1 | 之前的ss程序都是运行在idea |
1 | 数据从Kafka过来然后 ss消费到 把wc统计出来: |
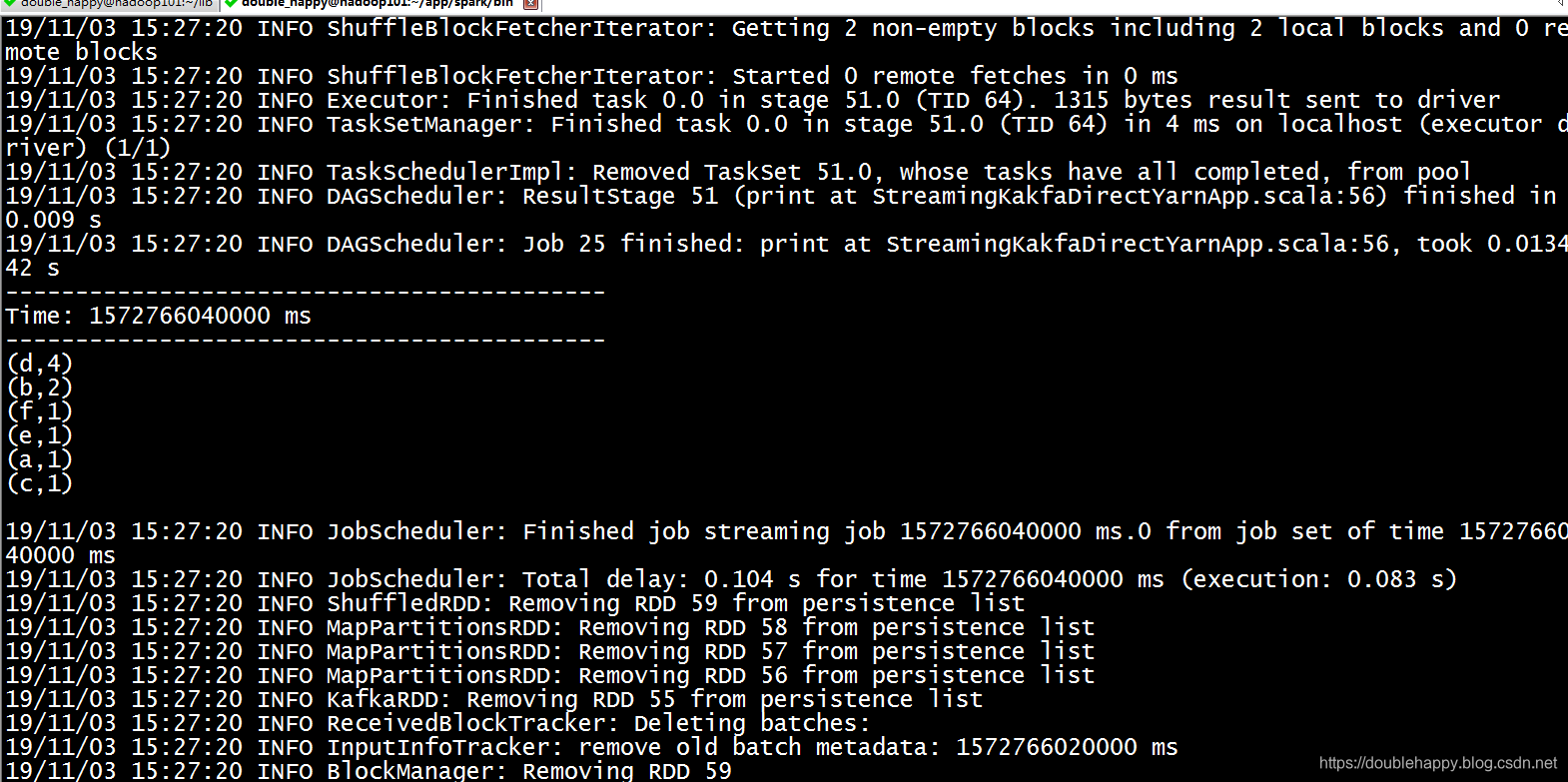
1 | 运行结果: |
1 | 提交命令: |
1 | [double_happy@hadoop101 bin]$ ./spark-submit \ |
1 | 注意: |
Deploying:部署
As with any Spark applications, spark-submit is used to launch your application.
For Scala and Java applications, if you are using SBT or Maven for project management, then package spark-streaming-kafka-0-10_2.12 and its dependencies into the application JAR. Make sure spark-core_2.12 and spark-streaming_2.12 are marked as provided dependencies as those are already present in a Spark installation. Then use spark-submit to launch your application (see Deploying section in the main programming guide).
