1 | 在object LogApp { |
演示上面代码可能的问题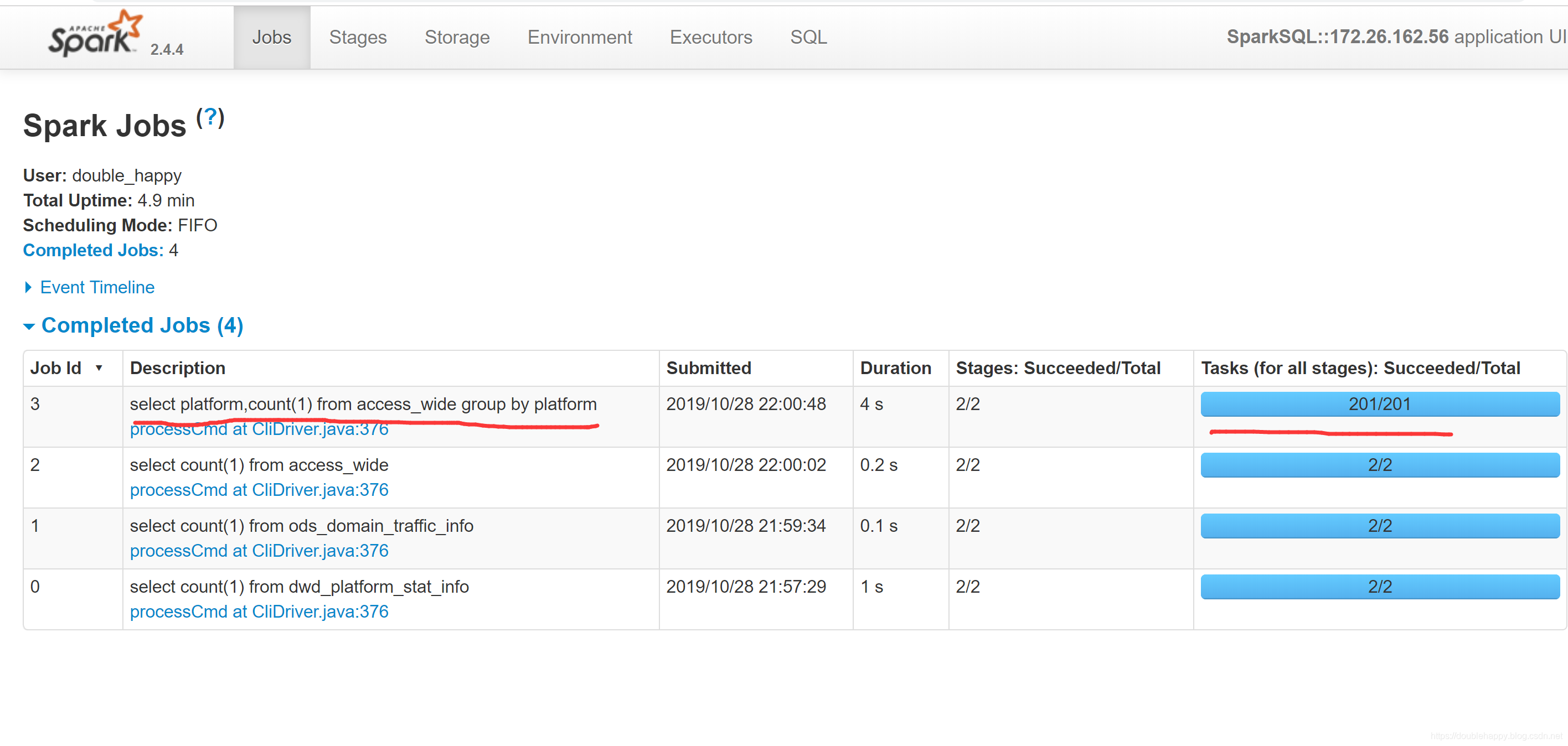
1 | 这200 哪里来的 ? |
1 | 还有一点就是: |
ETL
1 | ETL |
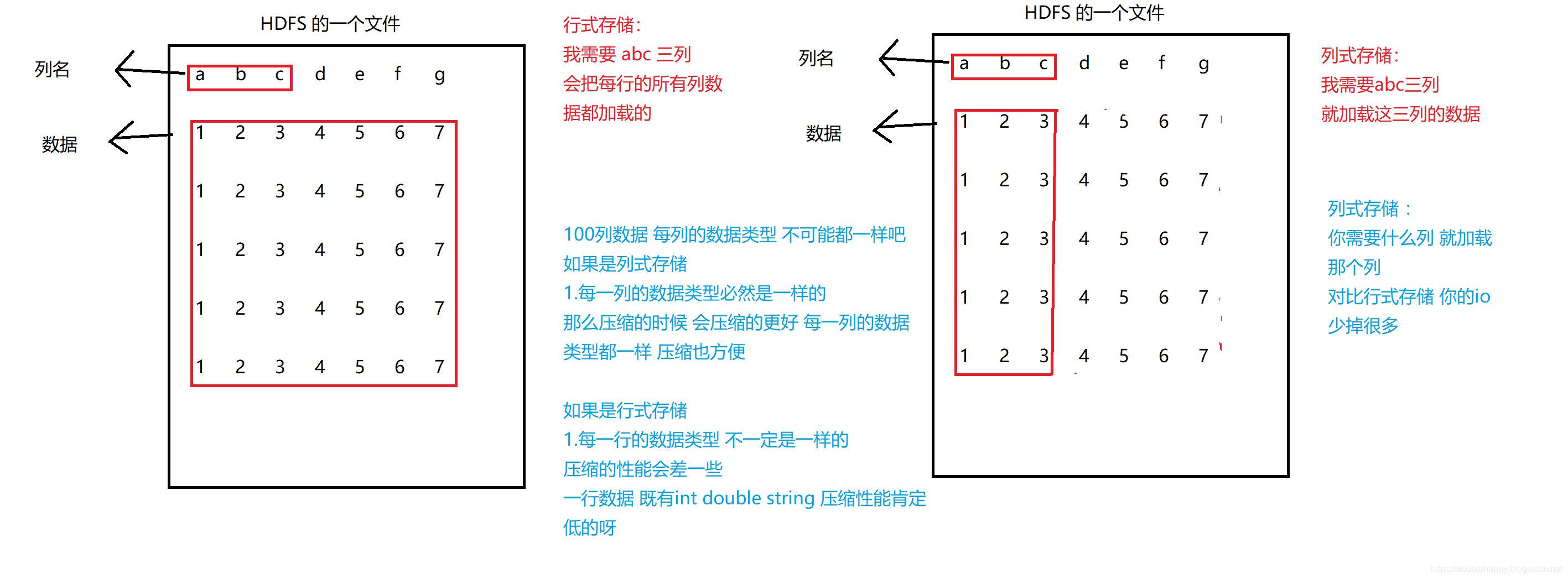
1 | 行式存储:MySQL |
1 | 列式:Orc Parquet |
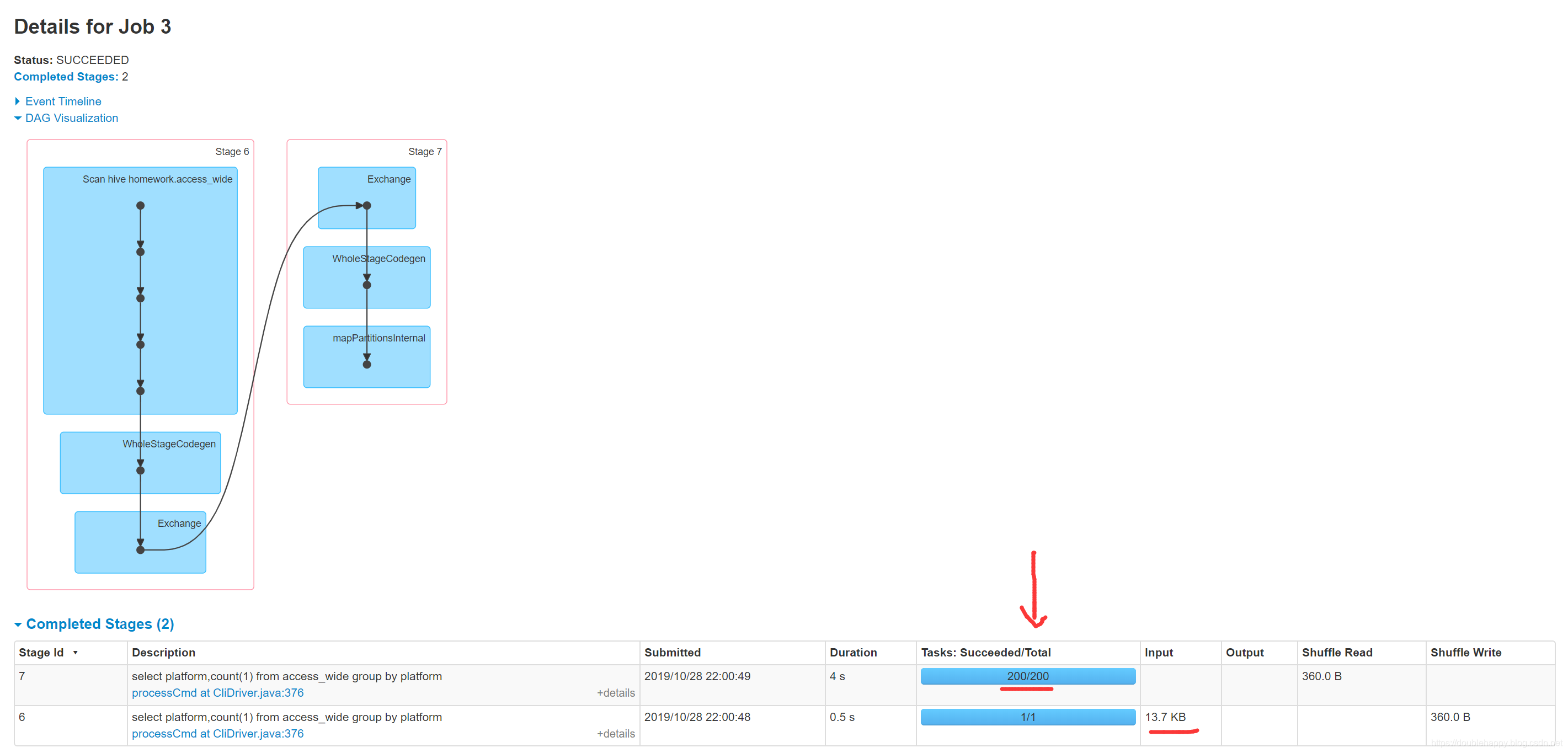
1 | 使用行式存储 spark跑程序的时候官网也列举了很多问题 |
