1 | 面试题:谈谈你对Flink ON YARN执行流程的理解 |
1 | Sinl 到 HBase: |
Hadoop Compatibility Beta
Hadoop Compatibility Beta
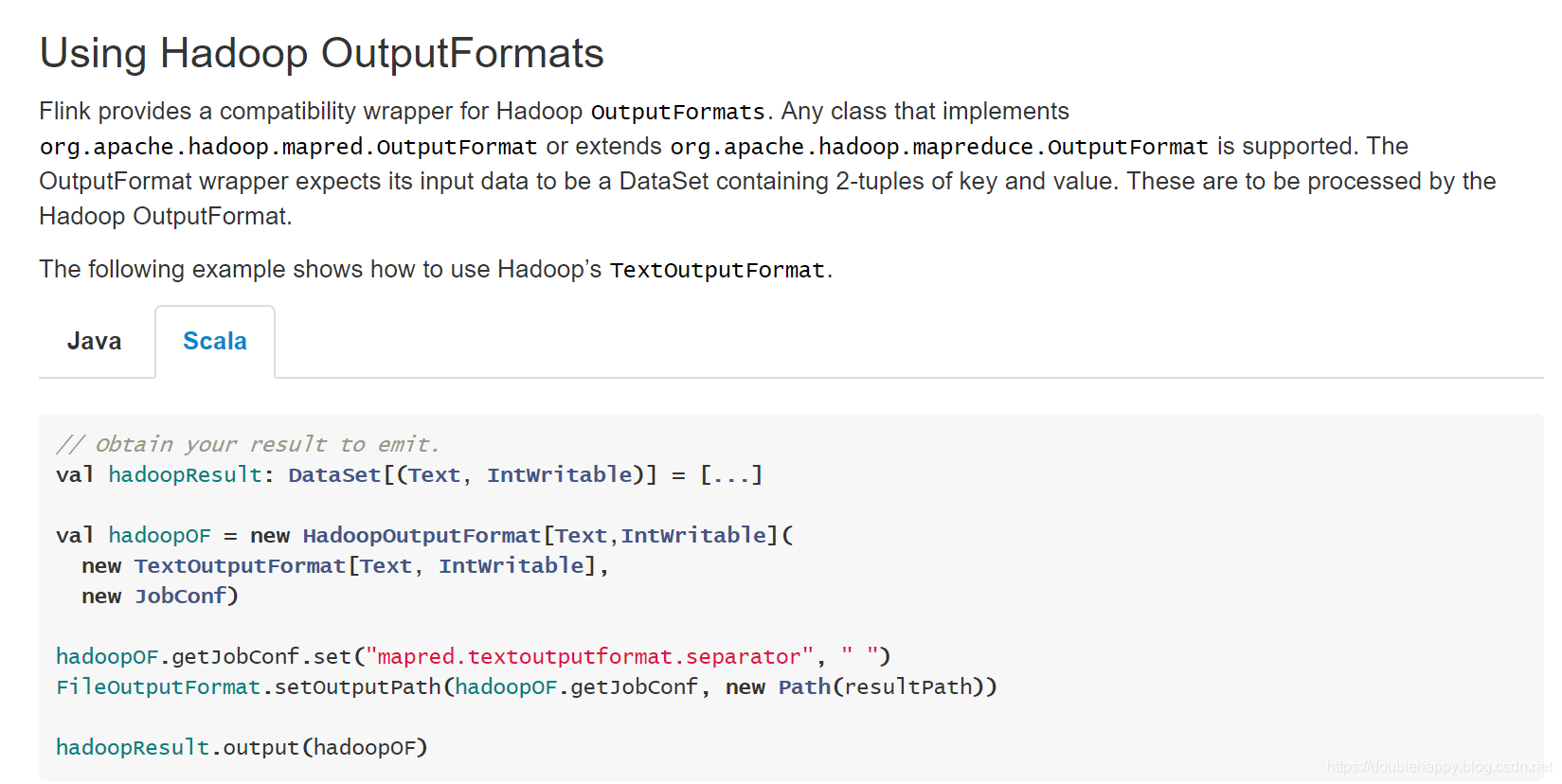
1 | 也就是说 : |
环境部署
Building Flink from Source
部署:
1 | 部署: |
Local
