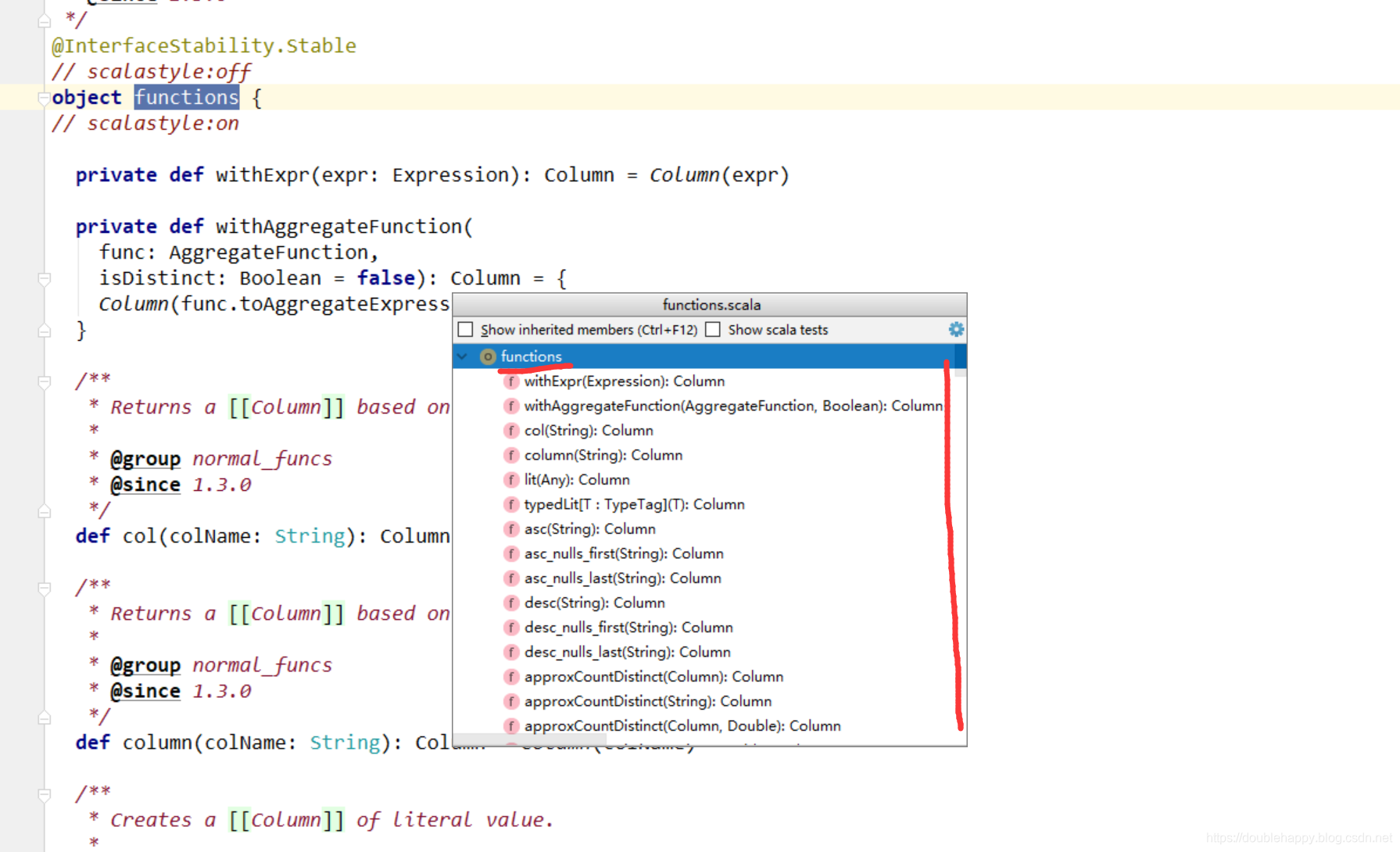
1 | api方式 开发 你要注意的是: |
1 | 分组:Top n |
1 | object LogApp { |
Catalog
非常非常重要 spark2.0之后才有的 我开发了一个csv入Hive 就用到了它
1 | 你Hive的元数据存在 MySQl里面的 |
开启spark-shell –jars MySQL驱动
1 | scala> val catalog = spark.catalog |
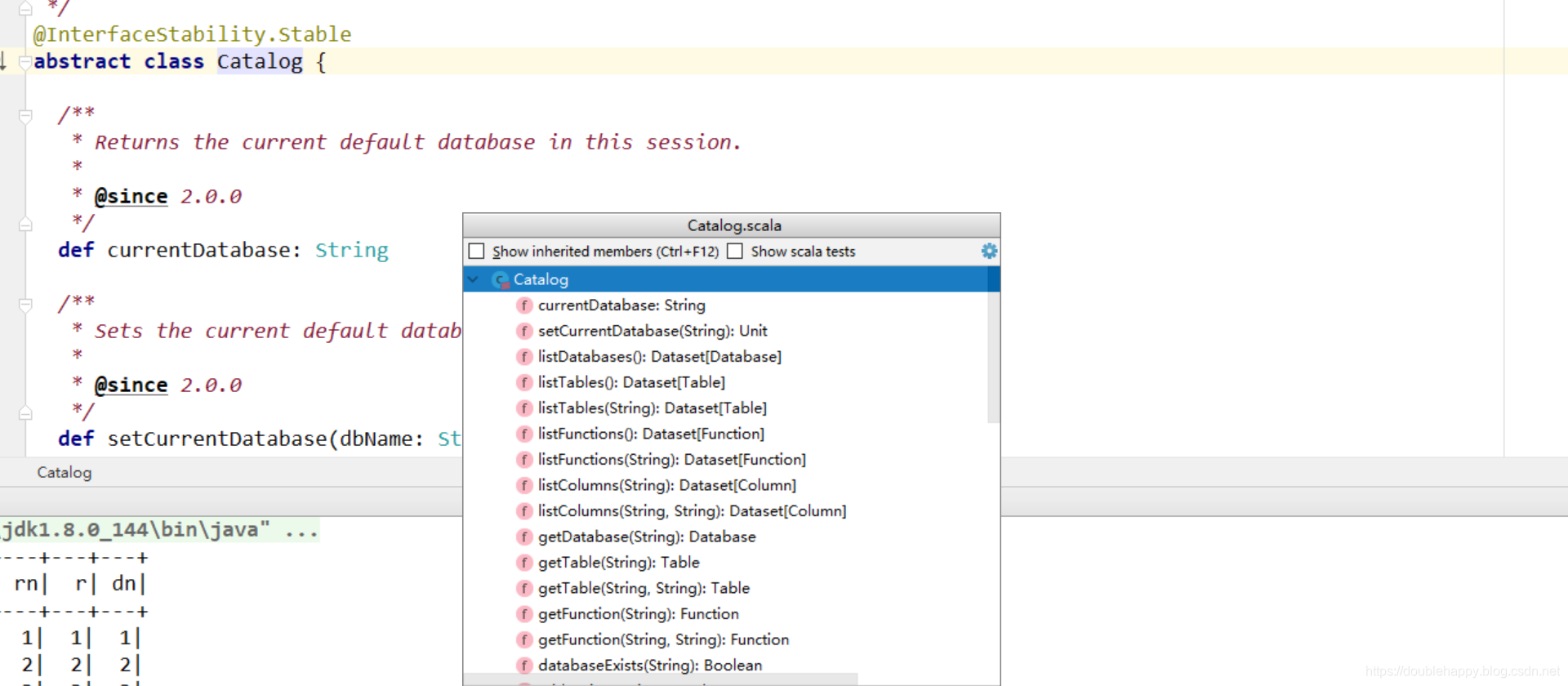
给你一个使用上面catalog的场景
做一个页面:

DataSet
这个东西很简单的
Untyped Dataset = Row
1 | DataSet就是你可以把它当作rdd来操作 |
Interoperating with RDDs
Interoperating with RDDs
和RDD的交互操作
1 | DS --》 DF 通过 DS.toDF("列名。。") |
1 | 1.反射的方式 RDD -》 DF |
1 | 2.编程的方式 |
1 | object RDDApp { |
UDF
1 | object UDFApp { |