工作当中几乎全用SparkSQL ,RDD用的很少(面试多)
SparkSQL误区
Spark SQL is Apache Spark’s module for working with structured data.
不要把SparkSQL认为就是处理SQl的 或者认为就是写SQL
SparkSQL
1 | 误区: |

1 | 3.Standard Connectivity |

1 | 误区3: |
1 | Time taken: 6.86 seconds, Fetched: 2 row(s) |
1 | 这个东西了解即可 Hive On Spark 真正生产上用的很少的 |
Datasets and DataFrames
1 | 出来的时间: |
DataFrame
A Dataset is a distributed collection of data.
A DataFrame is a Dataset organized into named columns.
DataFrame = Dataset[Row]
In Scala and Java, a DataFrame is represented by a Dataset of Rows.
1 | DataFrame : |
Api:
1 |
|
1 | scala> spark.sql("show tables").show |
1 | 查看Hive里元数据: |
1 | 使用sparksql 在spark-shell交互 还得写 spark.sql |
编程
1 | 1.SparkSession构建 |
Data Sources
1.读文本数据
1 | 1.读文本数据 |
1 | def text(spark: SparkSession) = { |
取出第一列输出出去 注意df 和ds的区别
df: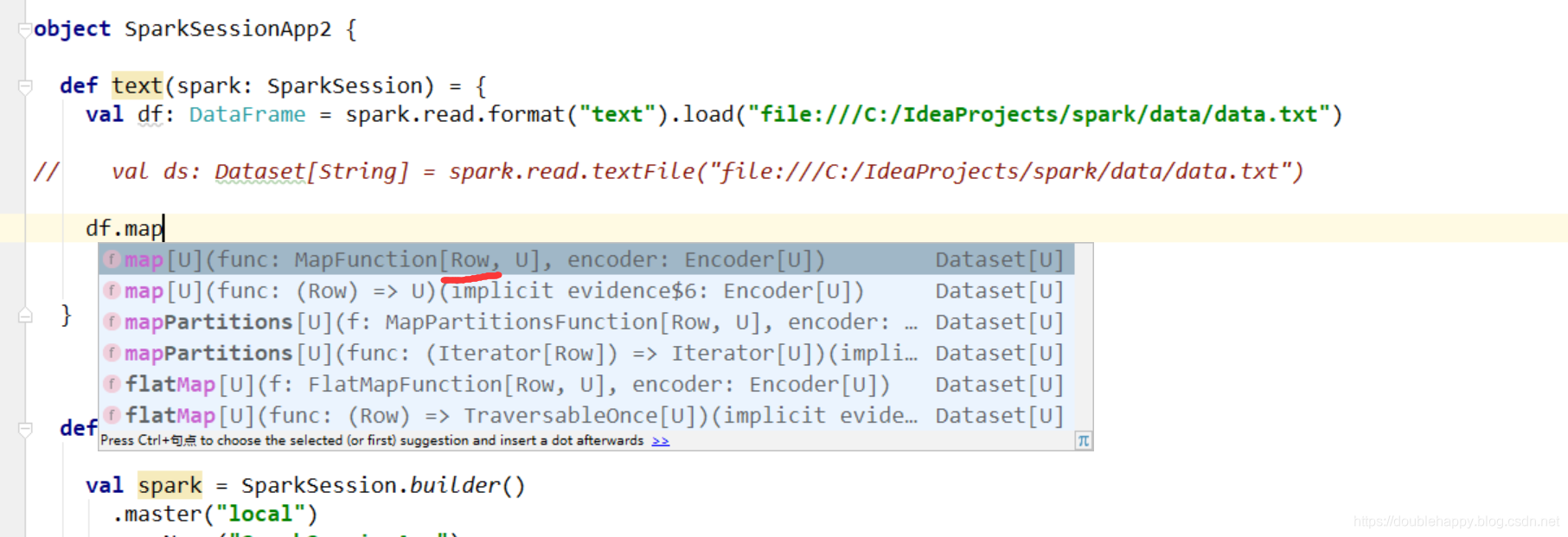
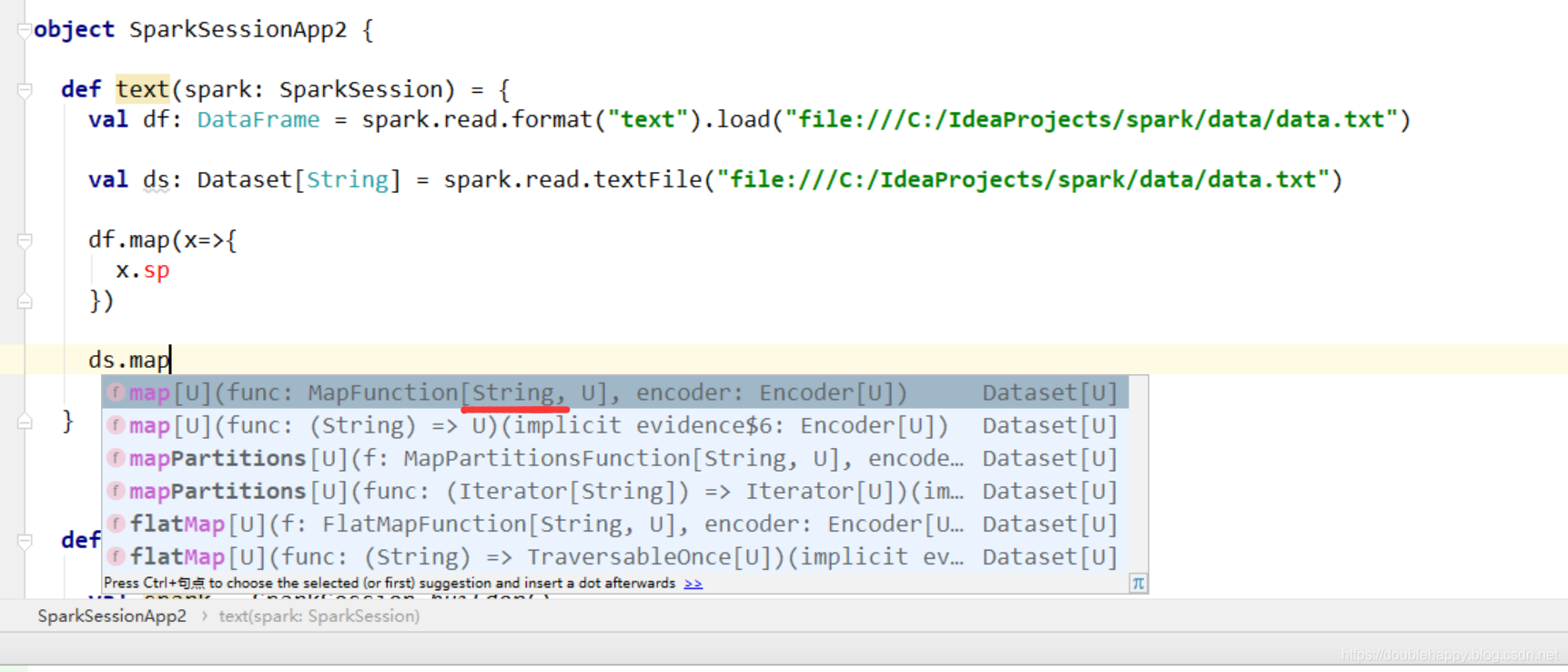