Local Setup Tutorial
1 | 1.启动集群: |
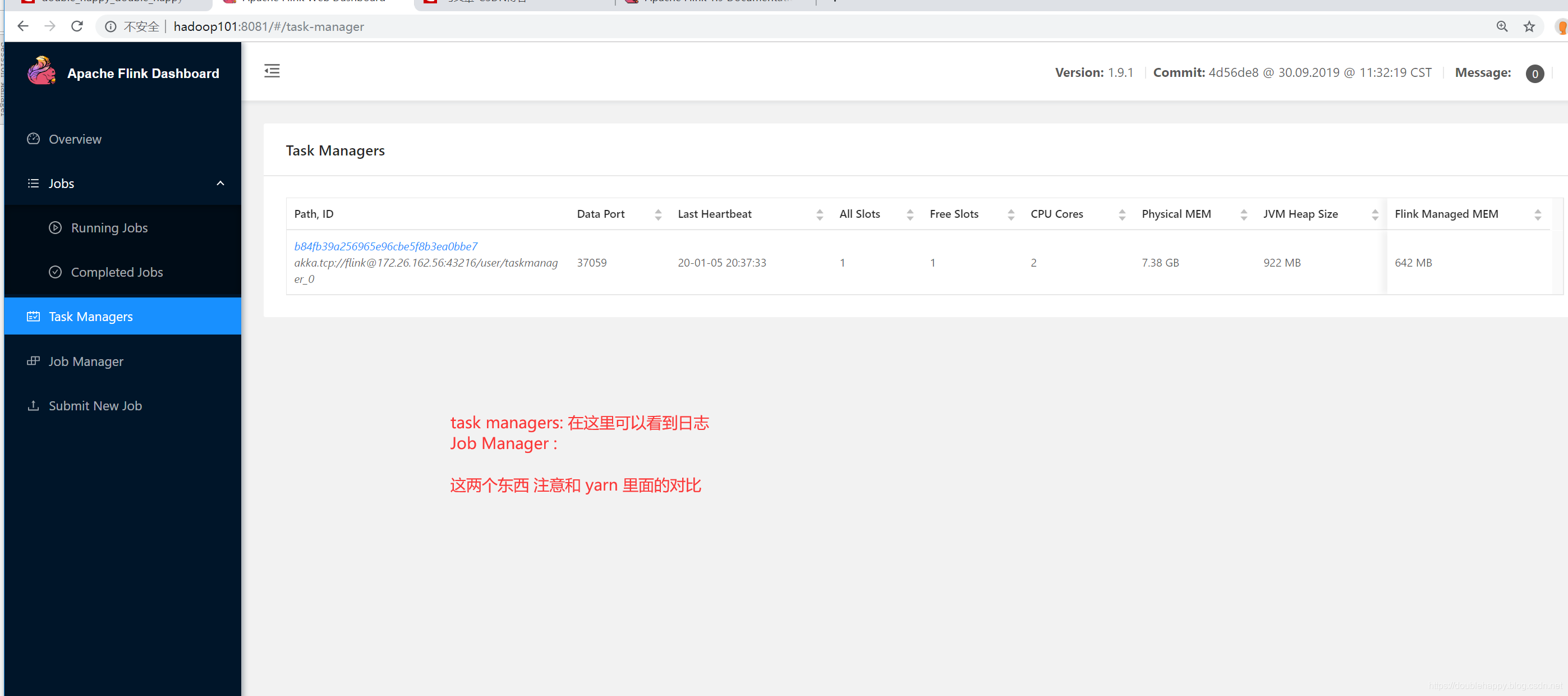
1 | 按照官网给的案例: |
1 | 1.启动 端口 nc :nc -lk 9998 |
1 | [double_happy@hadoop101 bin]$ ./flink |
1 | ./flink run [OPTIONS] <jar-file> <arguments> |
1 | 提交结果: |
