介绍
1 | Stateful Computations over Data Streams |
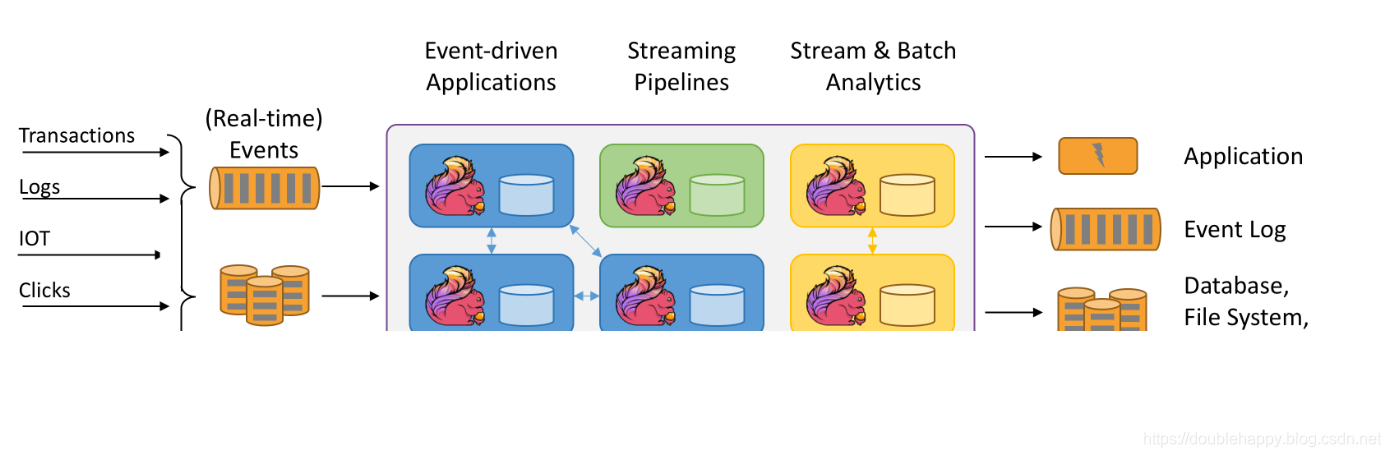
Run Applications at any Scale
Flink is designed to run stateful streaming applications at any scale. Applications are parallelized into possibly thousands of tasks that are distributed and concurrently executed in a cluster. Therefore, an application can leverage virtually unlimited amounts of CPUs, main memory, disk and network IO. Moreover, Flink easily maintains very large application state. Its asynchronous and incremental checkpointing algorithm ensures minimal impact on processing latencies while guaranteeing exactly-once state consistency.
Users reported impressive scalability numbers for Flink applications running in their production environments, such as
