1 | 批流一体:未来的发展趋势 |
1 | Spark Streaming provides two categories of built-in streaming sources. |
1 | Some of these advanced sources are as follows. |
Kafka整合
Spark Streaming + Kafka Integration Guide
The Kafka project introduced a new consumer API between versions 0.8 and 0.10, so there are 2 separate corresponding Spark Streaming packages available. Please choose the correct package for your brokers and desired features; note that the 0.8 integration is compatible with later 0.9 and 0.10 brokers, but the 0.10 integration is not compatible with earlier brokers.
1 | 1.高阶Api |
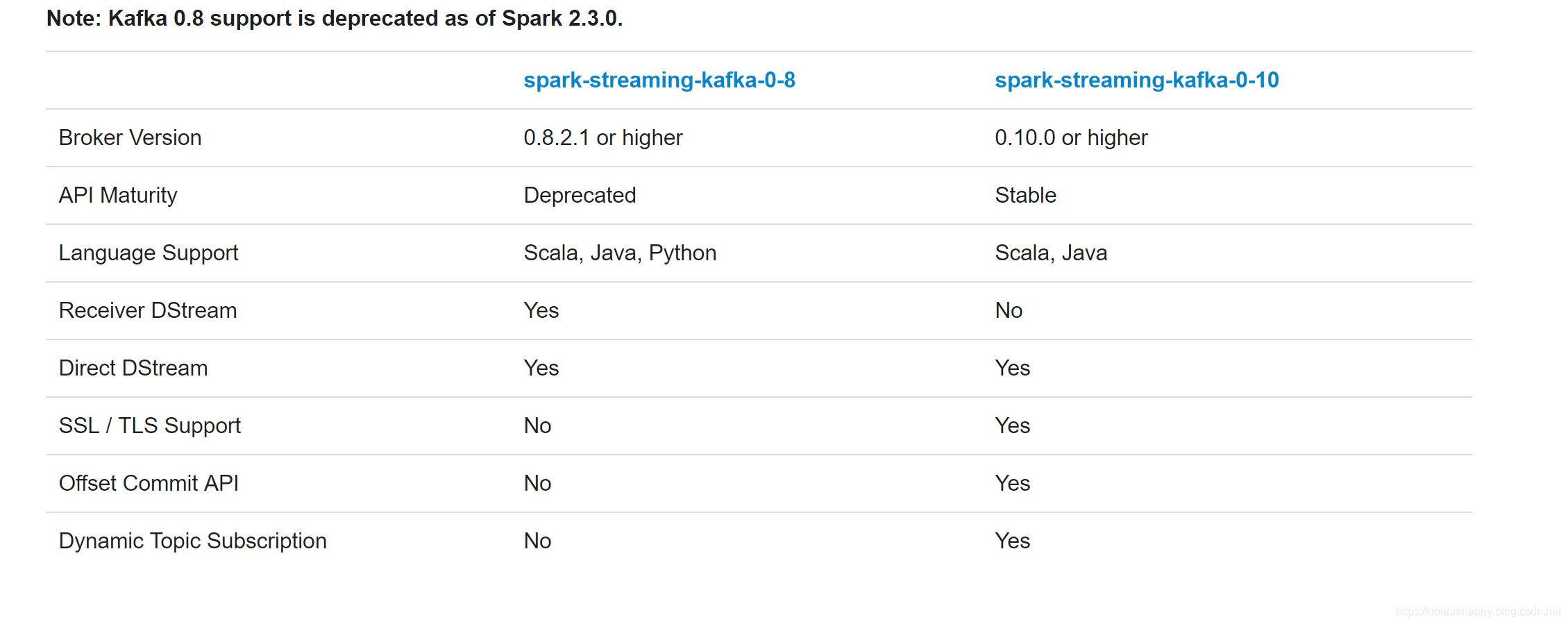
1 | 一定要用这个: |
1 | spark-streaming-kafka-0-8: |
华丽的分割线———————————————————————————————————————-
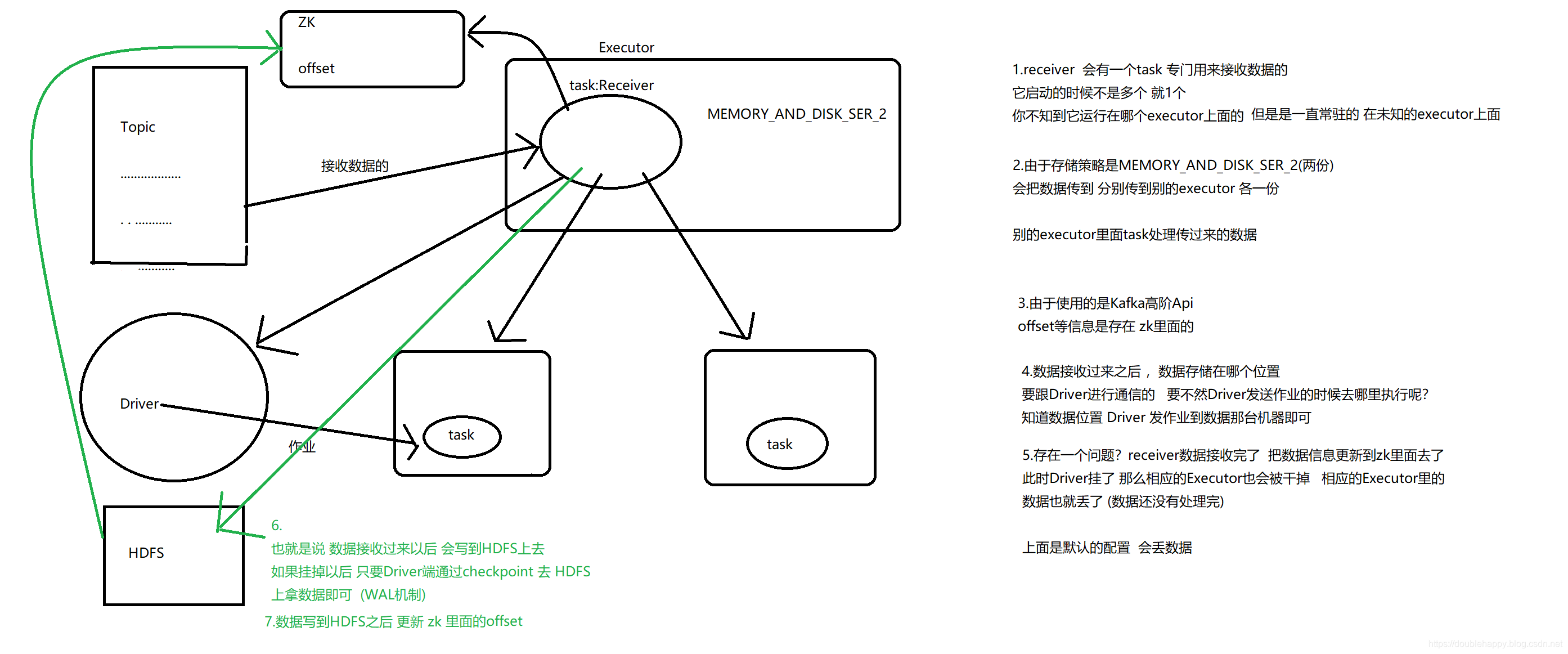
However, under default configuration, this approach can lose data under failures (see receiver reliability. To ensure zero-data loss, you