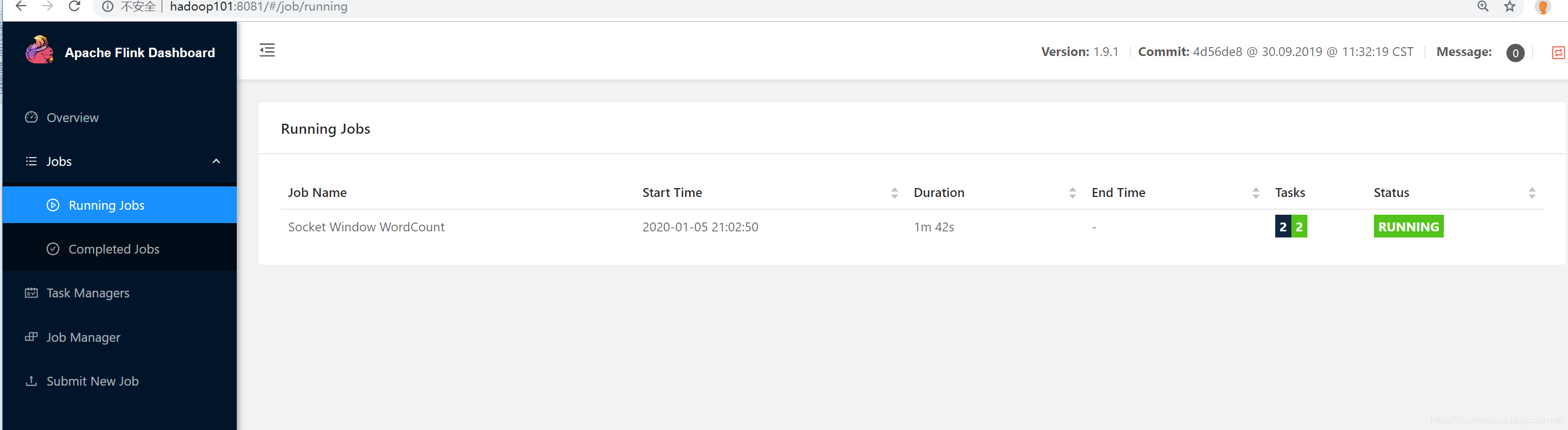
点进去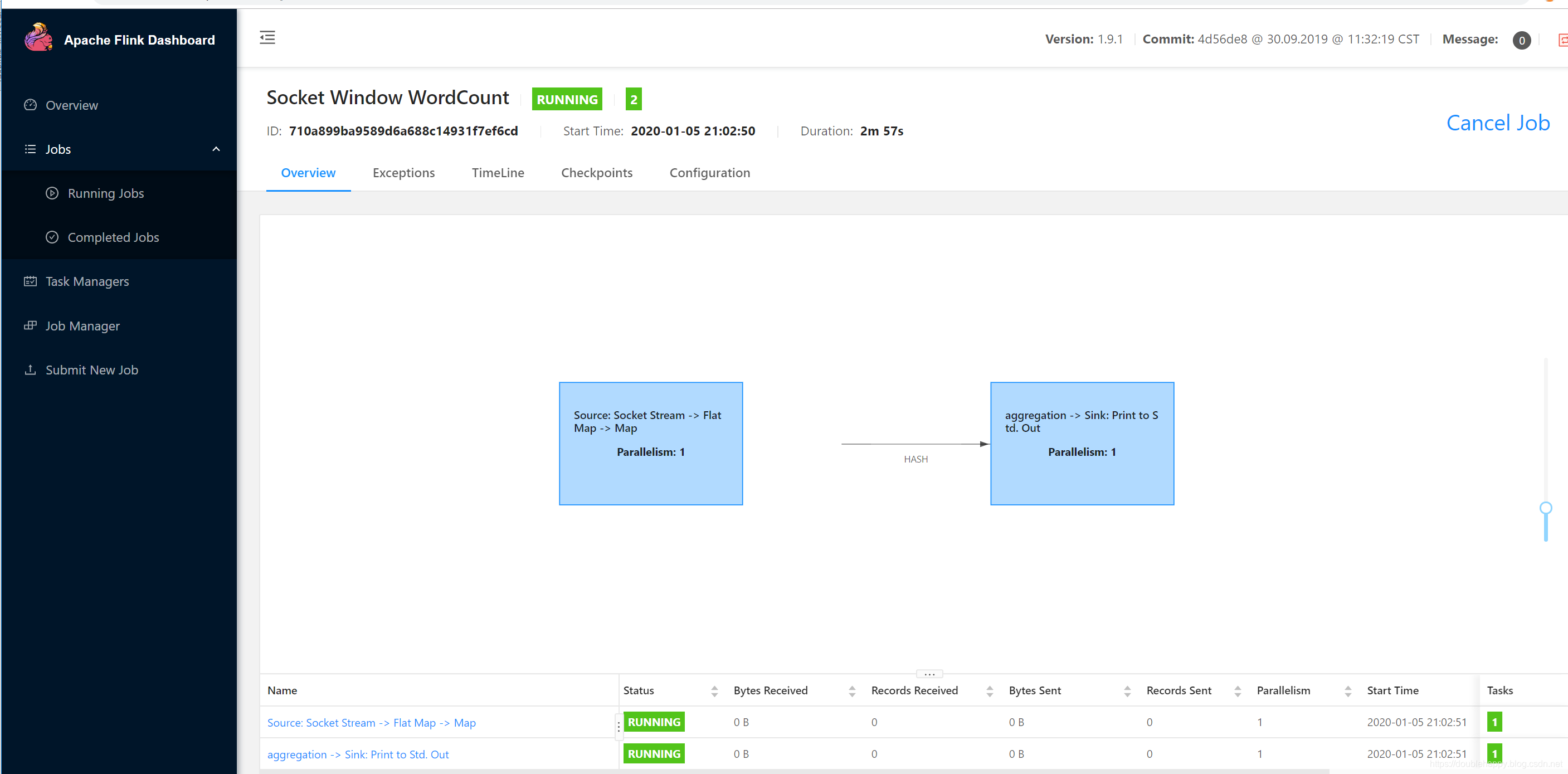
1 | nc 生产一些数据: |
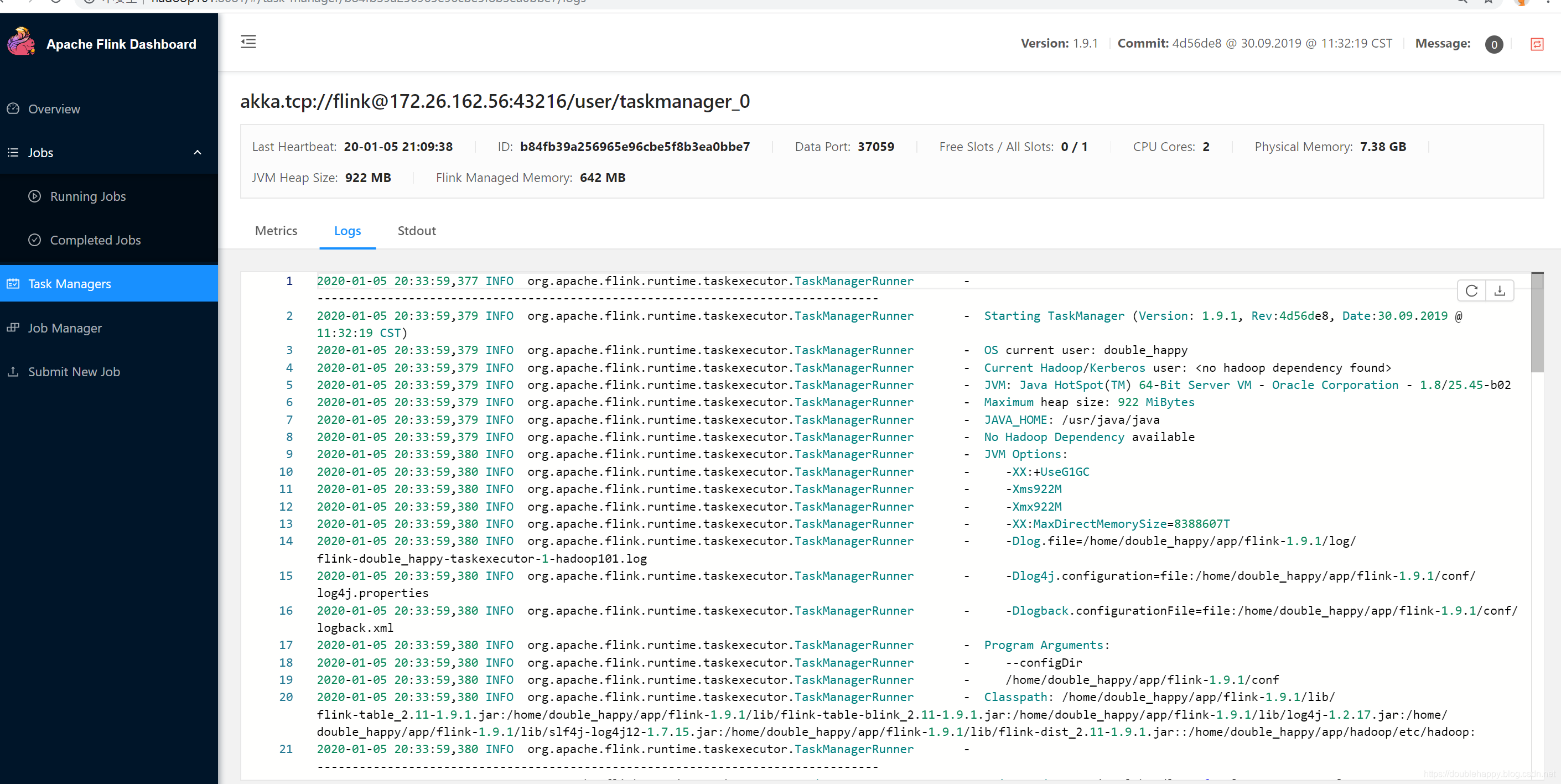
1 | 这些日志哪里来的? |
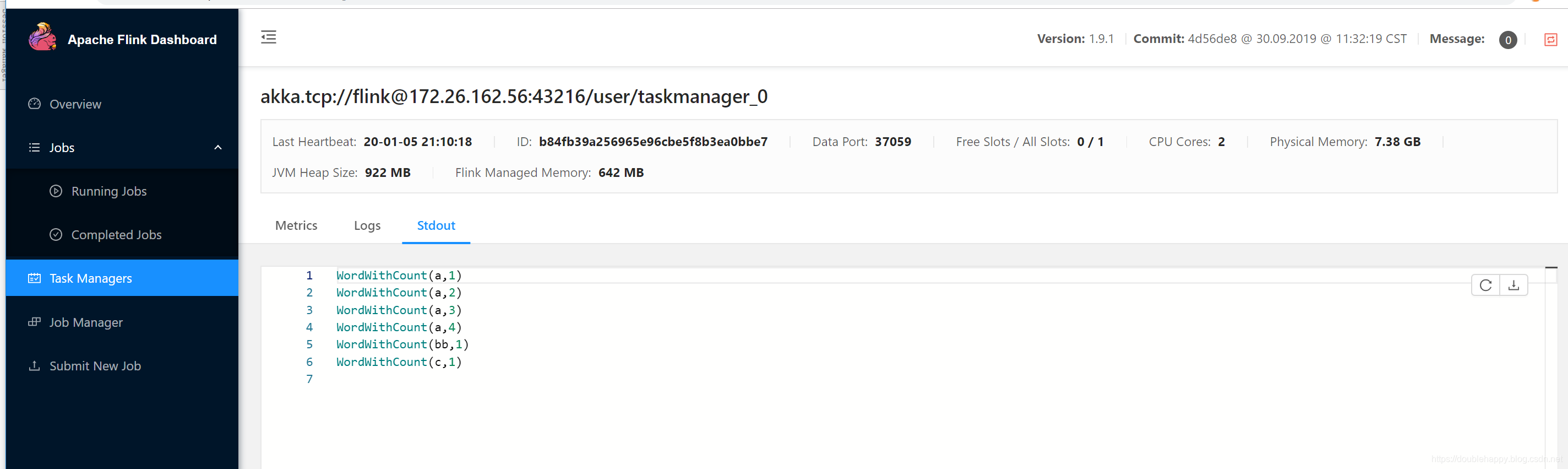
1 | 结果: |
1 | 本地查看: |