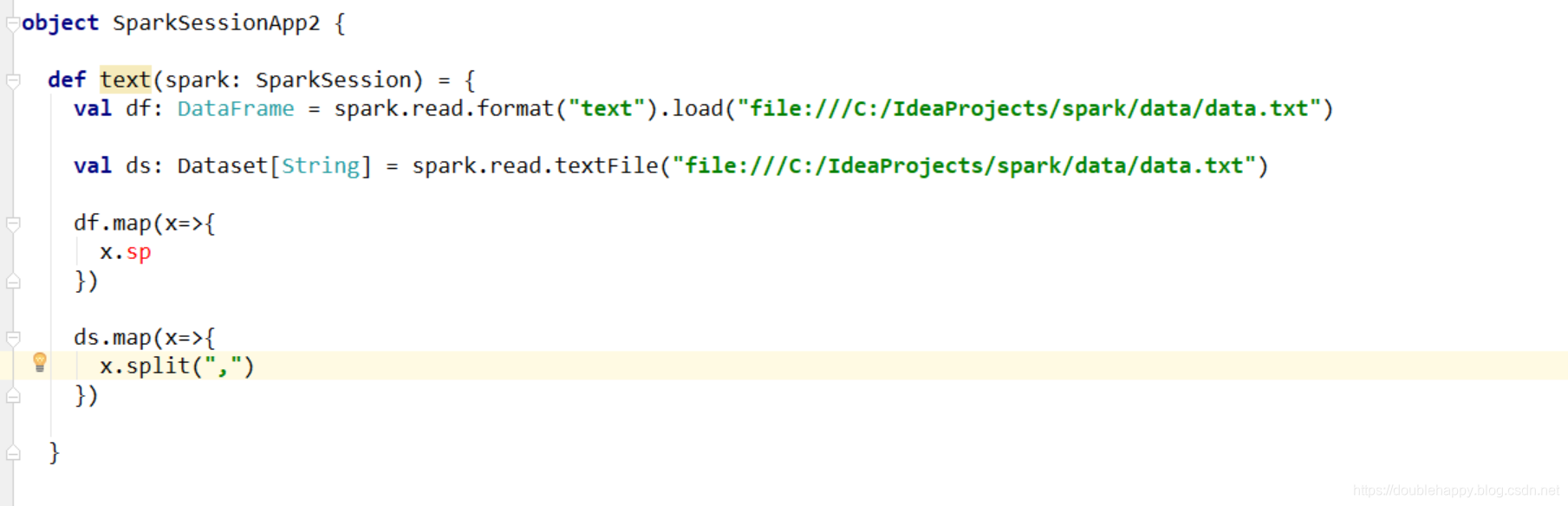
1 | 1. df.map 里面是row ds.map 里面是String |
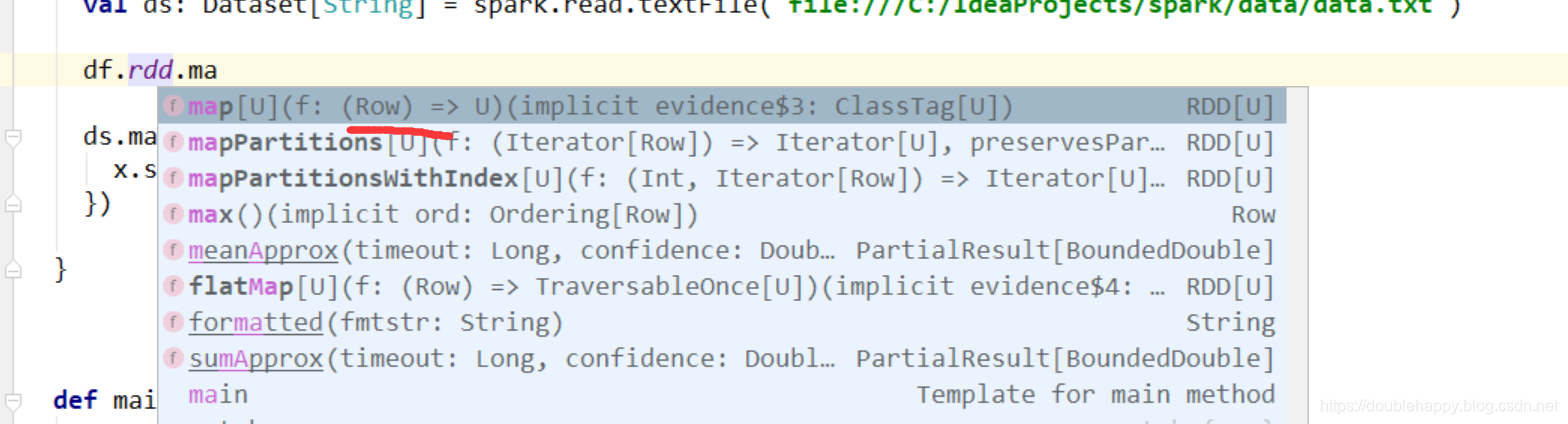
1 | object SparkSessionApp2 { |
1 | object SparkSessionApp2 { |
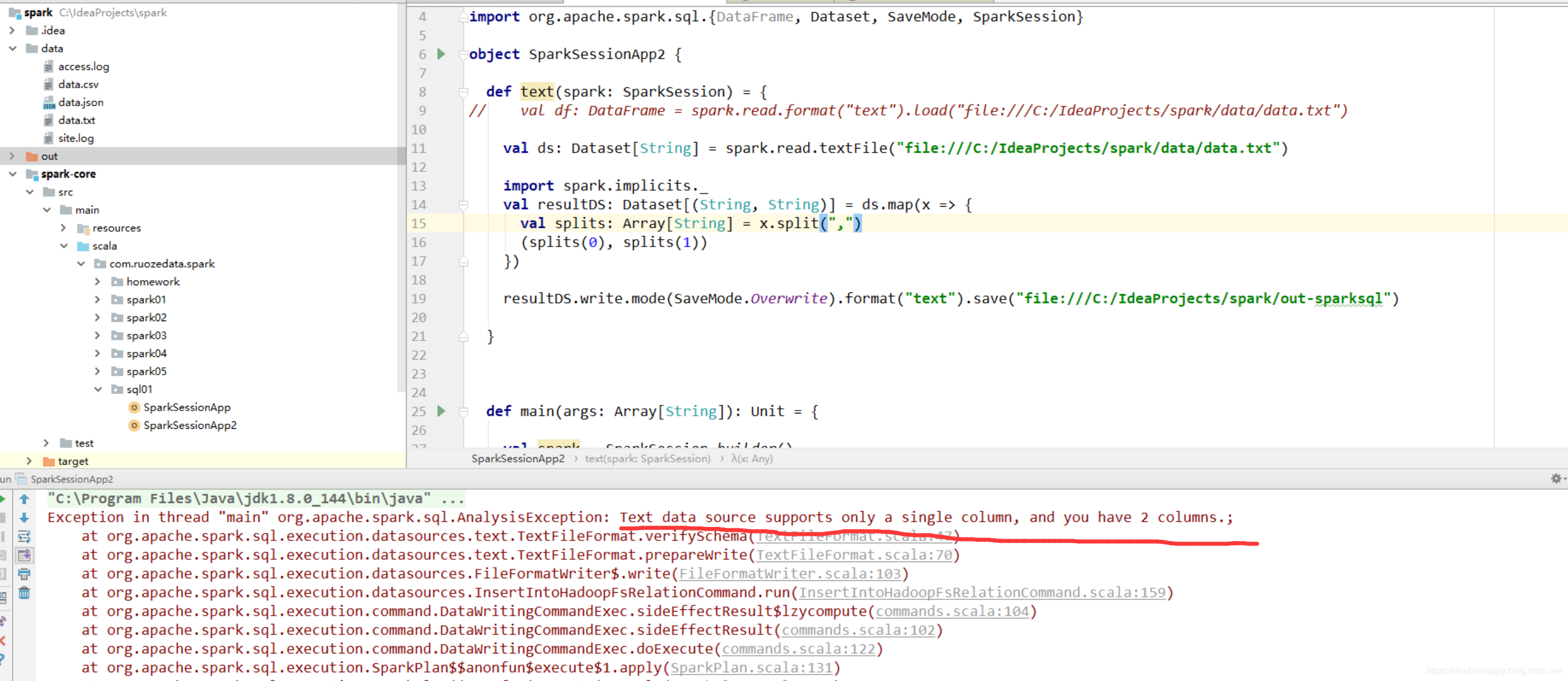
1 | 那么我们只输出一列 : |
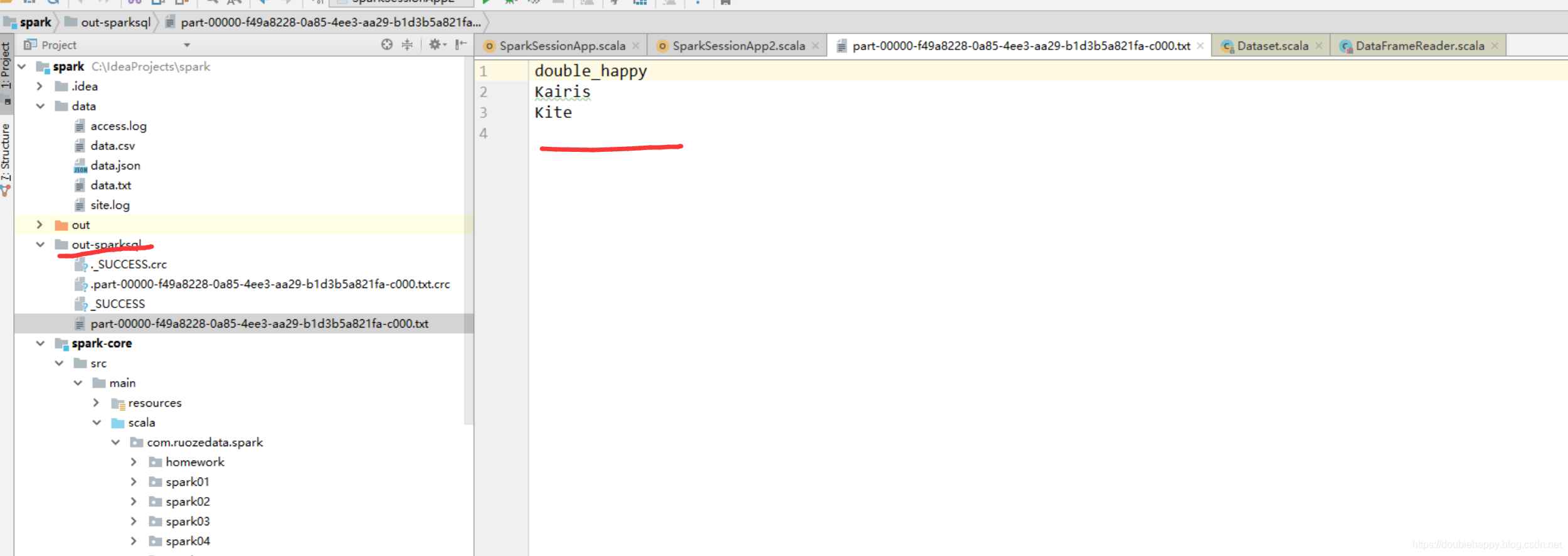