have to additionally enable Write-Ahead Logs in Spark Streaming (introduced in Spark 1.2). This synchronously saves all the received Kafka data into write-ahead logs on a distributed file system (e.g HDFS), so that all the data can be recovered on failure. See Deploying section in the streaming programming guide for more details on Write-Ahead Logs.
1 | WAL机制:先把日志记录下来 这里就是数据 |
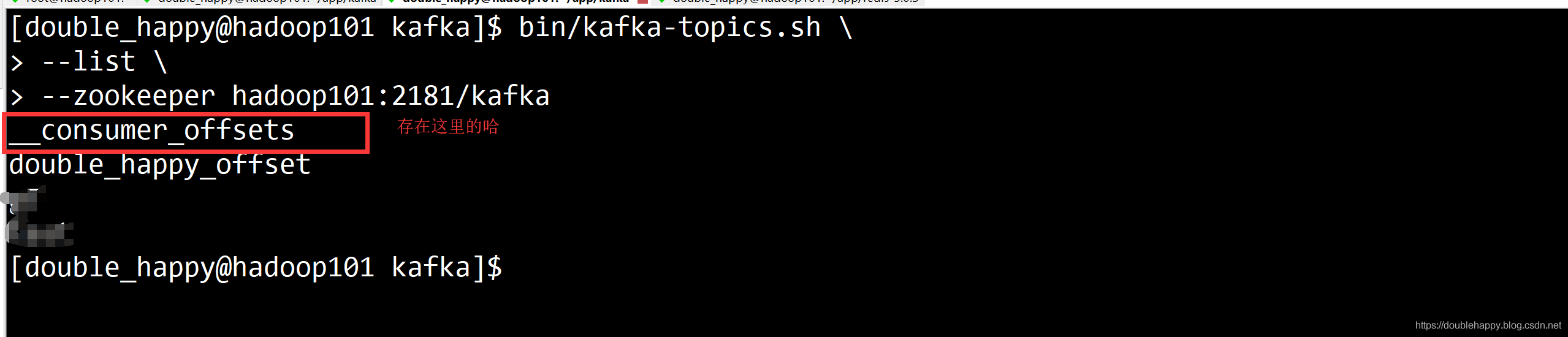
1 | 注意:Kafka的整合只有一个工具类 叫KafkaUtils |

Points to remember:
Topic partitions in Kafka do not correlate to partitions of RDDs generated in Spark Streaming. So increasing the number of topic-specific partitions in the KafkaUtils.createStream() only increases the number of threads using which topics that are consumed within a single receiver. It does not increase the parallelism of Spark in processing the data. Refer to the main document for more information on that.