1 | 如何停止这个作业: |
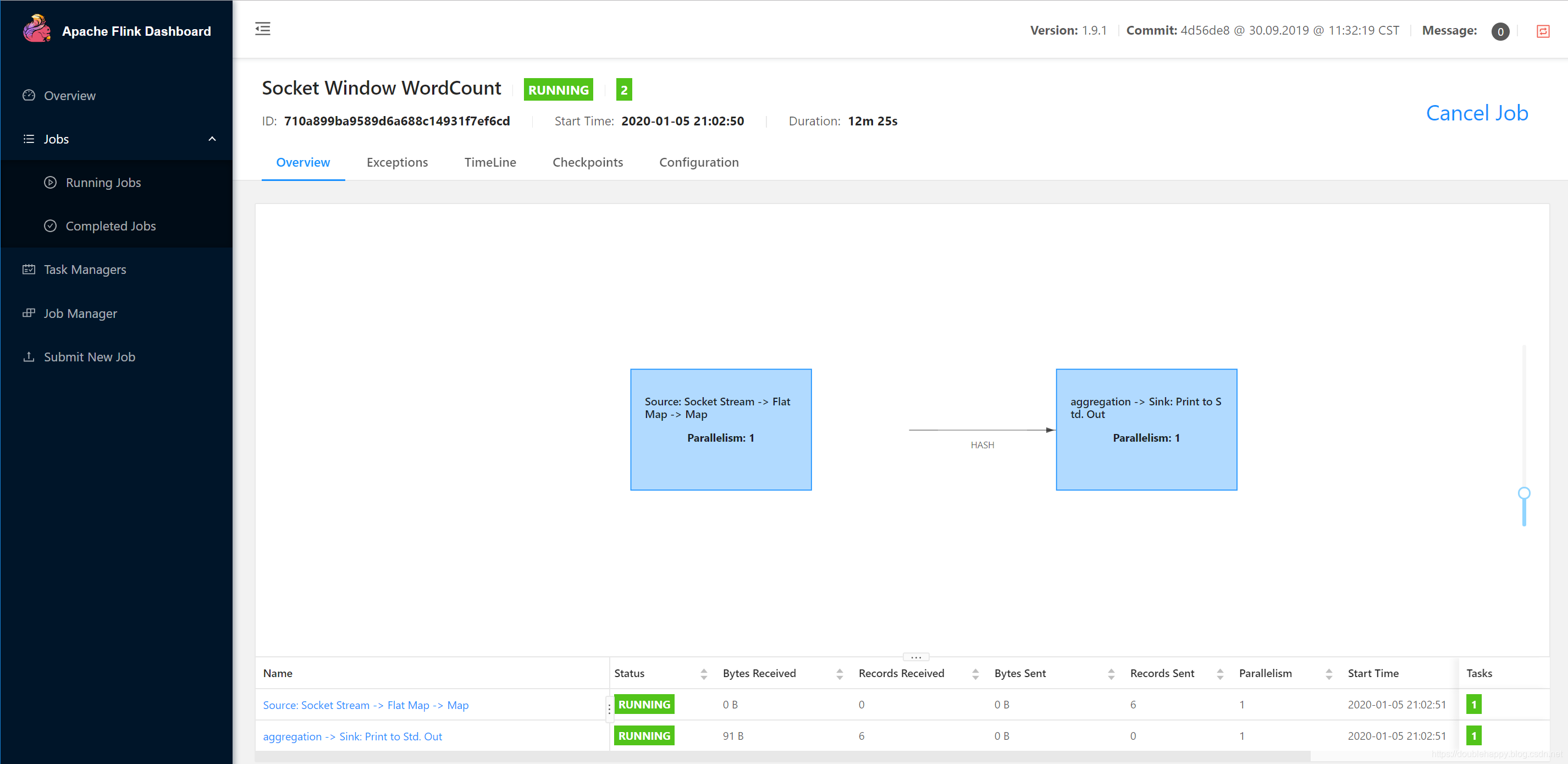
1 | 本地命令: |
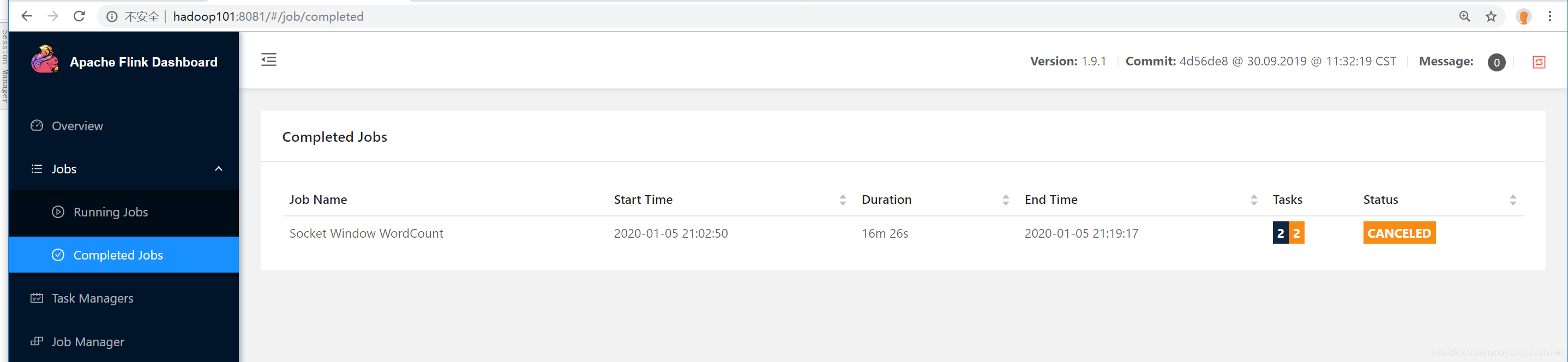
1 | 关闭集群: |
1 | 以上: |
对比Spark-shell
start-scala-shell.sh
1 | [double_happy@hadoop101 bin]$ ./start-scala-shell.sh |