1 | 但是 有个问题的 文本格式是非常常用的格式 你只支持 一列输出 有个鬼用 |
上面的问题之后再解决
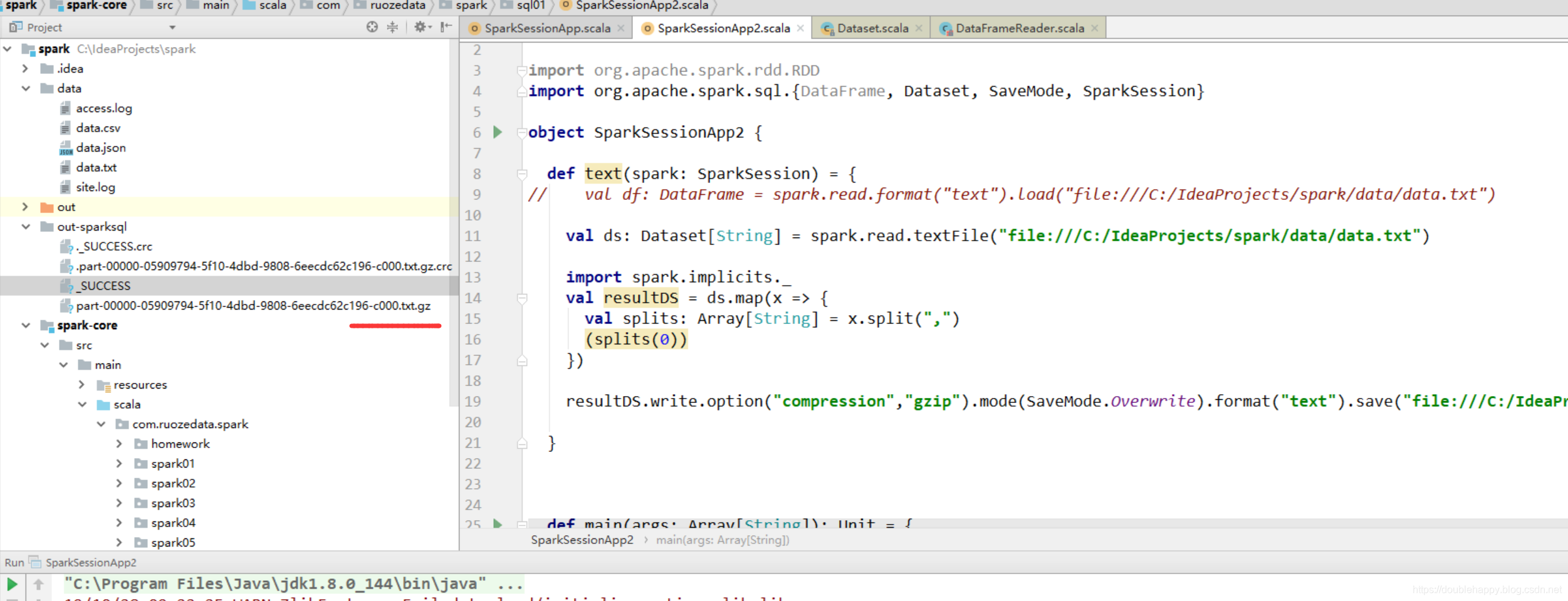
那么 这个输出的数据也是可以用压缩的
1 | object SparkSessionApp2 { |
注意: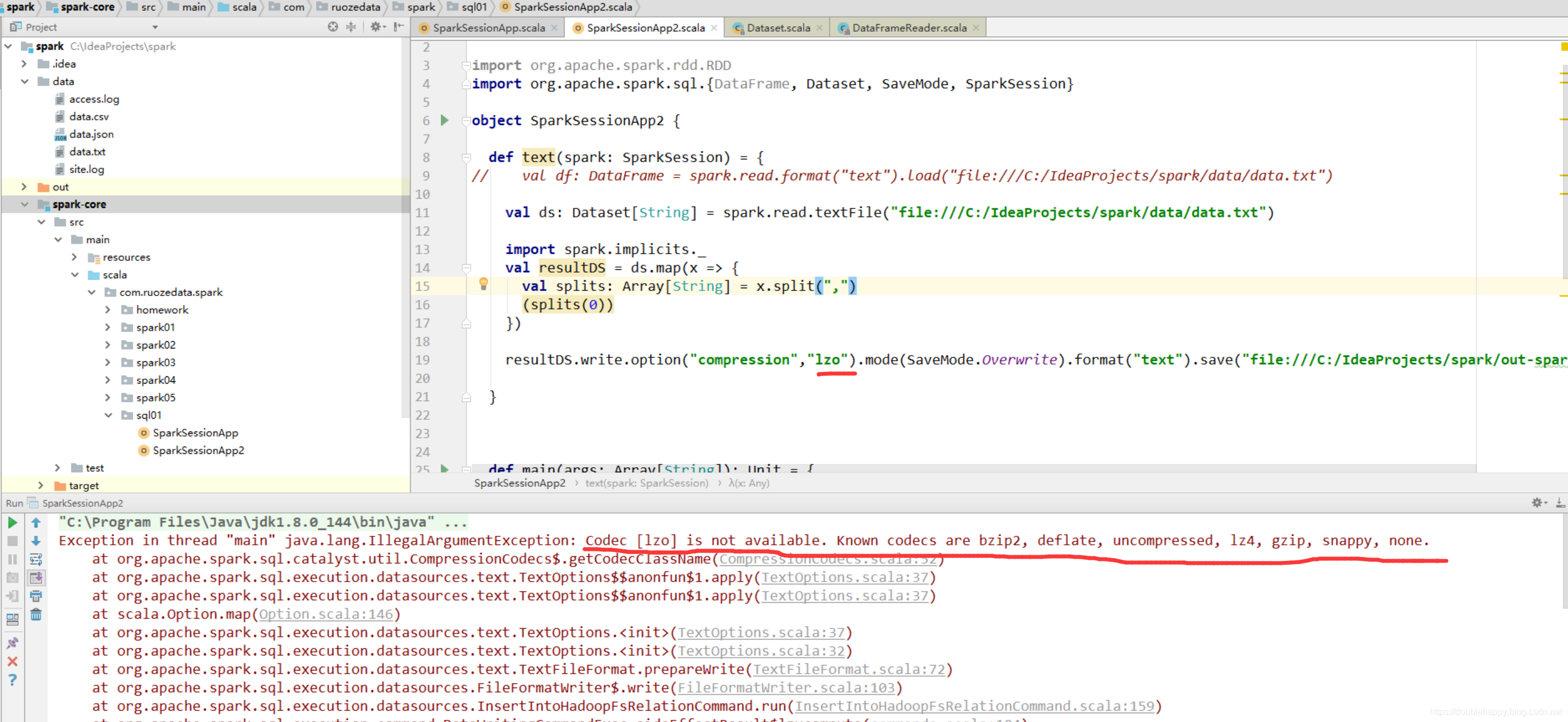
1 | 也就是说这个压缩 codec 是有限制的 |
2.读json数据
1 | object SparkSessionApp2 { |
