概述
1 | Function |
1 | SourceFunction non-parallel 1 |
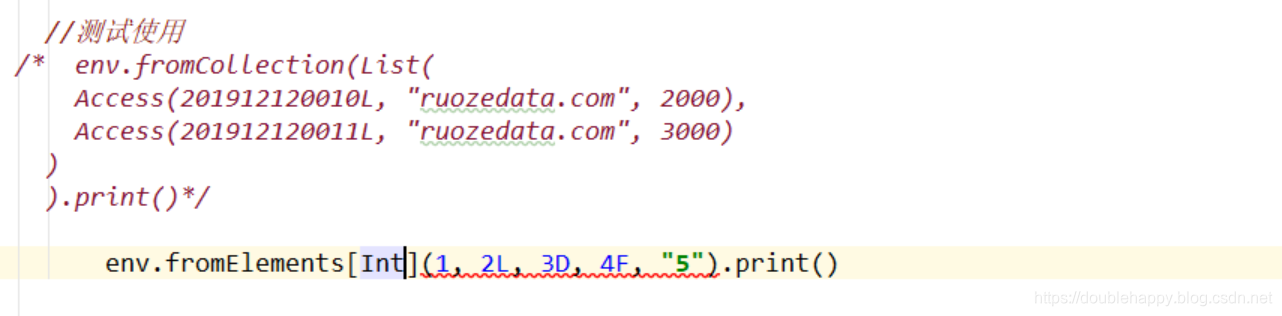
//测试使用
1 | object SourceApp { |
1 | /** |
1 | object SourceApp { |
Custom:
1 | env.addSource() |
1 | 1.SourceFunction |
这个很重要用于测试产生数据
1 | package com.sx.flink02 |
1 | object SourceApp { |
1 | 测试: |
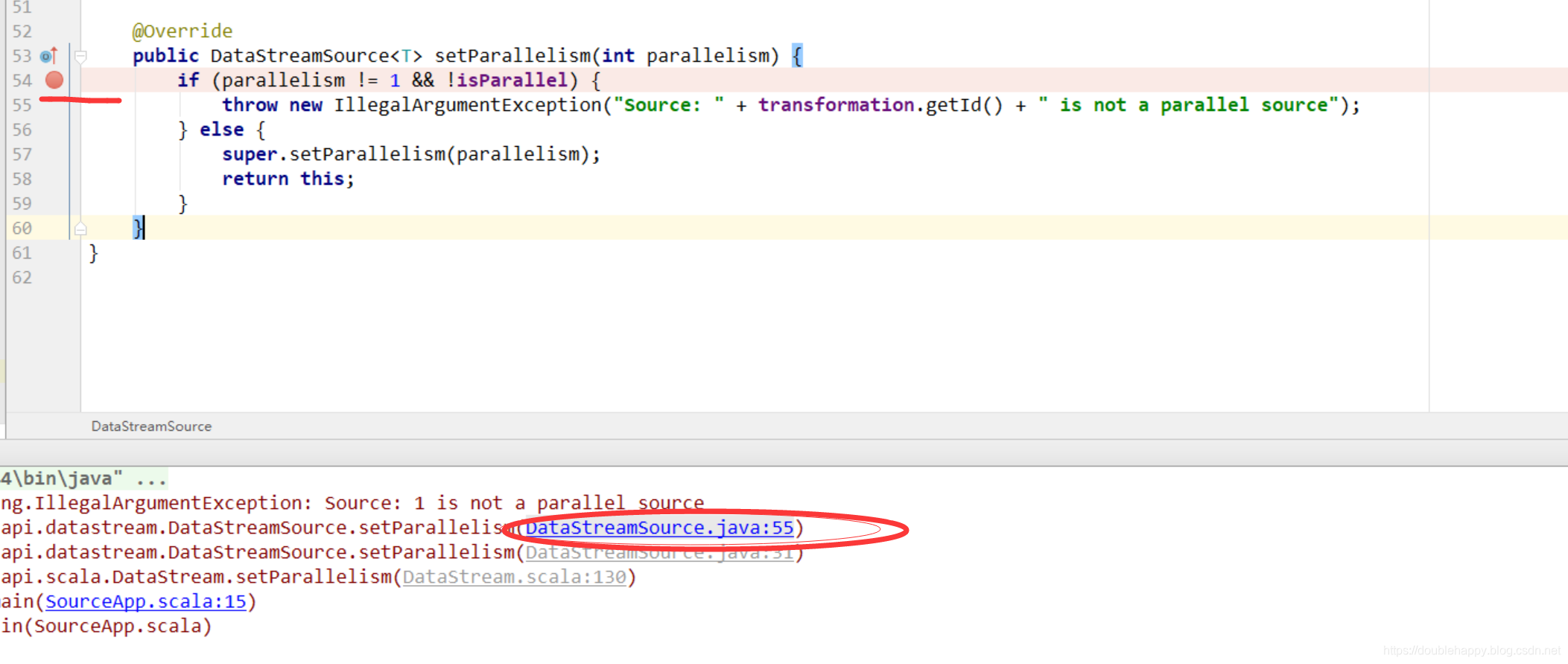
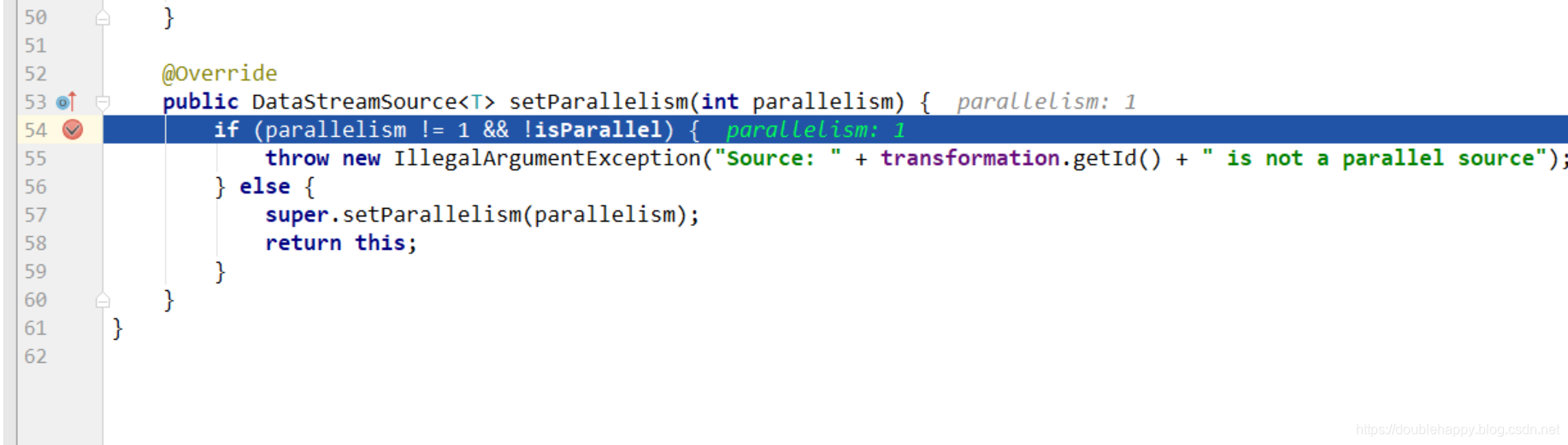
1 | 所以在大数据场景下 没有并行度 这个就不能用 |
1 | 2.ParallelSourceFunction 带并行度的 |
1 | object SourceApp { |
1 | 3.RichParallelSourceFunction **** |