1 | [double_happy@hadoop101 bin]$ ./start-scala-shell.sh local |
1 | 注意: |
1 | 批处理: |
跑在Yarn上 ***
1 | 面试题:谈谈你对Flink ON YARN执行流程的理解? |
YARN Setup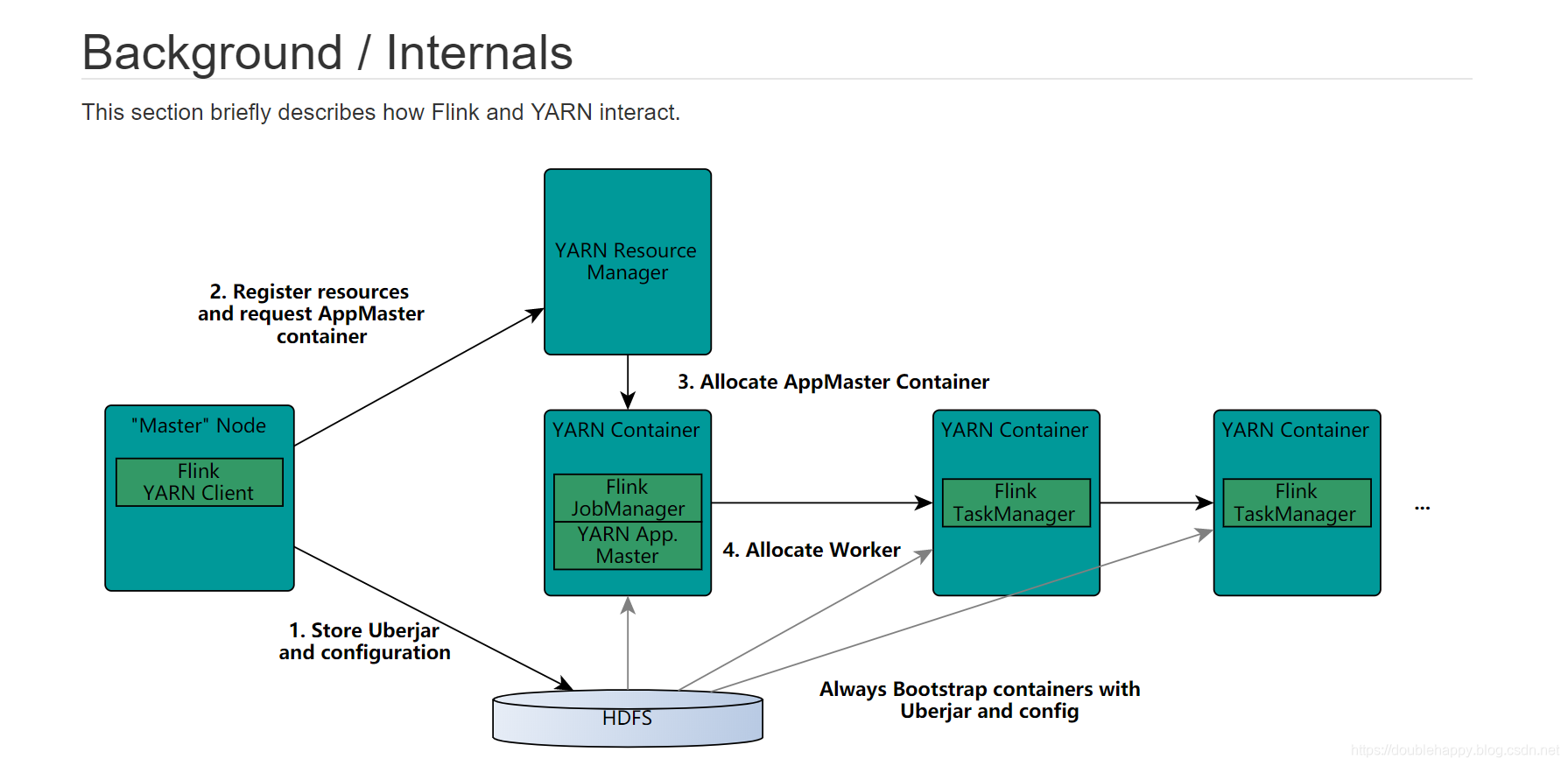
Background / Internals