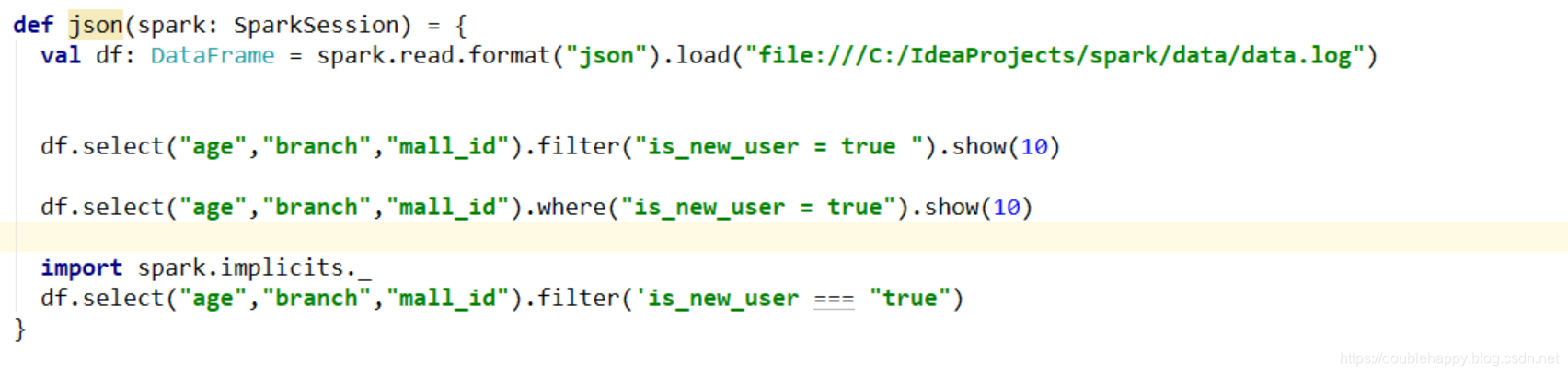
1 | def json(spark: SparkSession) = { |
1 | filter 和where 里面 有好多中写法 : |

1 | 但是报错: 加一个隐式转换 |
1 | def json(spark: SparkSession) = { |
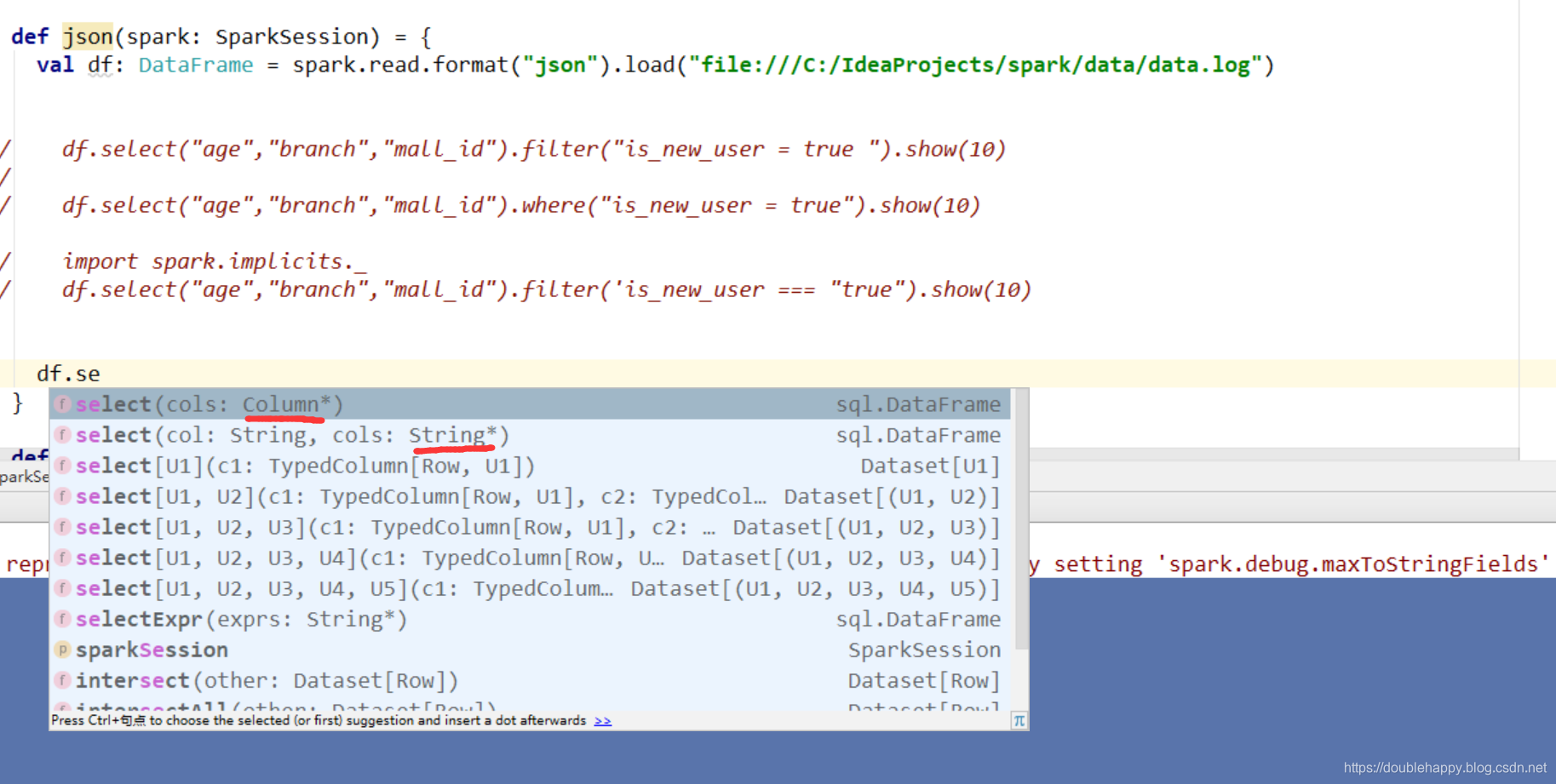
1 | 写法很多 : |
1 | object SparkSessionApp2 { |
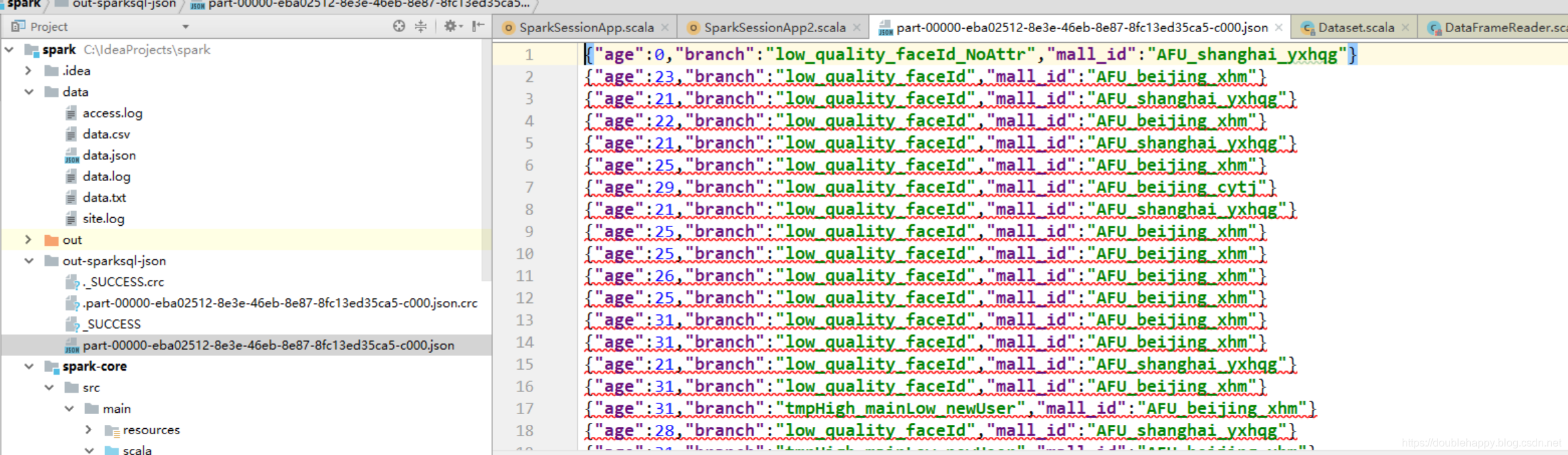