applications processing multiple trillions of events per day,
applications maintaining multiple terabytes of state, and
applications running on thousands of cores
1 | maintaining multiple terabytes of state: |
1 | pom.xml: |
1 | 批处理: |
1 | [double_happy@hadoop101 ~]$ nc -lk 7777 |
1 | [double_happy@hadoop101 ~]$ nc -lk 7777 |
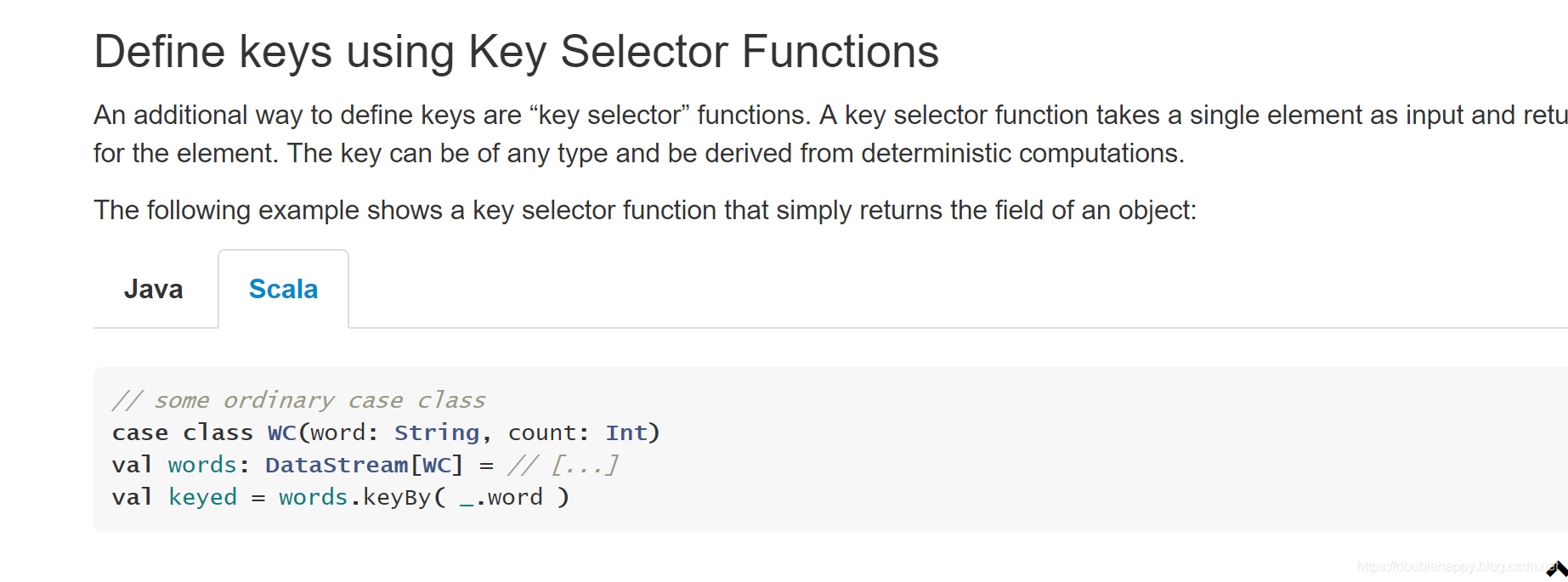
使用字段表达式
1 | package com.sx.flink01 |


依赖

1 | At the bare minimum, the application depends on the Flink APIs. Many applications depend in addition on certain connector libraries (like Kafka, Cassandra, etc.) |
Specifying Transformation Functions
1 | package com.sx.bean |
1 | package com.sx.flink01 |
1 | 需求1 |
1 | 方式1:Lambda Functions |
1 | 方式二: |
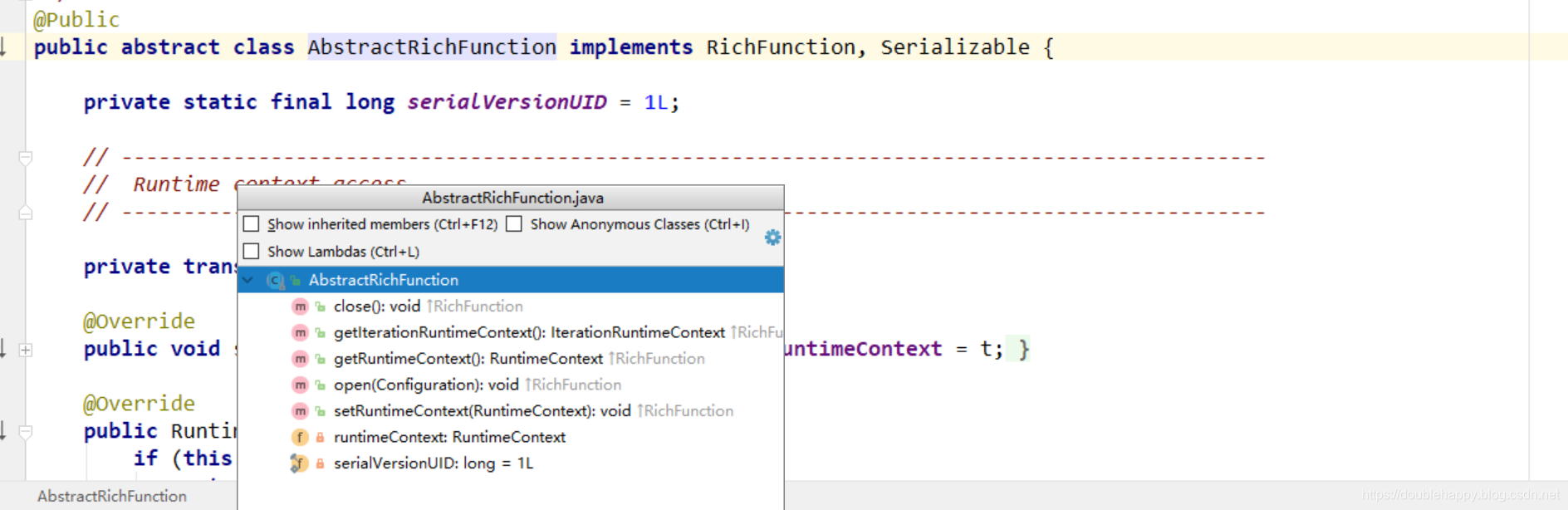
这里面的生命周期函数
1 | RichXXXFunction |
1 | 方式3:Rich functions |