1 | The YARN client needs to access the Hadoop configuration to connect to the YARN resource manager and HDFS |
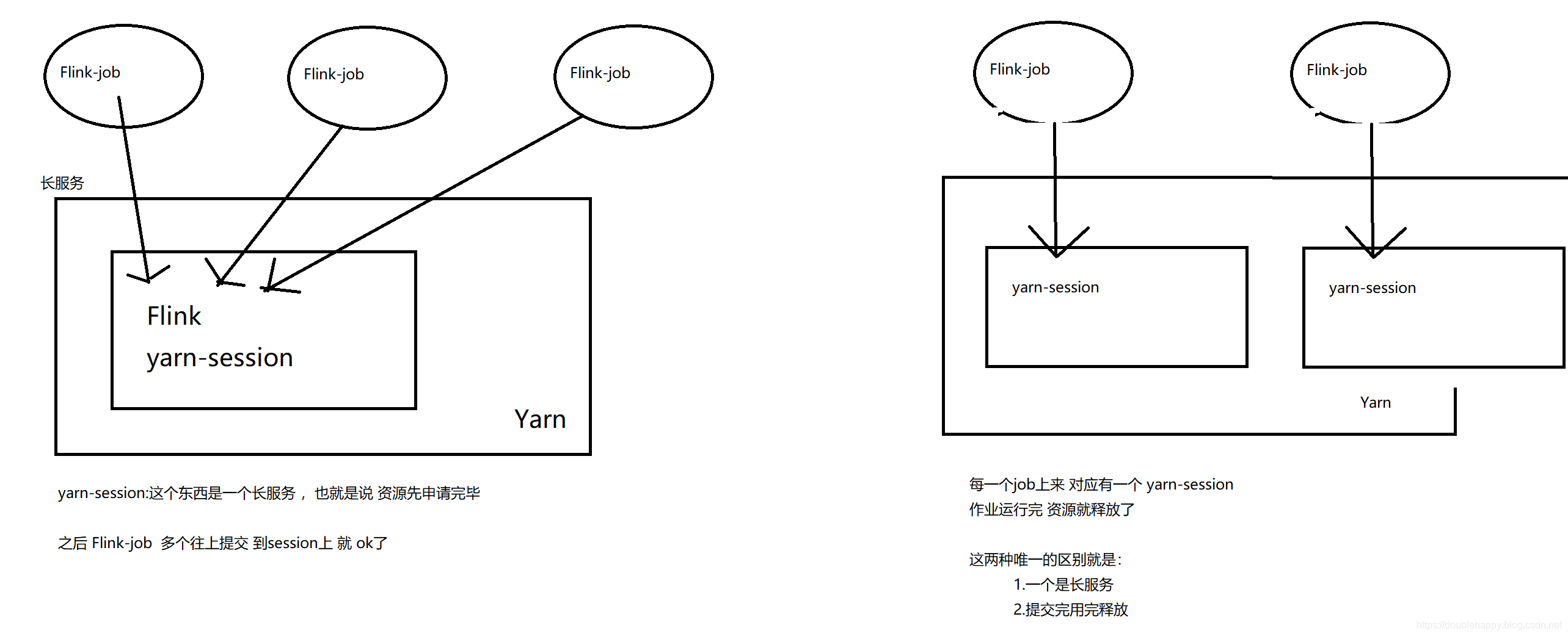
1 | Spark里面 就是 右边这种 |
两种方式分别演示
1 | ./yarn-session.sh 运行的时候有坑的 : |