1 | Topic是有partition的 |
Multiple Kafka input DStreams can be created with different groups and topics for parallel receiving of data using multiple receivers.
1 | 总结: |
spark-streaming-kafka-0-10 重点
spark-streaming-kafka-0-10
The Spark Streaming integration for Kafka 0.10 is similar in design to the 0.8 Direct Stream approach. It provides simple parallelism, 1:1 correspondence between Kafka partitions and Spark partitions, and access to offsets and metadata. However, because the newer integration uses the new Kafka consumer API instead of the simple API, there are notable differences in usage. This version of the integration is marked as experimental, so the API is potentially subject to change.
1 | Offset管理的时候不同 |
1 | Direct |
案例
1 | Producer: console (测试的时候 ) 就是使用KafkaApi代码实现 |
1 | KafkaProducer: |
1 | 怎么发送呢? |
1 | [double_happy@hadoop101 kafka]$ bin/kafka-console-consumer.sh \ |
对接
1 | /** |
1 | object StreamingKakfaDirectApp { |
1 | object StreamingKakfaDirectApp { |
1 | hadoop101:6379> keys * |
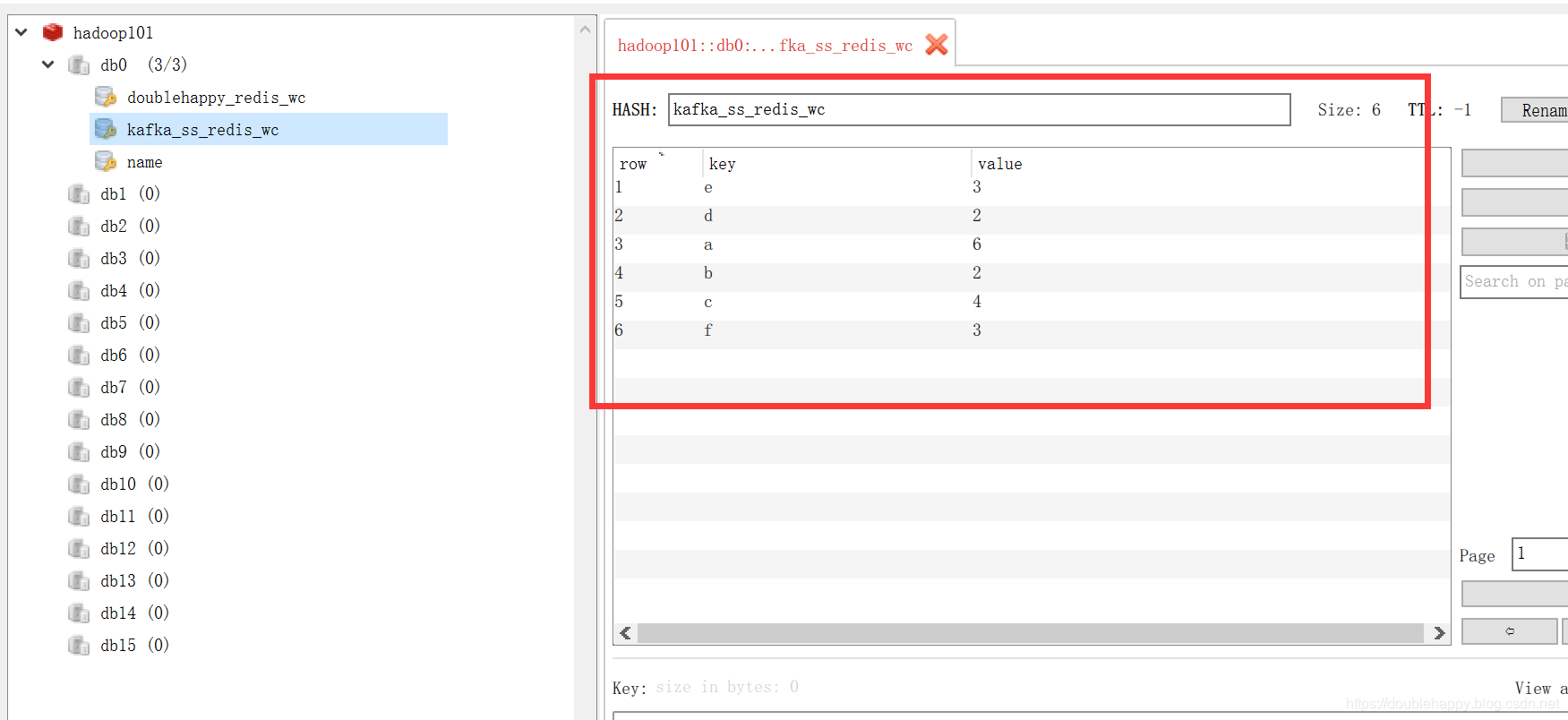
1 | 这个时候 把实时代码关掉 : |
1 | trait HasOffsetRanges { |