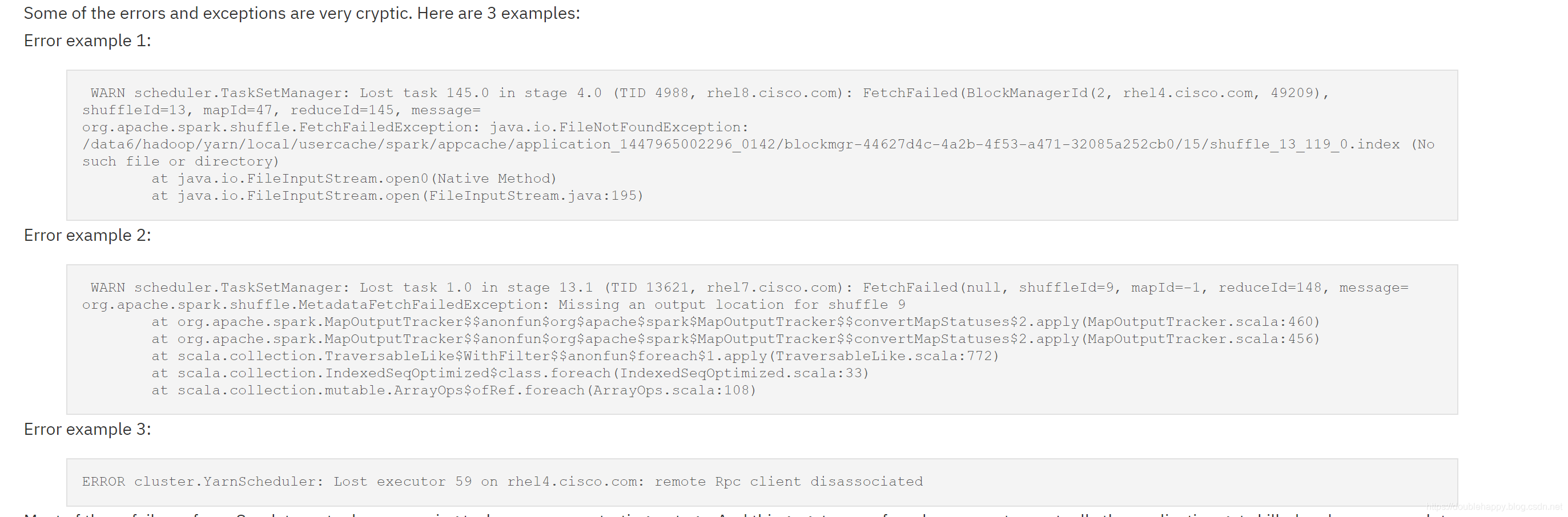
1 | 那么Most of these failures force Spark to re-try by re-queuing tasks: |
1 | 存储是结合 压缩来用的 eg:orc + lzo |
beeline/jdbc
生产上是用的
1 | hiveserver2 beeline/jdbc Hive里的 |
1 | [double_happy@hadoop101 sbin]$ ./start-thriftserver.sh --jars ~/software/mysql-connector-java-5.1.47.jar |