1 | 解析json 嵌套 + Sturct类型的 你会么? 给个思路 就是 exploded +打点 |
3.读csv数据
csv文件打开是execel能看见的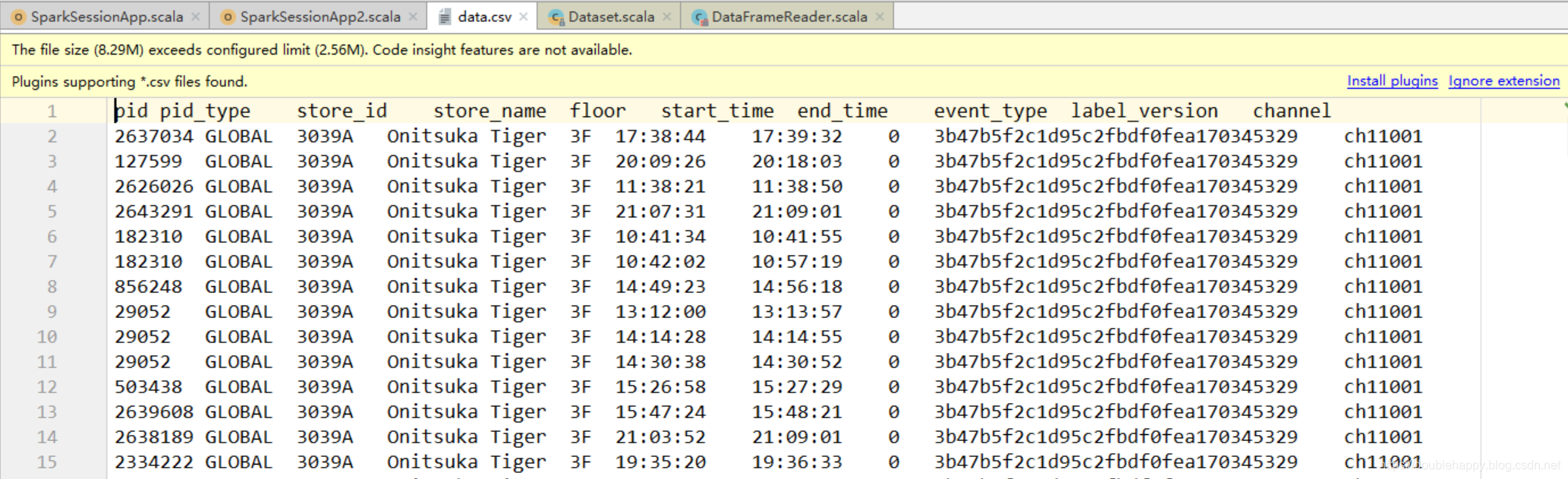
1 | object SparkSessionApp2 { |
1 | object SparkSessionApp2 { |
1 | object SparkSessionApp2 { |
1 | object SparkSessionApp2 { |
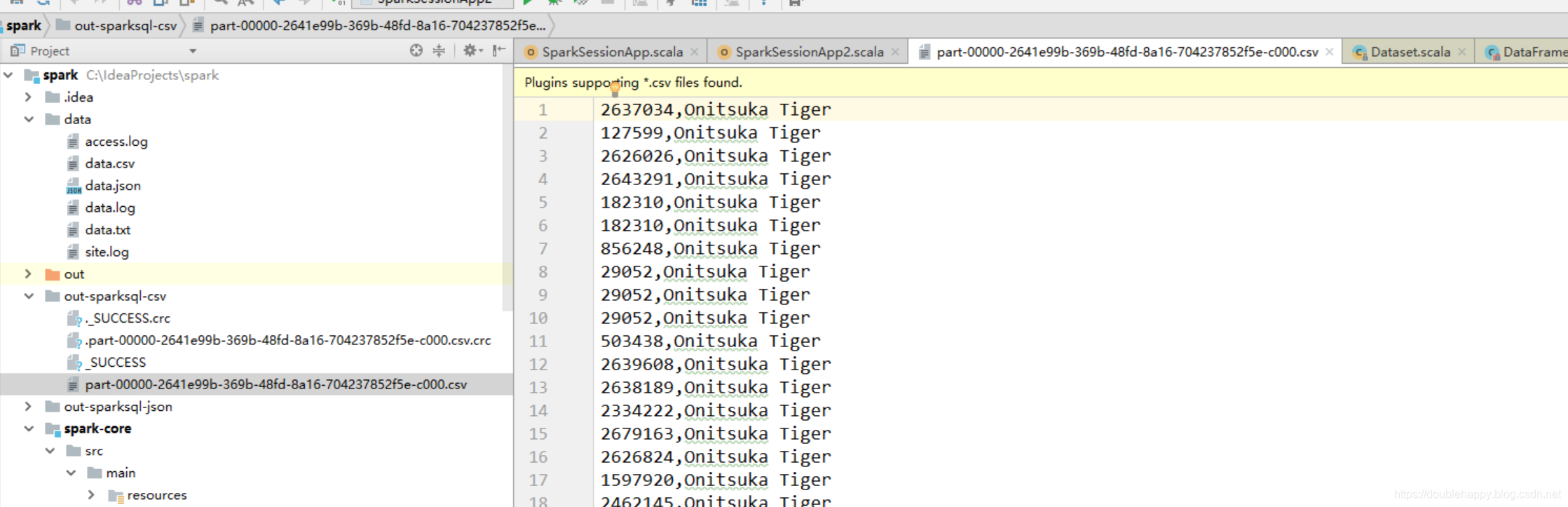