1 | 获取offset: |
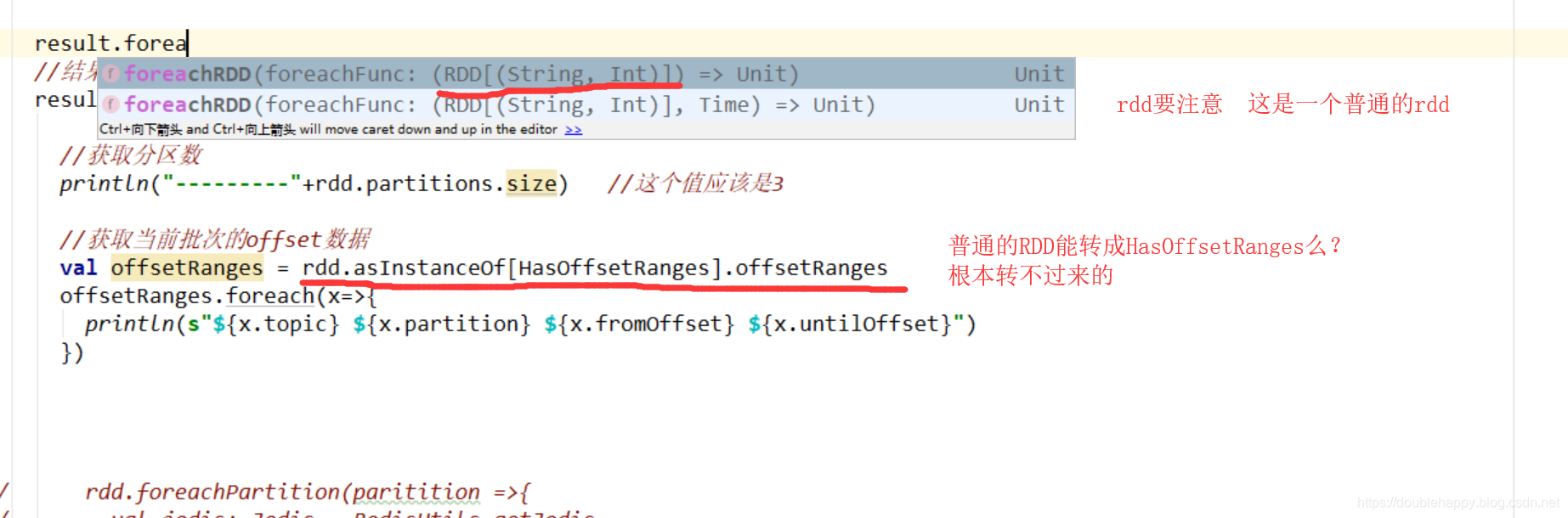
1 | 为什么报错呢? ***** 而且分区数还是2 说明不对 |
1 | 获取offset: |
1 | ${x.topic} ${x.partition} ${x.fromOffset} ${x.untilOffset} |
1 | 很多方式 : |
1 | 2.Kafka itself : |
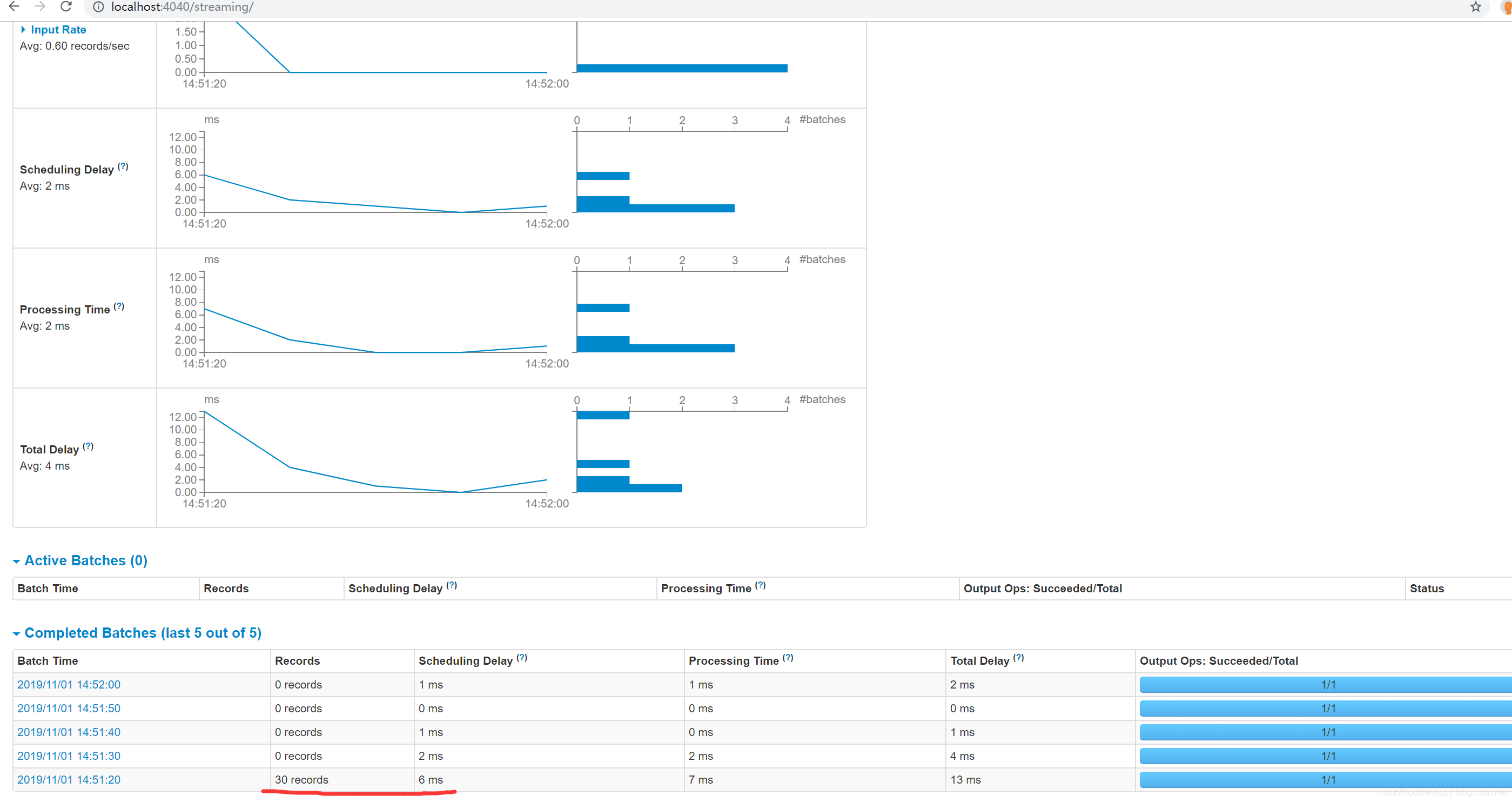
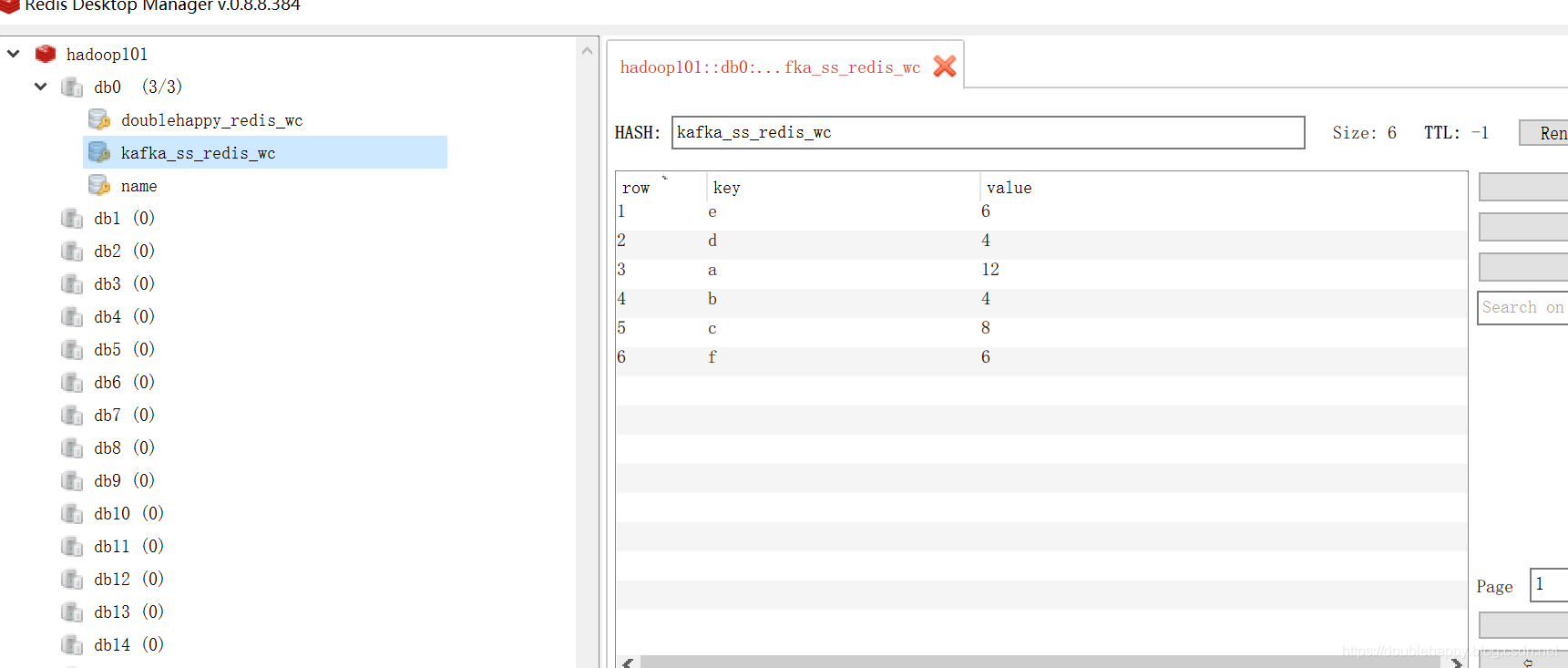
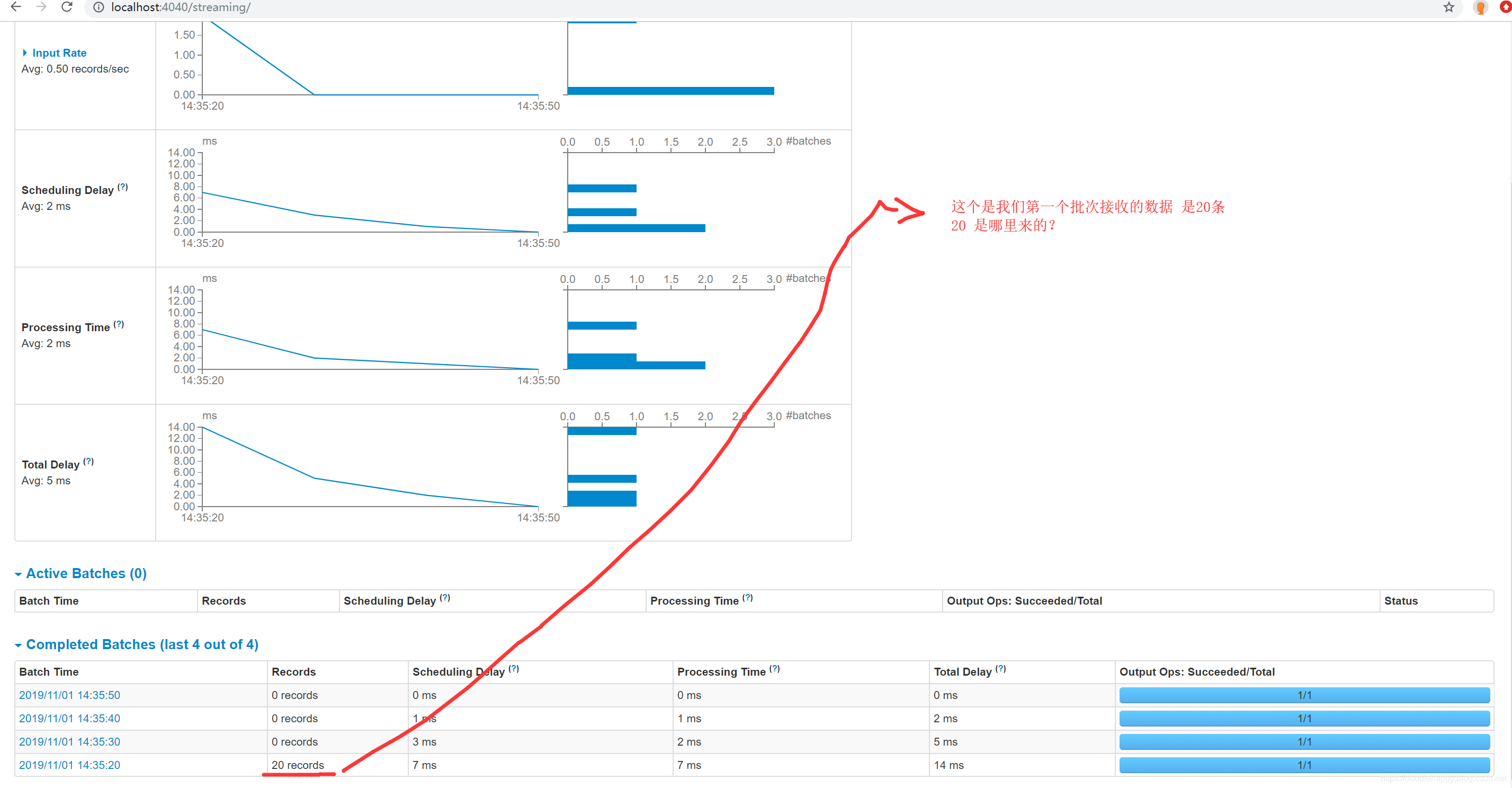