1 | Required |
1 | 运行起来: |
去yarn 上查看: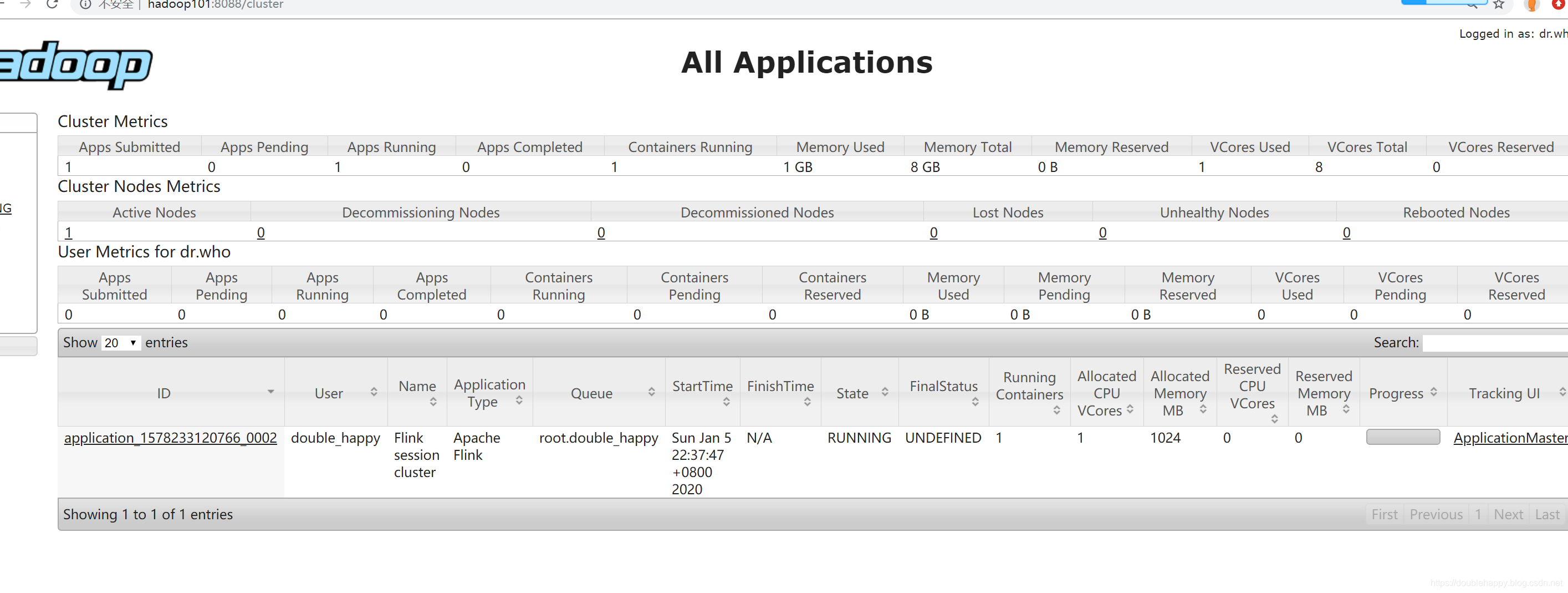
1 | 运行一个 例子试试: |
1 | [double_happy@hadoop101 data]$ hadoop fs -put ./LICENSE-2.0.txt /flink/input/ |
1 | 运行: |
1 | 结果: |
1 | 注意: |