1 | class AccessSource03 extends RichParallelSourceFunction[Access]{ |
1 | 上面就是 Source的最基本的使用 |
1 | 那么现在有一个需求: |
1 | MySQL里面的数据: |
1 |
|
1 | 注意: |
1 | object SourceApp { |
1 | class ScalikeJDBCMySQLSource extends RichSourceFunction[Student]{ |
读取kafka的数据
1 | 注意: |

1 | 但是在 0.11之后就统一了 |

1 | 我的kafka是 2.2.1系列的 |
1 | 所以我使用的 pom是: |
1 | Flink’s Kafka consumer is |
1 | /** |
1 | [double_happy@hadoop101 kafka]$ jps |
1 | 先开启: |
1 | 往kafka发送数据: |
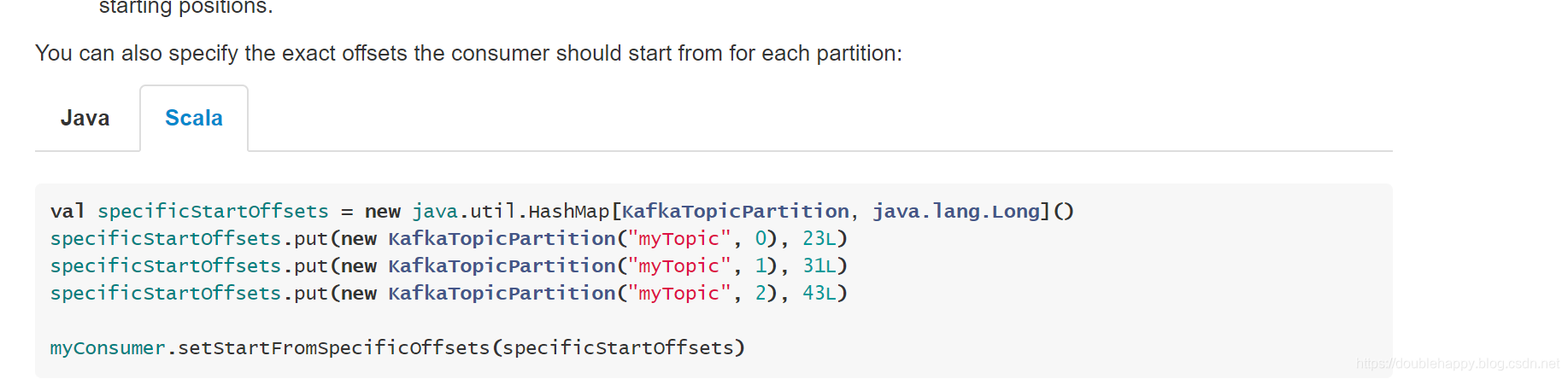
1 | Flink里面的kafka的offset 非常 好管理的 |