这种方式不好 换一个
1 | 因为需要把这个spark-streaming-kafka-0-10_2.11包 传到服务器上 |
1 | 那么刚刚packages 有小问题 那么怎么办呢 ? |
1 | 注意: |
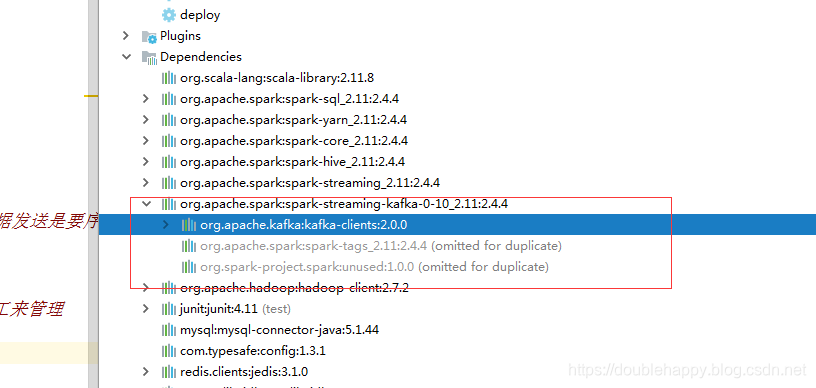
1 | 因为sparkStreaming-kafka包里面包含kafka-client |
1 | [double_happy@hadoop101 bin]$ ./spark-submit --master local[2] --name StreamingKakfaDirectYarnApp --jars /home/double_happy/lib/spark-streaming-kafka-0-10_2.11-2.4.4.jar,/home/double_happy/lib/kafka-clients-2.0.0.jar --class com.ruozedata.spark.ss04.StreamingKakfaDirectYarnApp /home/double_happy/lib/spark-core-1.0.jar hadoop101:9092,hadoop101:9093,hadoop101:9094 double_happy_offset double_happy_group3 |
transformation
1 | 之前写的算子 都是按照每一个批次来处理的 或者是可以累计的等 |
Window Operations
As shown in the figure, every time the window slides over a source DStream, the source RDDs that fall within the window are combined and operated upon to produce the RDDs of the windowed DStream. In this specific case, the operation is applied over the last 3 time units of data, and slides by 2 time units. This shows that any window operation needs to specify two parameters.
window length - The duration of the window (3 in the figure).
sliding interval - The interval at which the window operation is performed (2 in the figure).
These two parameters must be multiples of the batch interval of the source DStream (1 in the figure).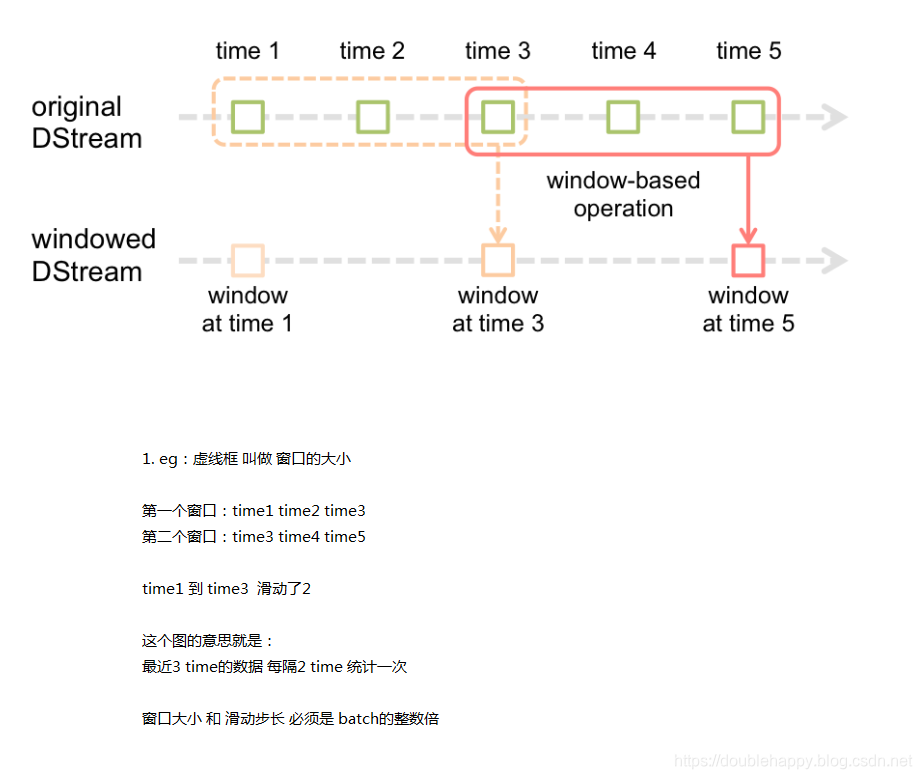
案列
1 | /** |
1 | 5秒的批次 每隔5秒统计前10秒 |
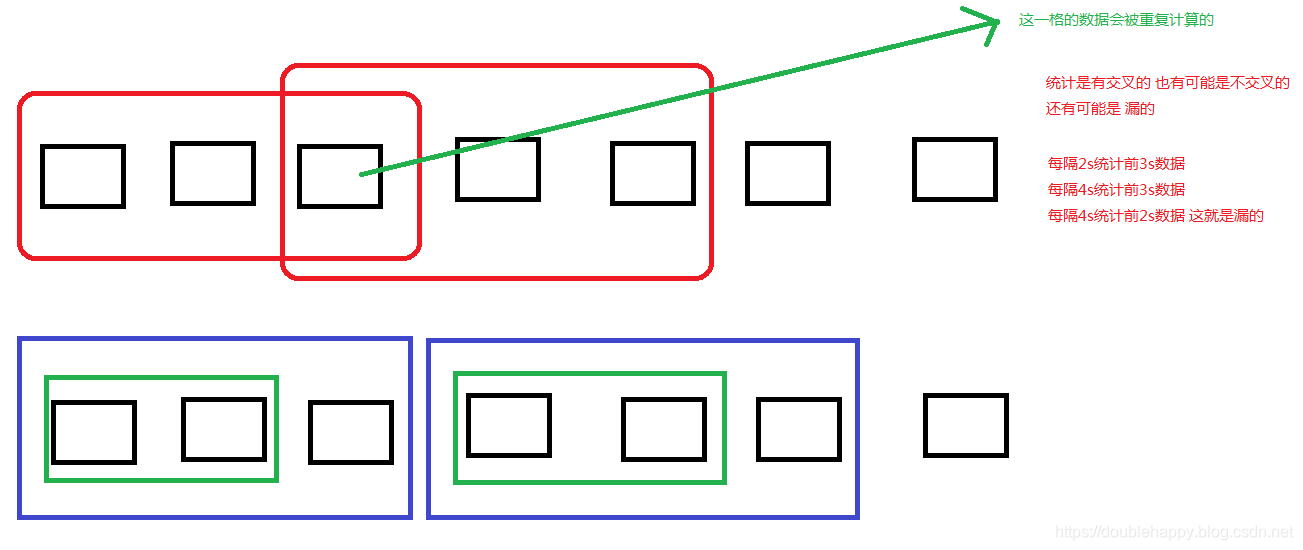
DataFrame and SQL Operations
DataFrame and SQL Operations
这是批流一体带来的非常大的好处
1 | object StreamingSqlApp { |
消费语义****
Definitions
The semantics of streaming systems are often captured in terms of how many times each record can be processed by the system. There are three types of guarantees that a system can provide under all possible operating conditions (despite failures, etc.)
