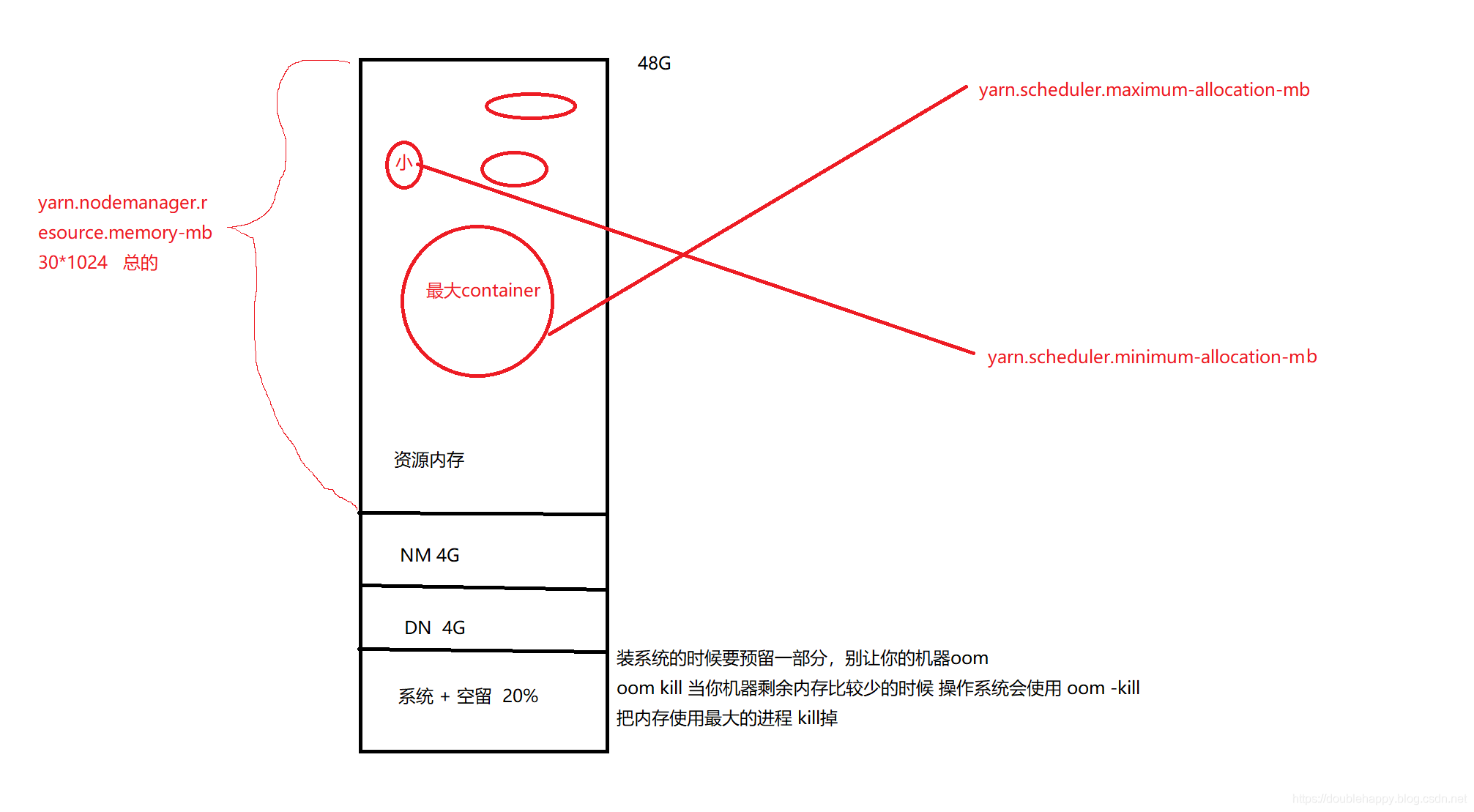
雅恩资源调优---double_happy 2018-03-17 本文总阅读量次 1一台机器能运行多少个container 到底是由谁决定的 ? 官网 123456789101112131415161718192021222324252627282930生产上一台机器: 48G物理内存 8core--》16vcore Linux系统本身要占内存+空留: 20% =9.6G 剩余: 80% =38.4G=38G 这些留给大数据组件 DN进程: 生产4G 1000m hadoop-env.sh HADOOP_NAMENODE_OPTS=-Xmx1024m HADOOP_DATANODE_OPTS=-Xmx1024m NM进程: 生产4G yarn-env.sh export YARN_RESOURCEMANAGER_HEAPSIZE=1024 export YARN_NODEMANAGER_HEAPSIZE=1024NM 与DN 部署在同一台机器上: 数据本地化NN RM 经常性部署同一台 说白了 集群节点少*****资源内存: 38G-4-4=30G 这就是运行container容器 的 yarn.nodemanager.resource.memory-mb 30*1024 总的 默认配置yarn.scheduler.minimum-allocation-mb 1024 给容器最小的 内存 生产上 2gyarn.scheduler.maximum-allocation-mb 8192 给容器最大的 内存 生产上 30g按照官网默认的算:30G 30G/1G=30个container 30G 30/8G=3个container ...6G 这里面 30这个值不好 30/8 还剩6g 32g 比较好 30个~3个 内存: 12345678910生产一: yarn.nodemanager.resource.memory-mb 30Gyarn.scheduler.minimum-allocation-mb 2Gyarn.scheduler.maximum-allocation-mb 30G2g--》 yarn给你分配的时候先给你最小的 当计算过程中发现内存不够了 yarn会给你长一个g15个~1个30G 是不是太大了 根据你作业来分的 你作业就是需要30g 你只能给30g 12345678生产二:yarn.nodemanager.resource.memory-mb 32Gyarn.scheduler.minimum-allocation-mb 2Gyarn.scheduler.maximum-allocation-mb 8G16c~4c如果container memory oom 那么调大yarn.scheduler.maximum-allocation-mb 这个 先把oom这个进程kill掉 12345678910111213141516171819生产三:256G:yarn.nodemanager.resource.memory-mb 168Gyarn.scheduler.minimum-allocation-mb 4Gyarn.scheduler.maximum-allocation-mb 24Gcontainer p memory oom kill生产默认 yarn.nodemanager.pmem-check-enabled true //物理内存yarn.nodemanager.vmem-check-enabled true yarn.nodemanager.vmem-pmem-ratio 2.1 //物理内存 和虚拟内存的比例 物理内存 1m 虚拟内存 2.1m这两个内存超了 都会抱 oom cpu 123456789101112131415CPU:yarn.nodemanager.resource.cpu-vcores 12yarn.scheduler.minimum-allocation-vcores 1yarn.scheduler.maximum-allocation-vcores 4container: memory 16c~4c vcores 12c~3c 所以这个两个变量cpu 和 mem 你应该怎么调 才能 资源最大化呢? 到底是根据mem 来算 还是 core来算呢? 已加密 SparkSQL--TextFile输出多列 SS04