Run a single Flink job on YARN
Run a single Flink job on YARN
1 | 官方案例: |
运行一下 之前的local的 程序:
1 | 运行一下 之前的local的 程序: |
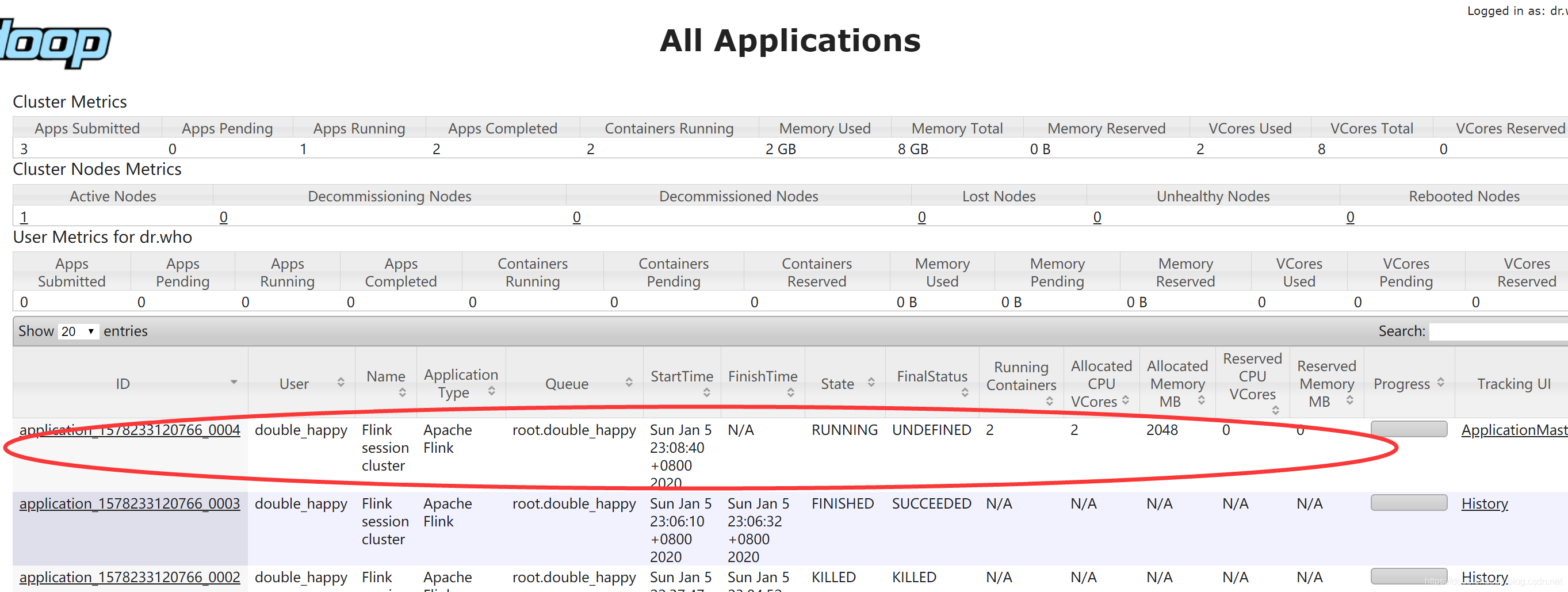
1 | 输入数据: |
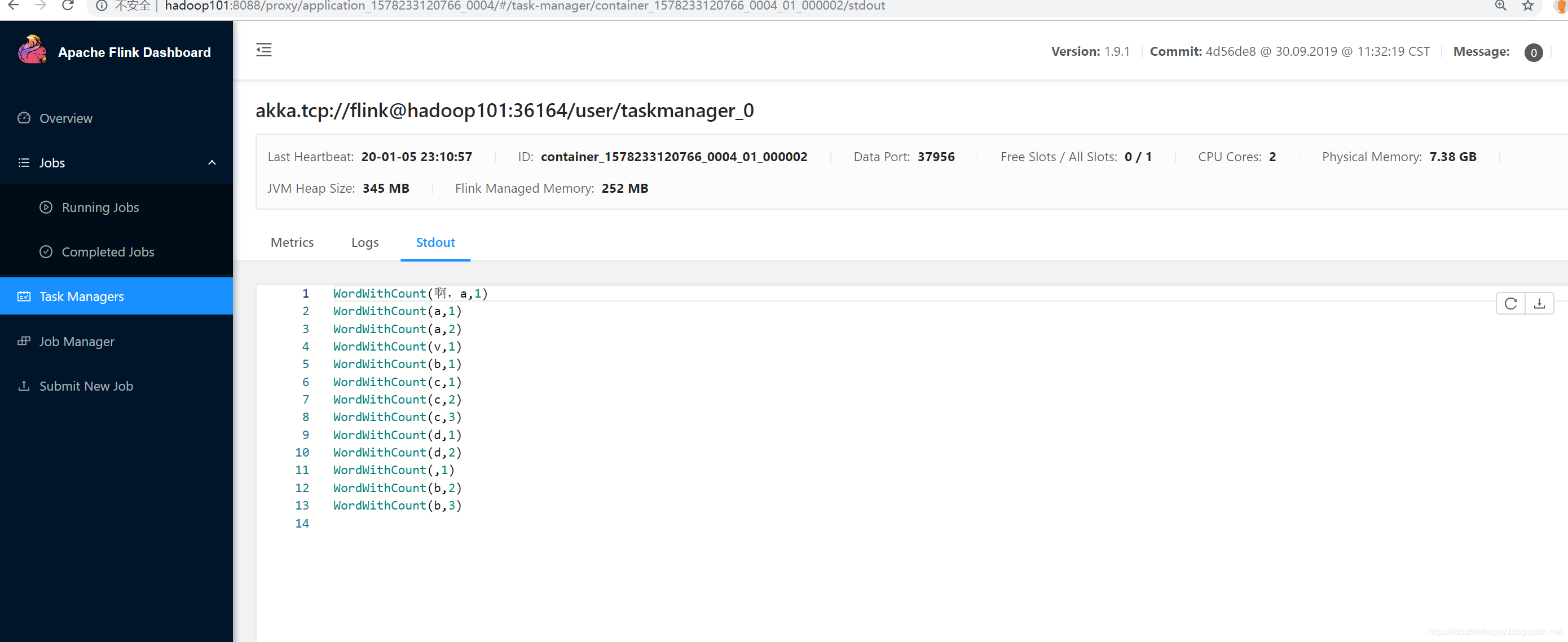
1 | 这是yarn的两种方式: |