1 | [double_happy@hadoop101 sbin]$ tail -200f /home/double_happy/app/spark/logs/spark-double_happy-org.apache.spark.sql.hive.thriftserver.HiveThriftServer2-1-hadoop101.out |
1 | 说明 thriftserver 启动起来了 |
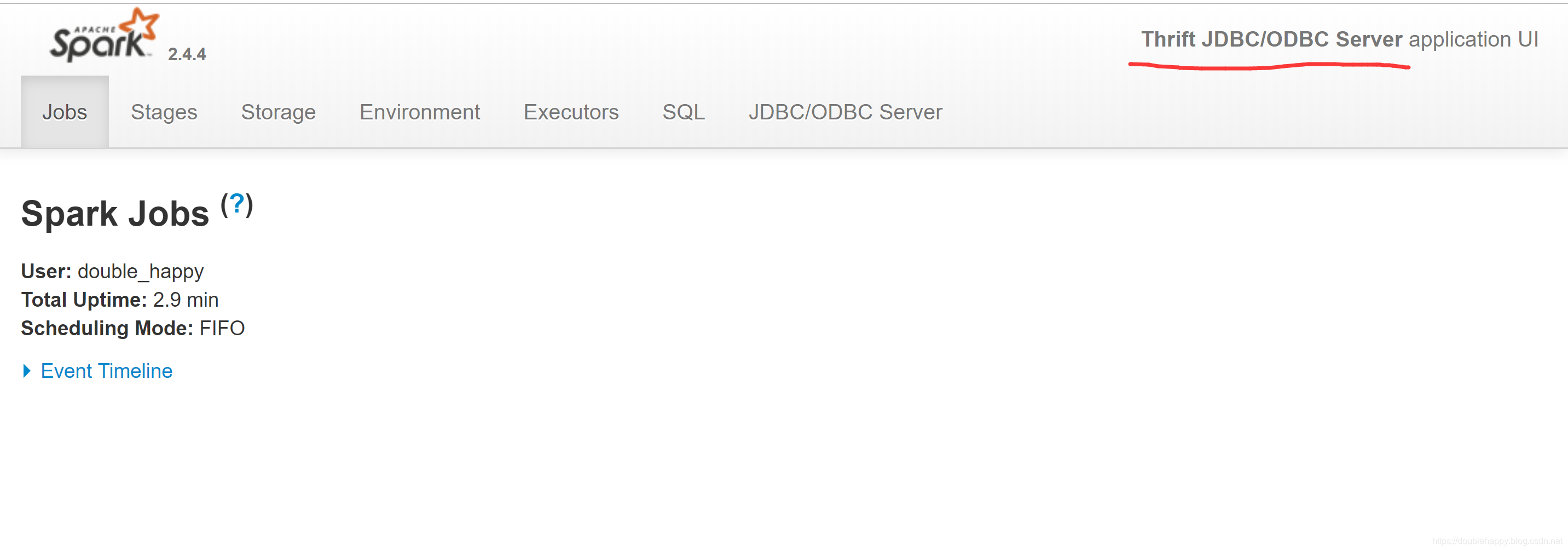