1.At most once: Each record will be either processed once or not processed at all.
2.At least once: Each record will be processed one or more times. This is stronger than at-most once as it ensure that no data will be lost. But there may be duplicates.
3.Exactly once: Each record will be processed exactly once - no data will be lost and no data will be processed multiple times. This is obviously the strongest guarantee of the three.
1 | 1.流系统中 你的数据被处理了多少次 根据处理多少次 分为三大类 |
Semantics of output operations
Output operations (like foreachRDD) have at-least once semantics, that is, the transformed data may get written to an external entity more than once in the event of a worker failure. While this is acceptable for saving to file systems using the saveAsFiles operations (as the file will simply get overwritten with the same data), *additional effort may be necessary to achieve exactly-once semantics. There are two approaches.
1.Idempotent updates: Multiple attempts always write the same data. For example, saveAs*Files** always writes the same data to the generated files.
2.Transactional updates: All updates are made transactionally so that updates are made exactly once atomically. One way to do this would be the following.
Use the batch time (available in foreachRDD) and the partition index of the RDD to create an identifier. This identifier uniquely identifies a blob data in the streaming application.
Update external system with this blob transactionally (that is, exactly once, atomically) using the identifier. That is, if the identifier is not already committed, commit the partition data and the identifier atomically. Else, if this was already committed, skip the update.