第二次 重启之后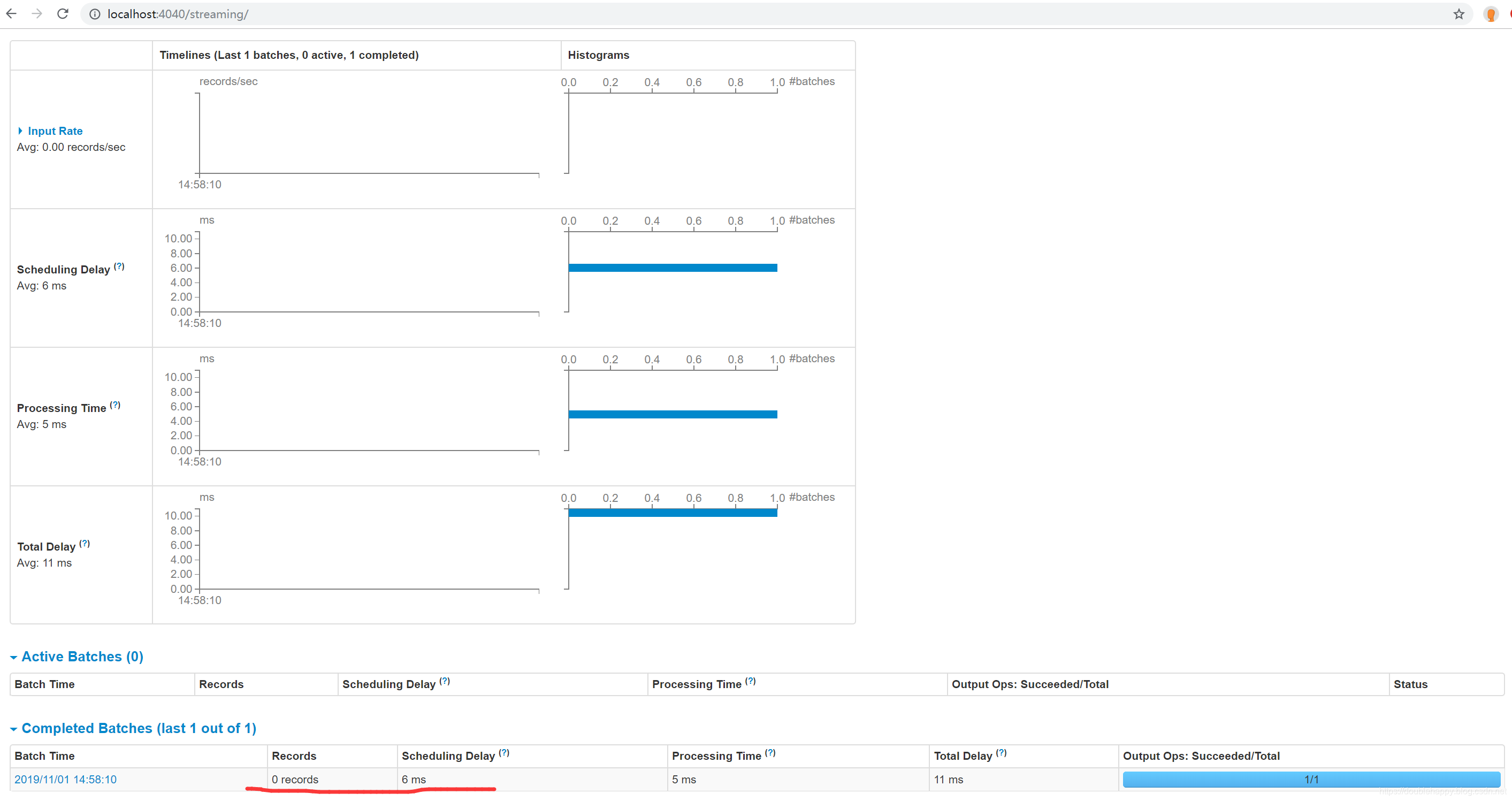
1 | 数据是0 对吧 因为数据已经提交过了 |
However, you can commit offsets to Kafka after you know your output has been stored, using the commitAsync API. The benefit as compared to checkpoints is that Kafka is a durable store regardless of changes to your application code. However, Kafka is not transactional, so your outputs must still be idempotent.