1 | 这是 thriftserver 端起来了 说明服务端有了 |
1 | [double_happy@hadoop101 bin]$ ./beeline -u jdbc:hive2://hadoop101:10000/ruozedata_g7 -n double_happy |
1 | [double_happy@hadoop101 bin]$ ./beeline -u jdbc:hive2://hadoop101:10000/homework -n double_happy |
1 | 这个东西适用在哪里呢? |
Spark On Yarn
Running Spark on YARN
There are two deploy modes that can be used to launch Spark applications on YARN. In cluster mode, the Spark driver runs inside an application master process which is managed by YARN on the cluster, and the client can go away after initiating the application. In client mode, the driver runs in the client process, and the application master is only used for requesting resources from YARN.
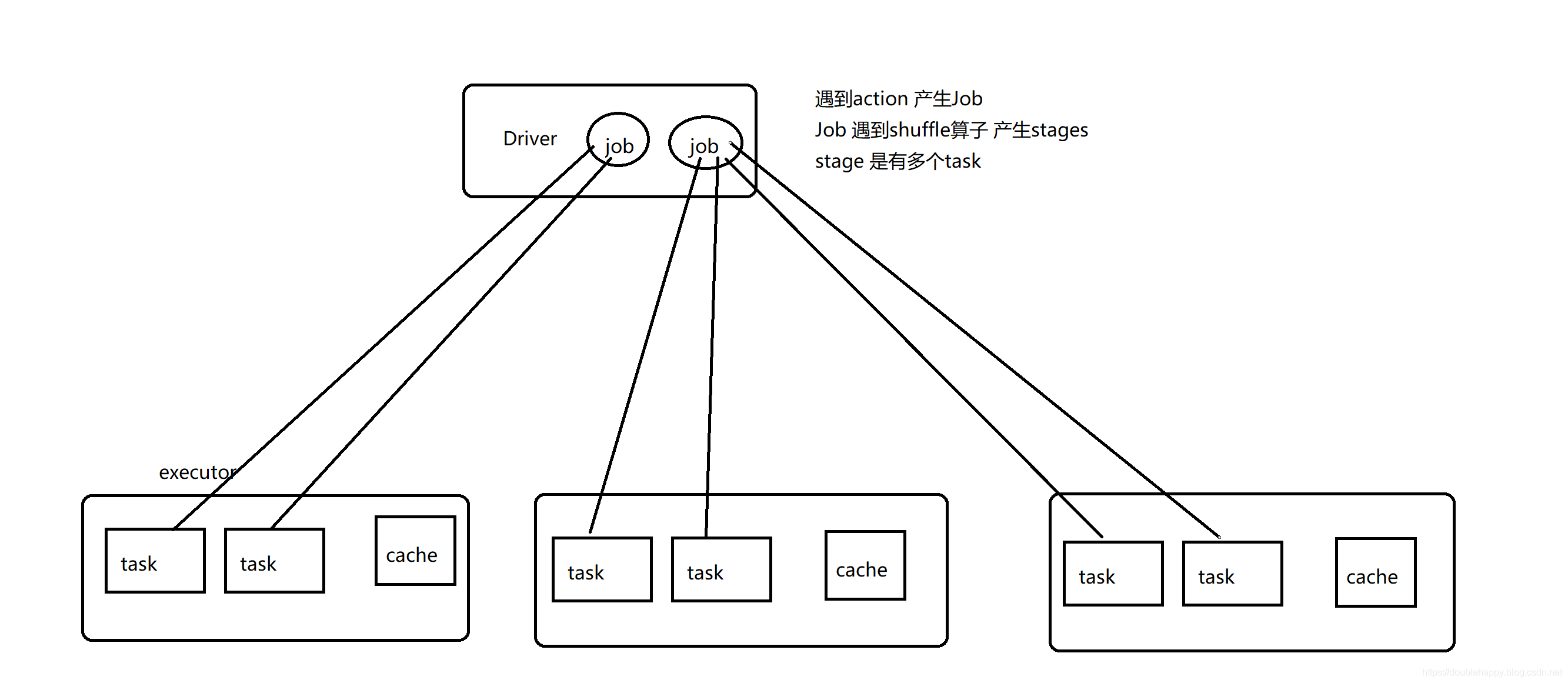
client模式:
1 | 在Spark on YARN中 是没有Worker的概念,是Standalone中的 |
cluster模式:
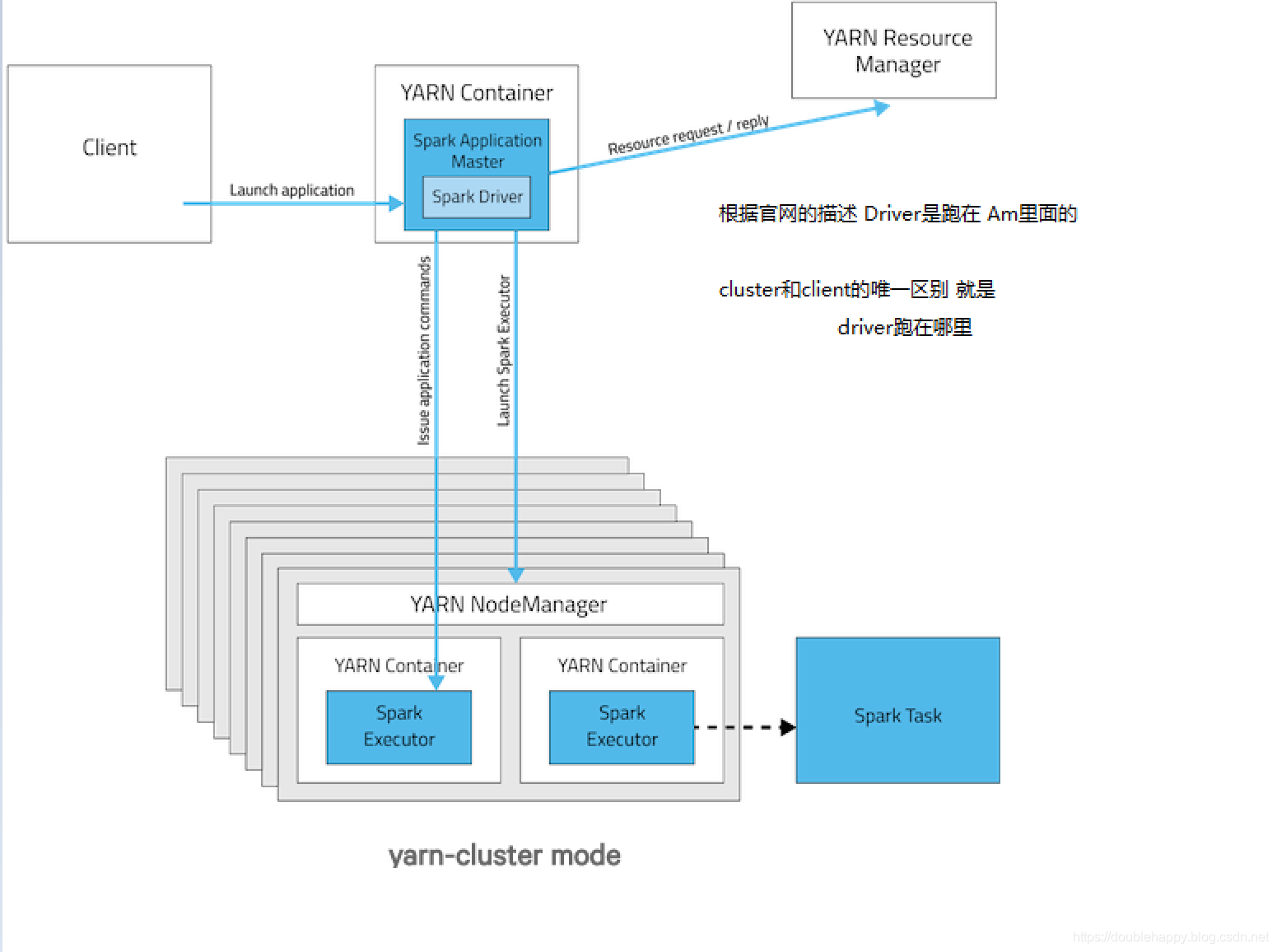
1 | spark on yarn 总结: |