1 | dstream.foreachRDD { (rdd, time) => //time就是你当前批次的时间 |
1 | Output operations (like foreachRDD) have at-least once semantics |
调优 ****
1 | 1.减少每隔批次处理的时间 |
1 | object StreamingTuningApp { |
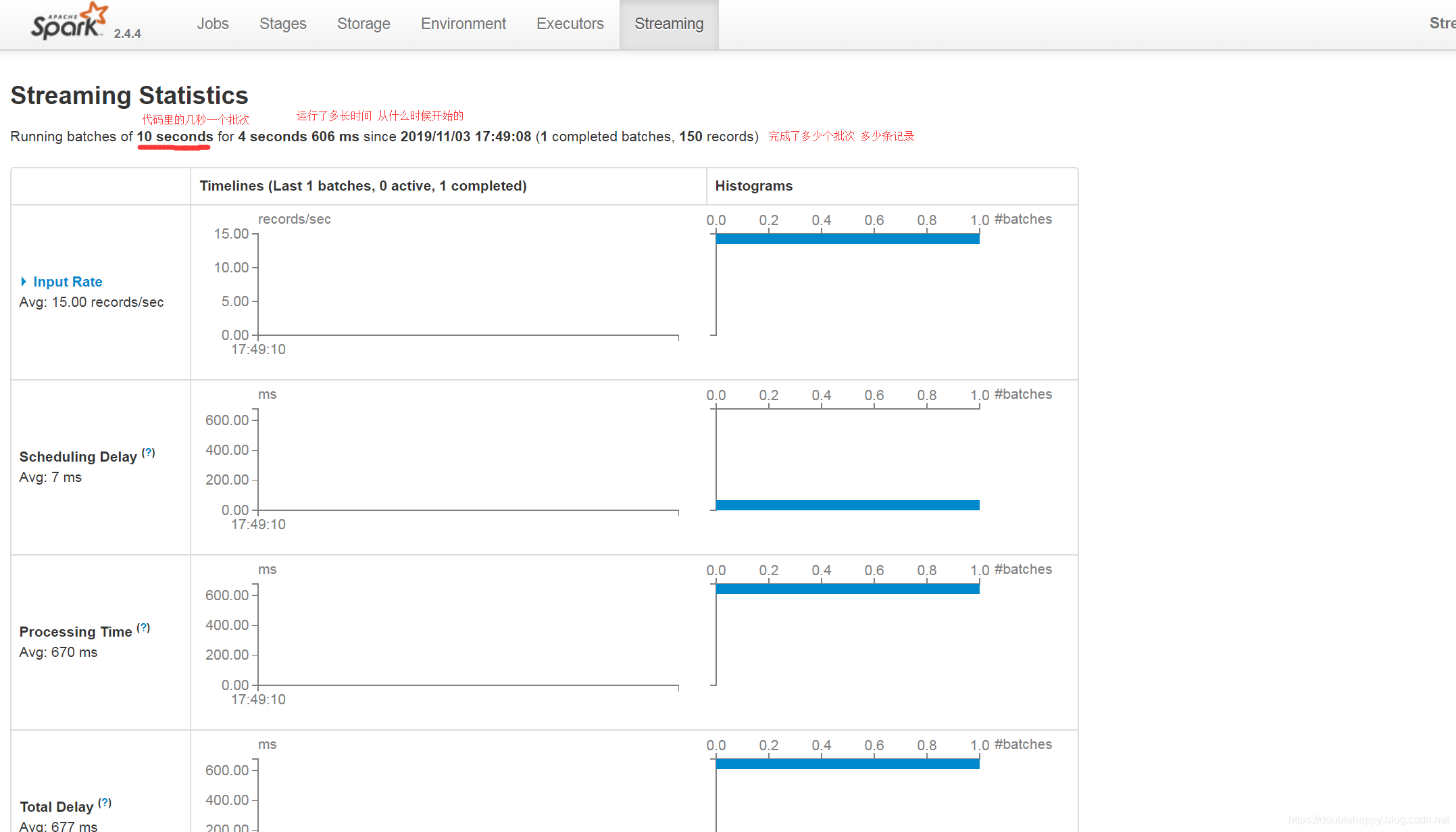
华丽——————————————————————————————————
1 | ok 我们往kafka写10条数据 |
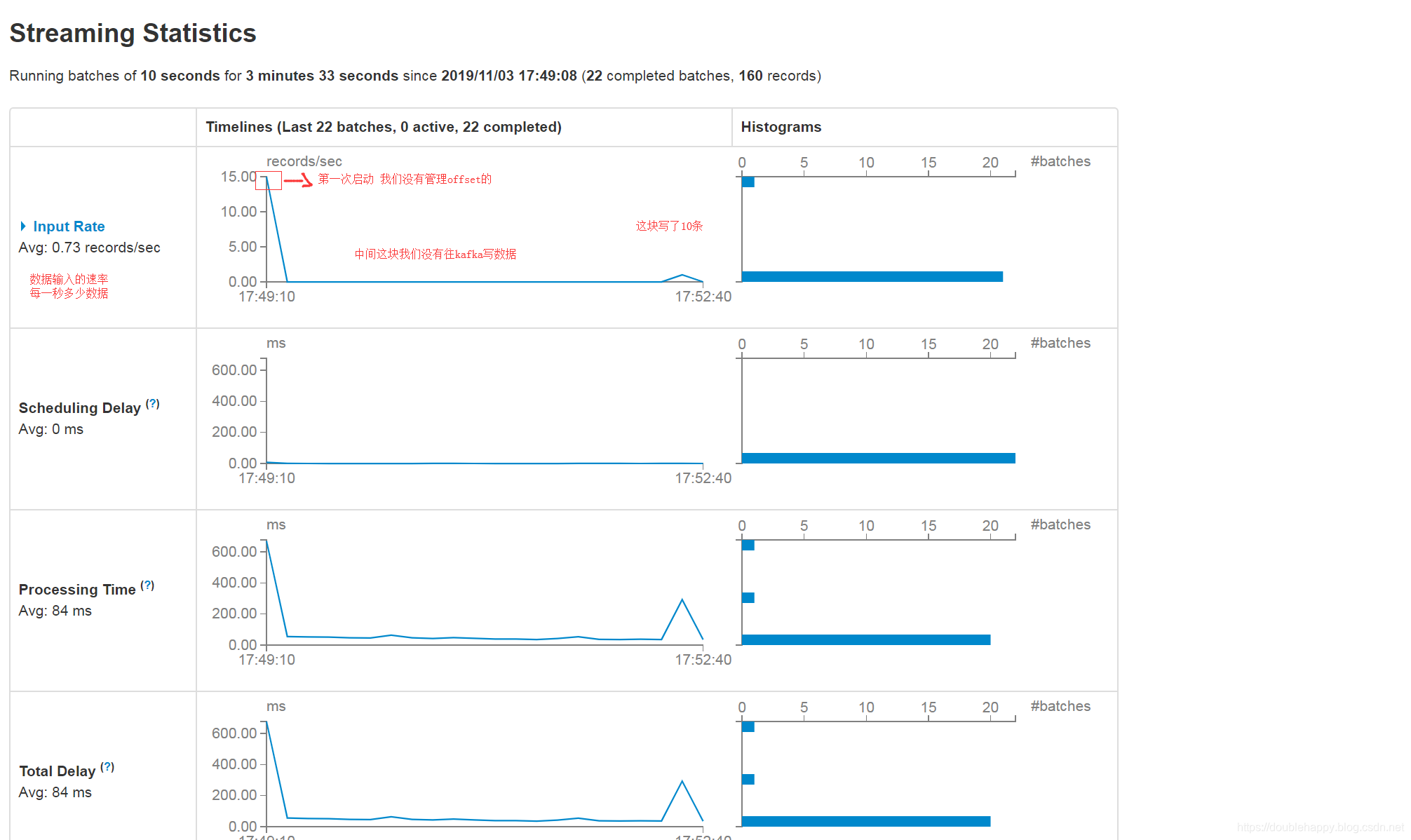
华丽——————————————————————————————————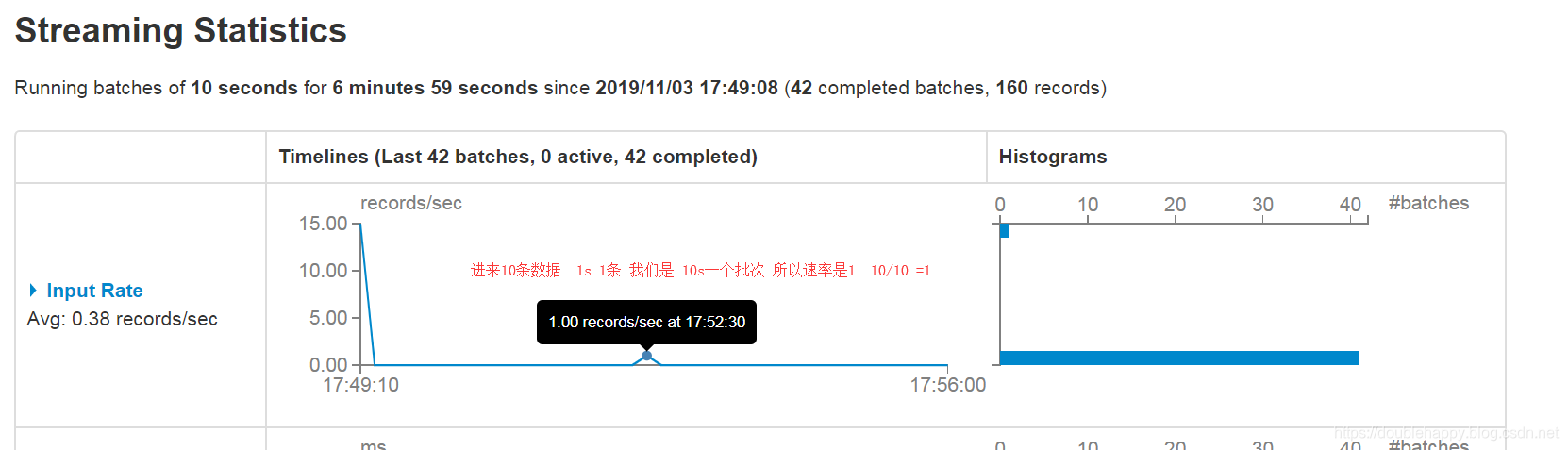