1 | 1.你的业务逻辑完成之后再提交offset |
3.Your own data store
1 | 这里我使用redis 你选择MySQL也是可以的 为了测试换一个groupid 让他重新消费 |
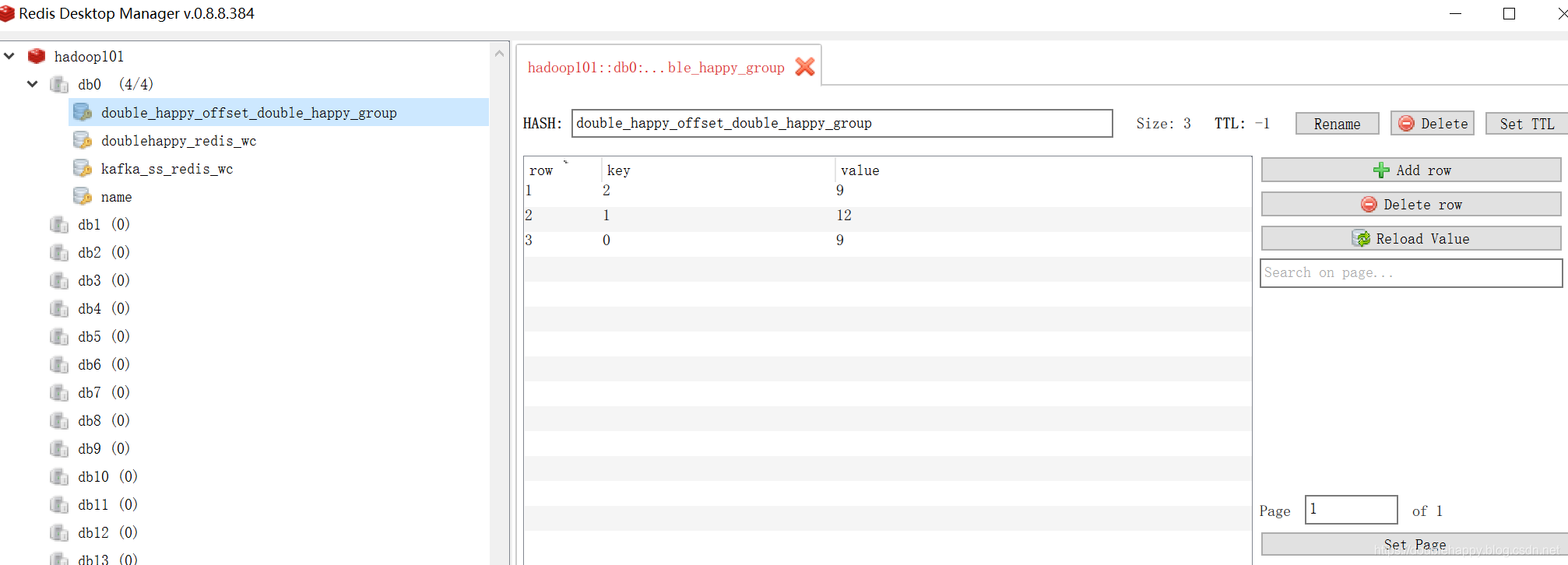
1 | 再生产一批数据 查看结果: |
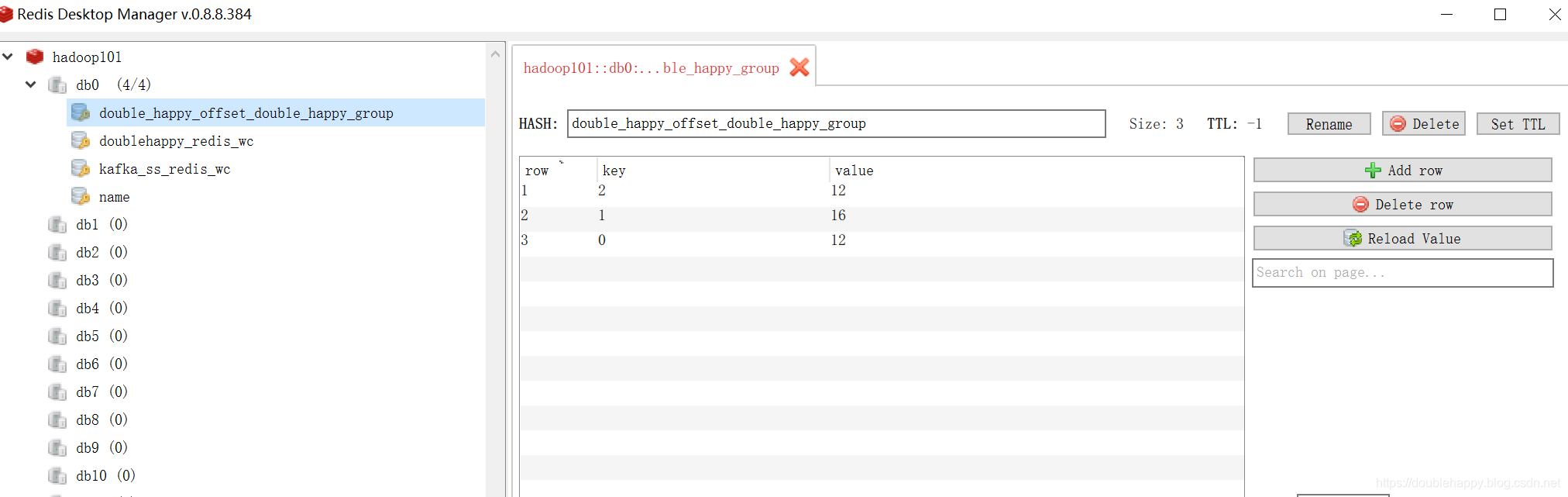
1 | 我把程序关掉 先生成两个批次的数据 再把程序打开 查看结果 |
1 | 测试:取出 offset 从redis |
1 | object RedisOffsetApp { |
1 | 所以我们再测试实时的代码 : |
1 | 总结: |
总结
1 | 1. "auto.offset.reset" -> "earliest" |