测试:
1 | [double_happy@hadoop101 ~]$ spark-shell --help |
1 | --deploy-mode DEPLOY_MODE Whether to launch the driver program locally ("client") or |
client模式:测试
1 | [double_happy@hadoop101 ~]$ spark-shell --master yarn |
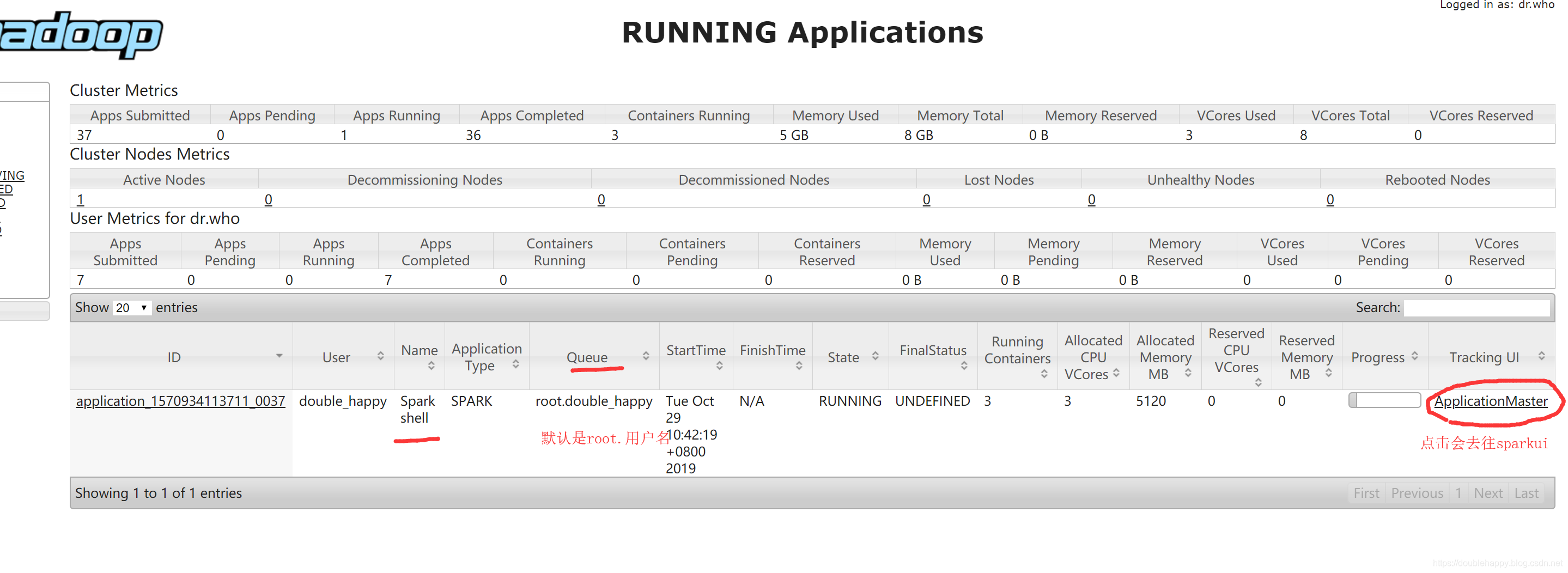
1 | 注意: |