1 | 这些 option 参数 我是怎么知道的 ?去源码里找 |
4.读jdbc数据
MySQL中的数据是这样的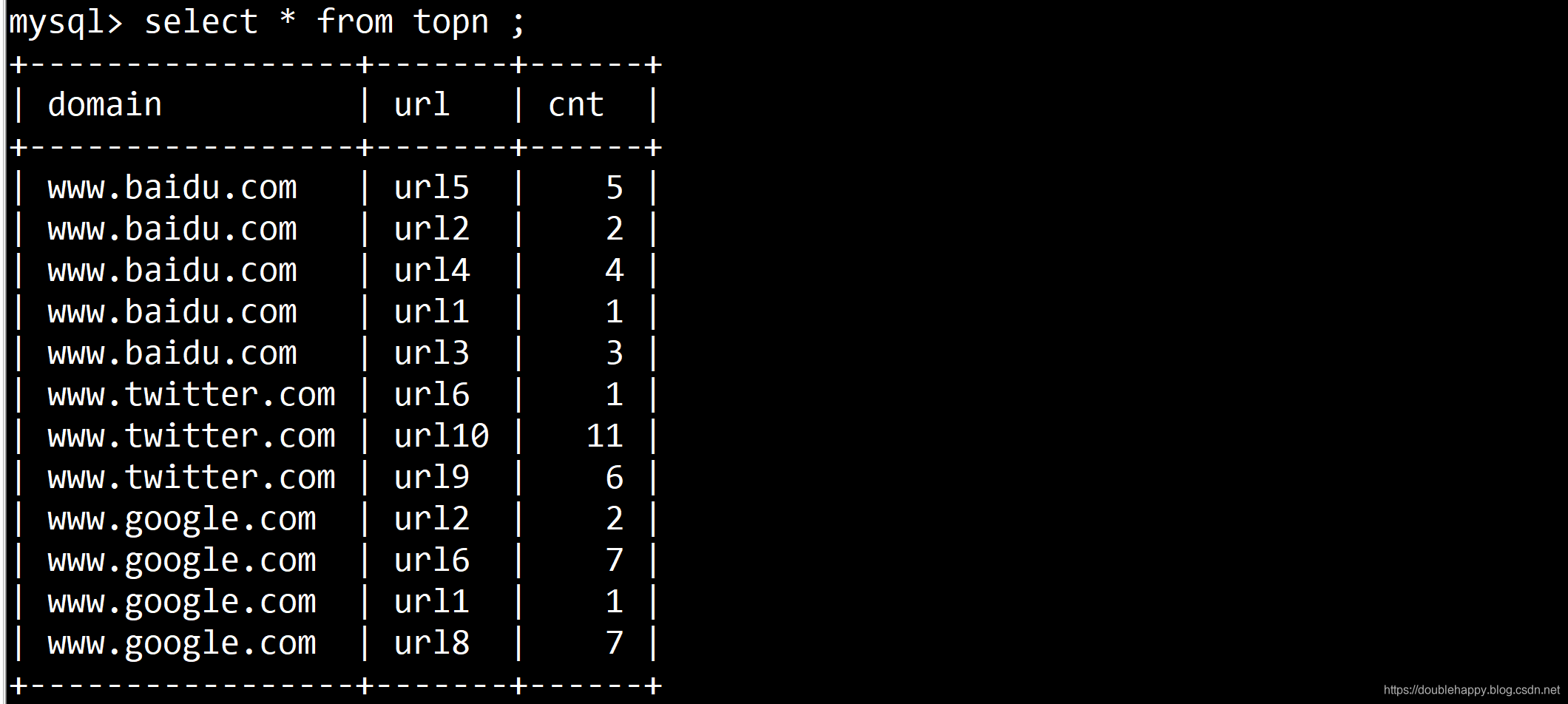
1 | object SparkSessionApp2 { |
JDBC To Other Databases
官网有好多写法
1 | object SparkSessionApp2 { |
1 | mysql> show tables; |
1 | 但是按照上面写 是不是太恶心了 参数 全都写死的 |
1 | mysql> select * from topn_3; |