华丽——————————————————————————————————
1 | Input Rate:数据输入的速率 |
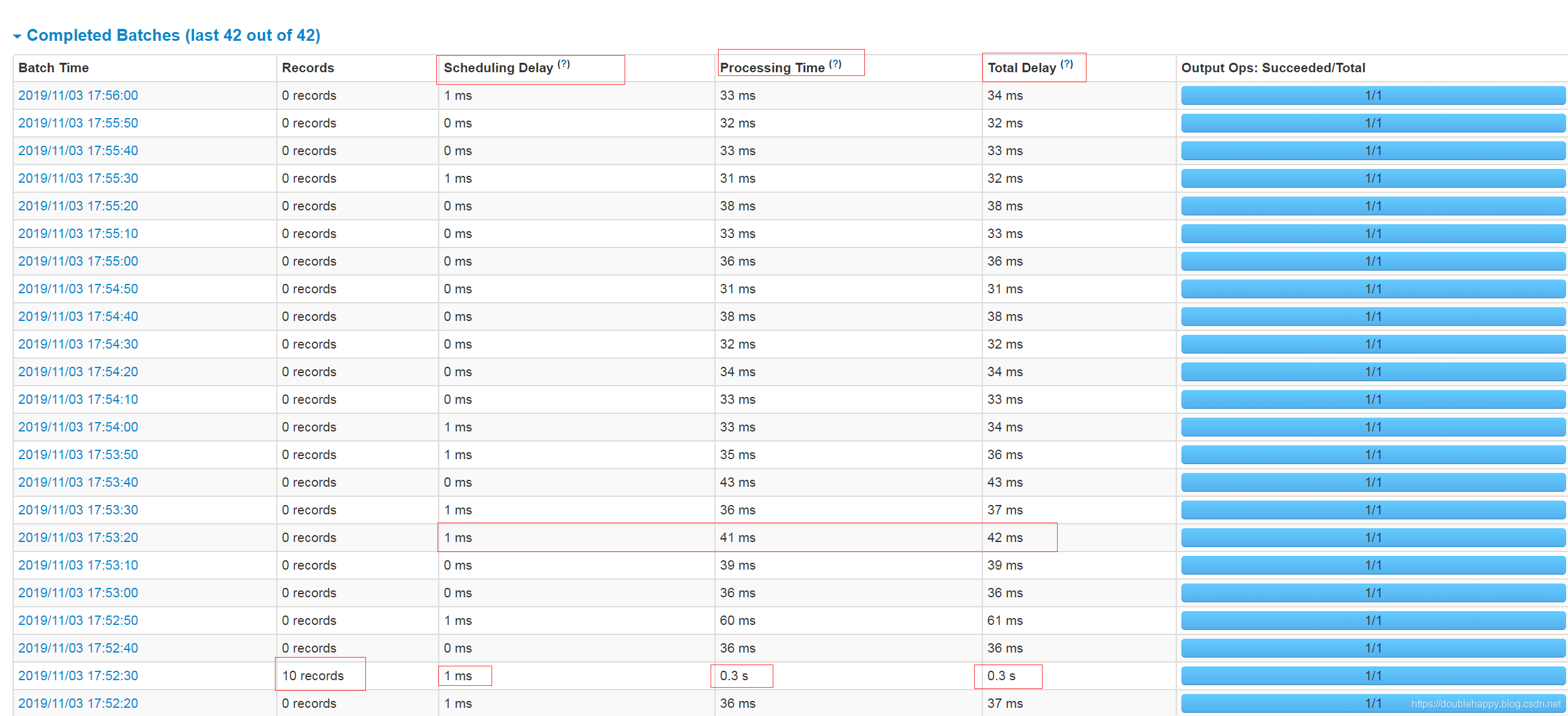
1 | 最佳实践: |
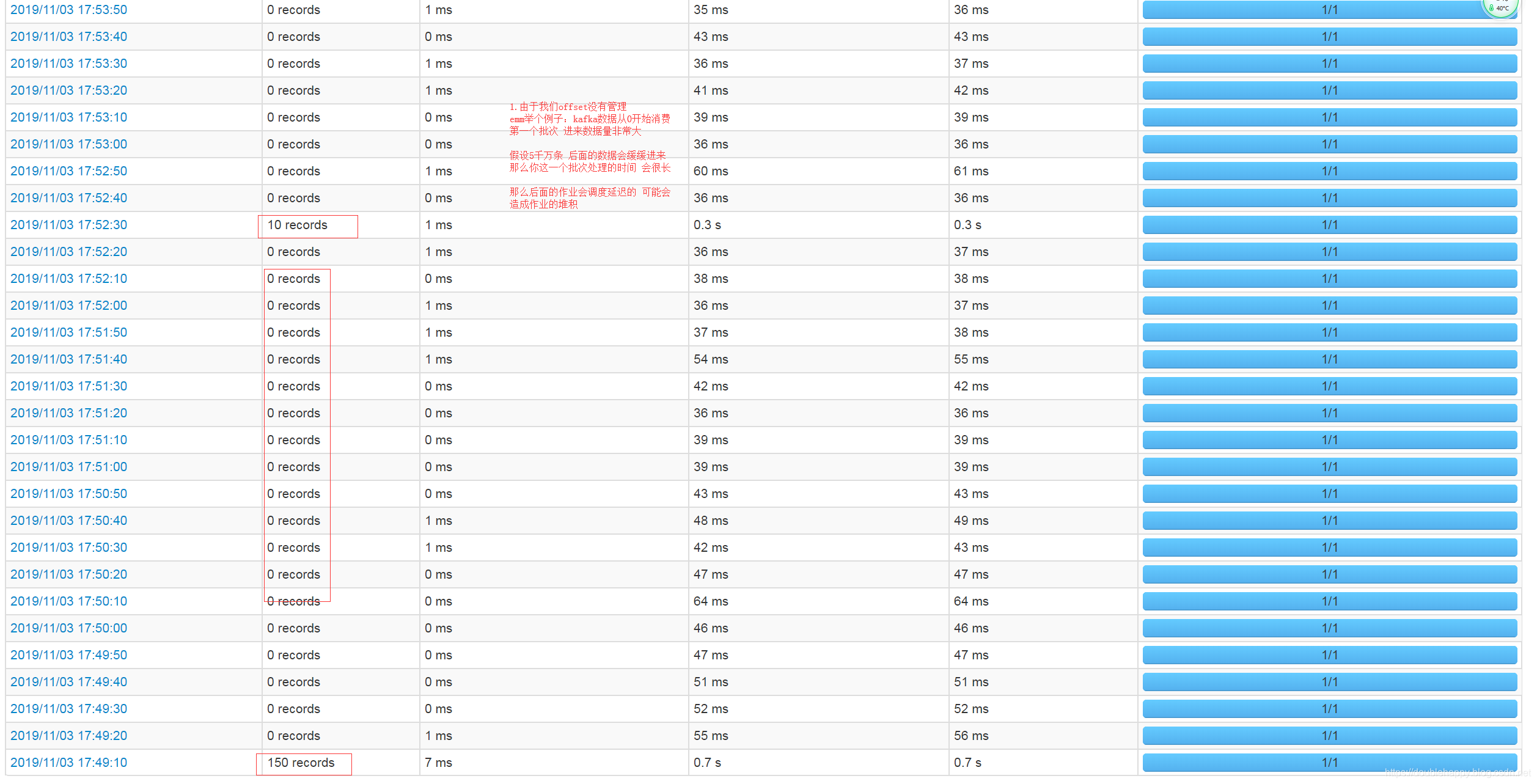
1 | 这个地方kafka是有一个限速的 |
1 | 修改代码: |
1 | 先测试没有修改前的: |