1 | [double_happy@hadoop101 ~]$ spark-sql --jars ~/software/mysql-connector-java-5.1.47.jar --master yarn |
1 | 打开这个地址看一眼: |
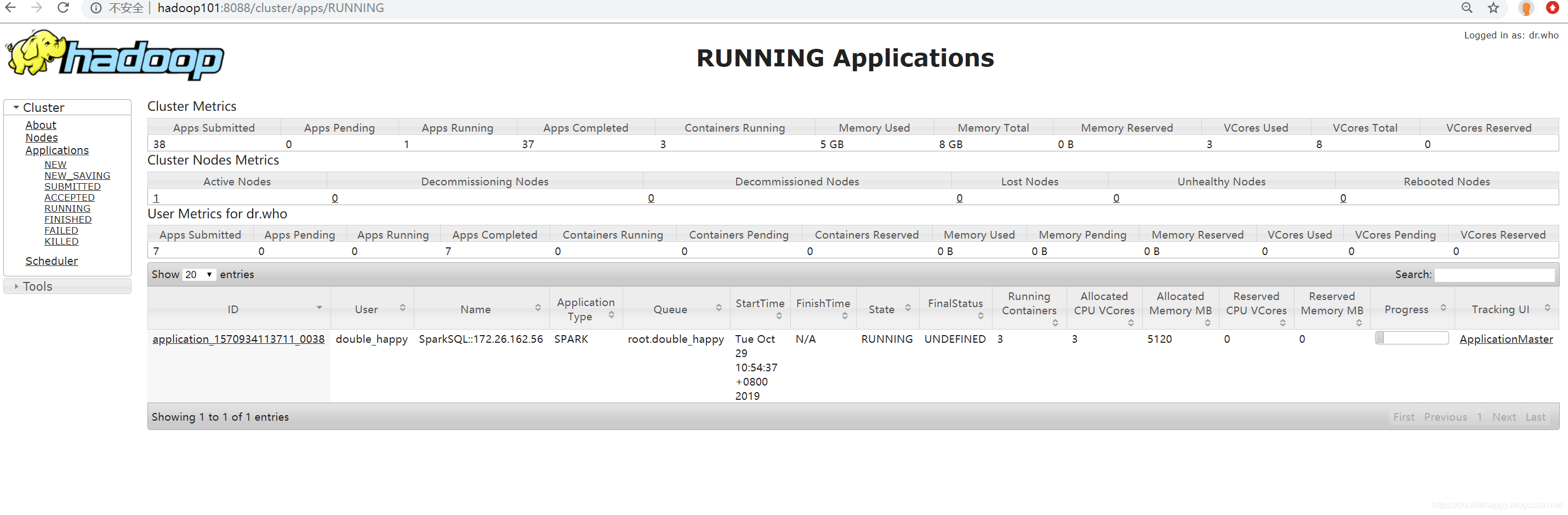
1 | spark-shell 和spark-sql 都可以 这不是主要的 主要的是下面的 |
1 | [double_happy@hadoop101 ~]$ spark-shell --master yarn --deploy-mode cluster |