1 | val myConsumer = new FlinkKafkaConsumer08[String](...) |
1 | 那么先讲使用 里面的状态和checkpoint 容错等 后续写入文章 |
1 | object SourceApp { |
1 | 和Spark大部分都差不多 |
1 | object TranformationApp { |
1 | object TranformationApp { |
分流:
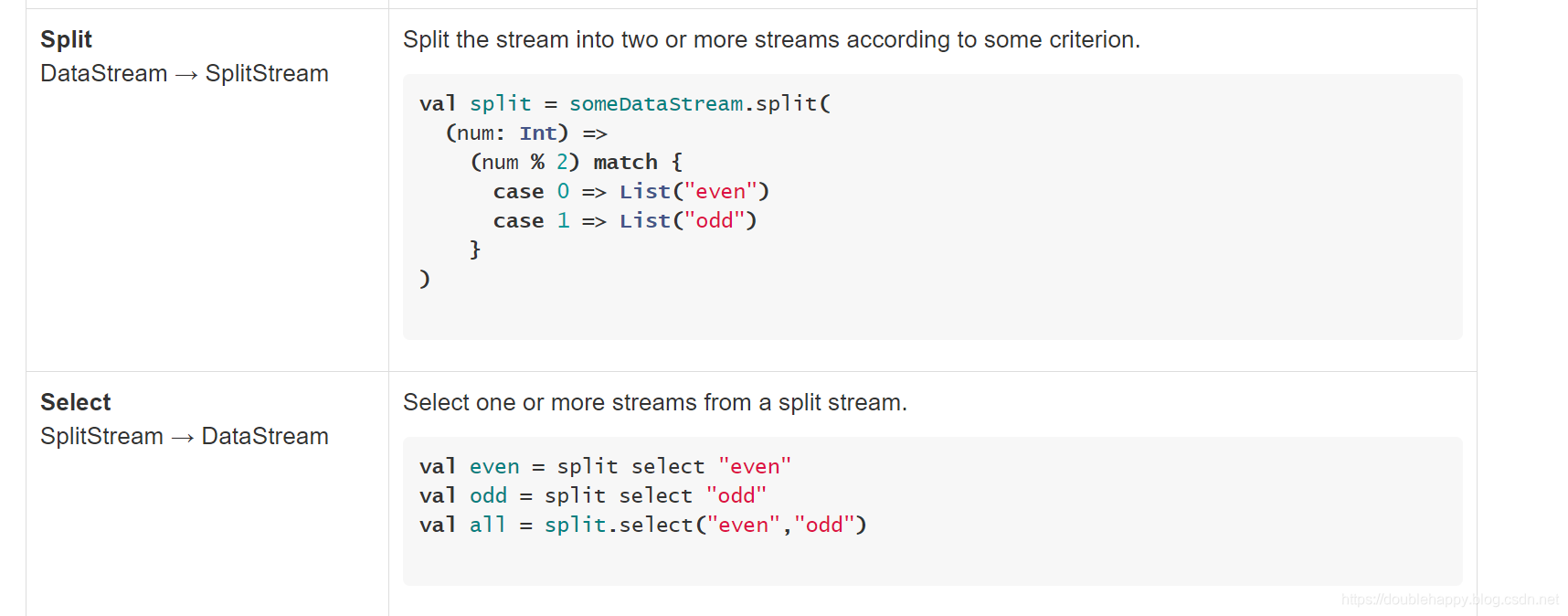
1 | 这个功能 可能会用的到: |
合流
1 | 两个流是可以合的 : |
1 | /** |
1 | 两个流 数据类型不一样的: |
1 | object TranformationApp { |
1 | connect: |
1 | class DoubleHappyPartitioner extends Partitioner[String]{ |
1 | /** |
1 | object TranformationApp { |
1 | 注意:线程 |