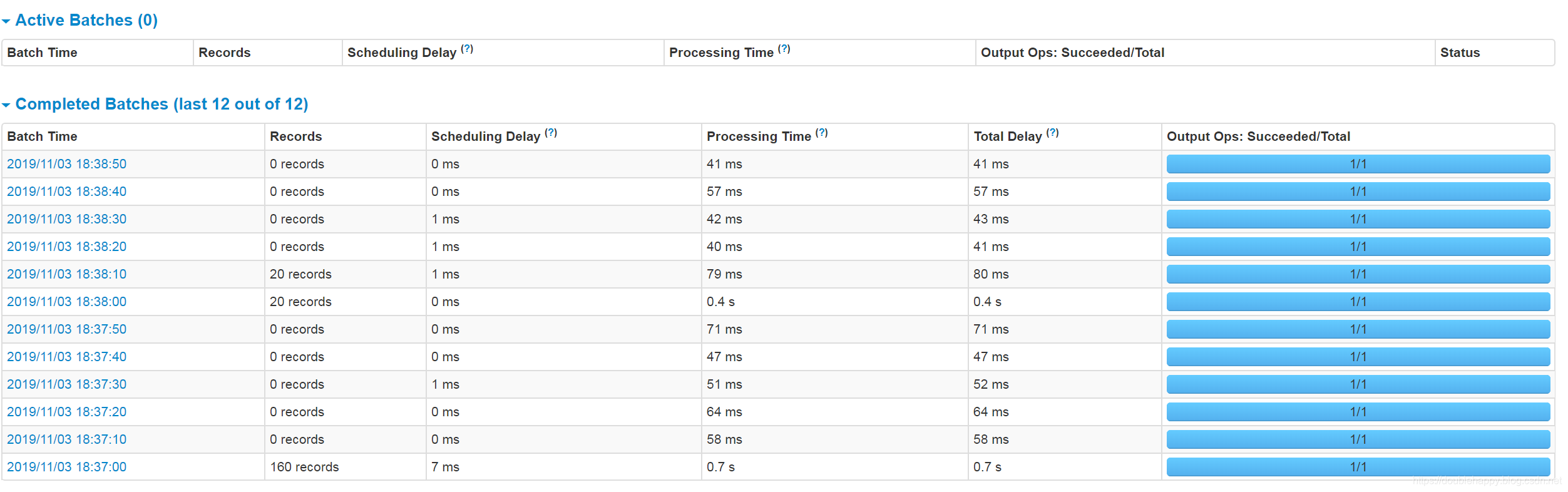
1 | 测试修改后的 |

1 | 说明这个参数没有生效 emm |
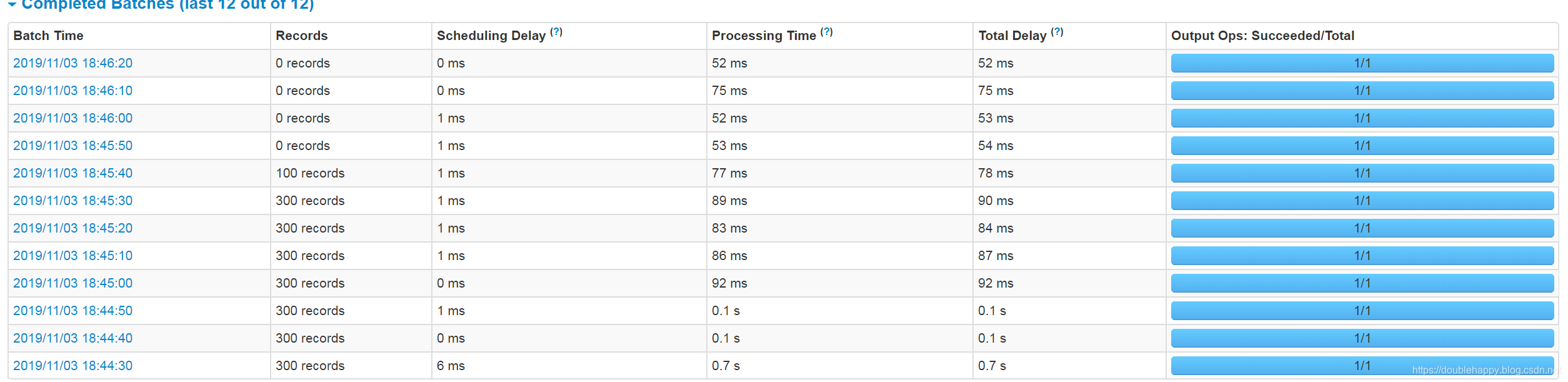
1 | 看 说面限速成功了 这样第一次处理就很好的限制你能处理的范围内 |
1 | 背压机制 : backpressure 1.5版本引进来的 |
1 | 背压:它是根据当前批次决定后一个批次 |

1 | 如果按照官方这个描述 数据是从receiver过来的 |
1 | 我设置为150 |

不能使用
1 | 那么该怎么办呢? 自己找找答案 |
优雅的关闭JVM
1 | spark.streaming.stopGracefullyOnShutdown |
1 | def getStreamingContext(appname: String, batch: Int, defalut: String = "local[2]") = { |