1 | shuffle: |
1 | 找源码 要到 SparkEnv里面找 |
HashShuffleManager
为了看源码 idea里pom使用老点的版本
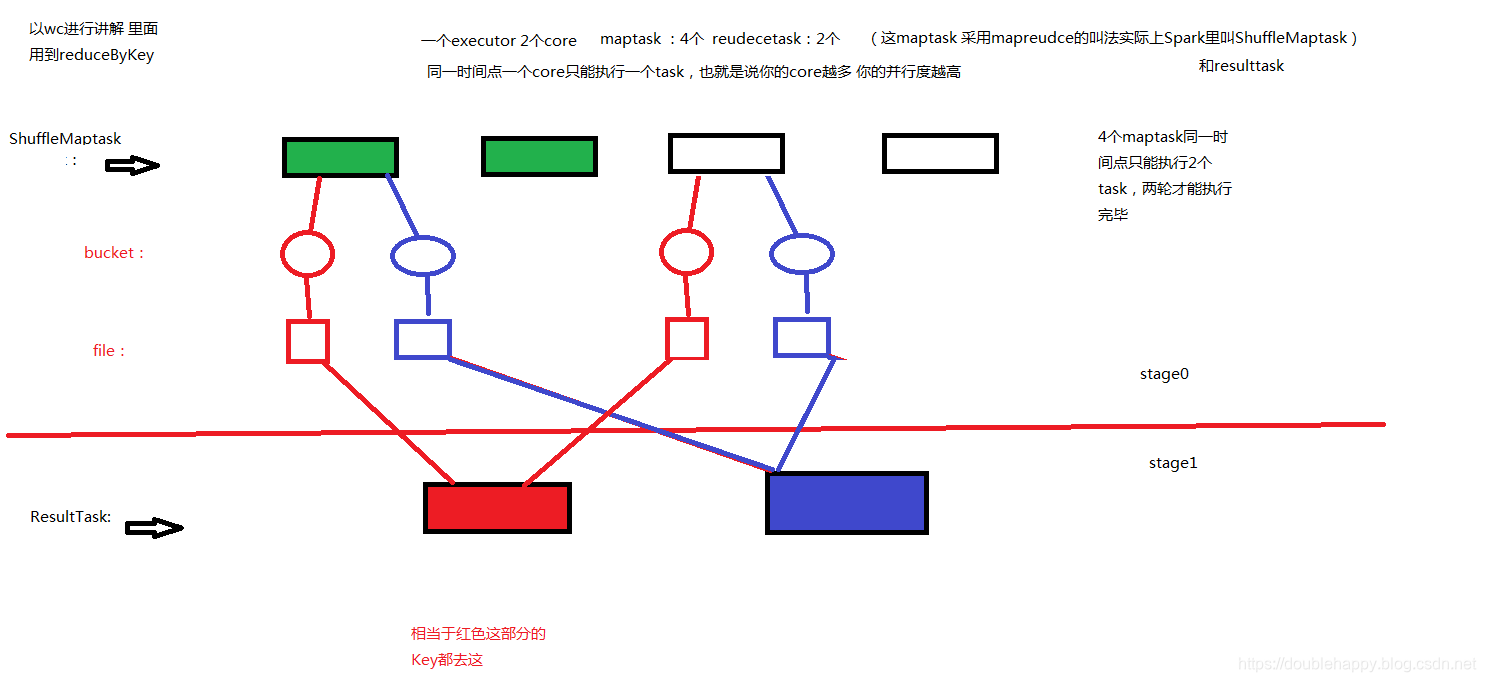
1 | HashShuffleManager : |
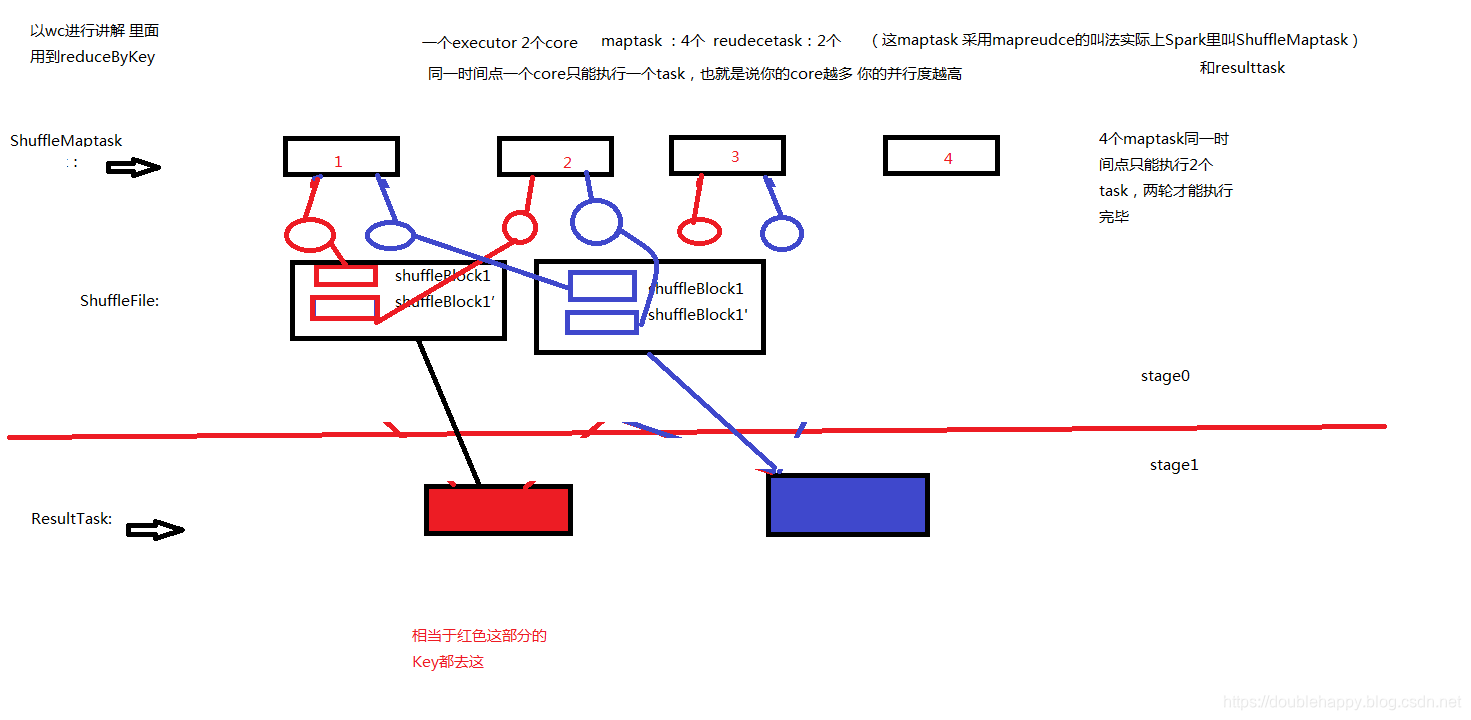
1 | 1.自己梳理下SortShuffleManner |
优化
你首先要知道spark哪些地方需要优化?
Tuning Spark
Because of the in-memory nature of most Spark computations, Spark programs can be bottlenecked by any resource in the cluster: CPU, network bandwidth, or memory. Most often, if the data fits in memory, the bottleneck is network bandwidth, but sometimes, you also need to do some tuning, such as storing RDDs in serialized form, to decrease memory usage. This guide will cover two main topics: data serialization, which is crucial for good network performance and can also reduce memory use, and memory tuning. We also sketch several smaller topics.
1 | bottlenecked :瓶颈 |
Data Serialization
看官网 写的很清楚
Serialization plays an important role in the performance of any distributed application.
因为算子里用到的东西 都是要经过序列化才可以
Tuning Spark
1 | Java serialization: |
1 | [double_happy@hadoop101 conf]$ cat spark-defaults.conf |
1 | 测试 通过cache 看看页面 data 大小就ok了 |
Determining Memory Consumption
你怎么知道一个数据集或者对象的内存占用了多少了呢?
1 | 两种方法: |
1 | -r-xr-xr-x 1 double_happy double_happy 14M Sep 21 12:33 ip.txt |

1 | 为什么第二种方法多这么多? |
1 | If you have less than 32 GB of RAM, set the JVM flag -XX:+UseCompressedOops to make pointers be four bytes instead of eight. You can add these options in spark-env.sh. |
Garbage Collection Tuning
需要先了解内存管理 和 jvm 才能 gc调优
gc我没有复习 所以这块之后补上。
Data Locality
数据本地化 了解即可 很难实现
If data and the code that operates on it are together then computation tends to be fast.
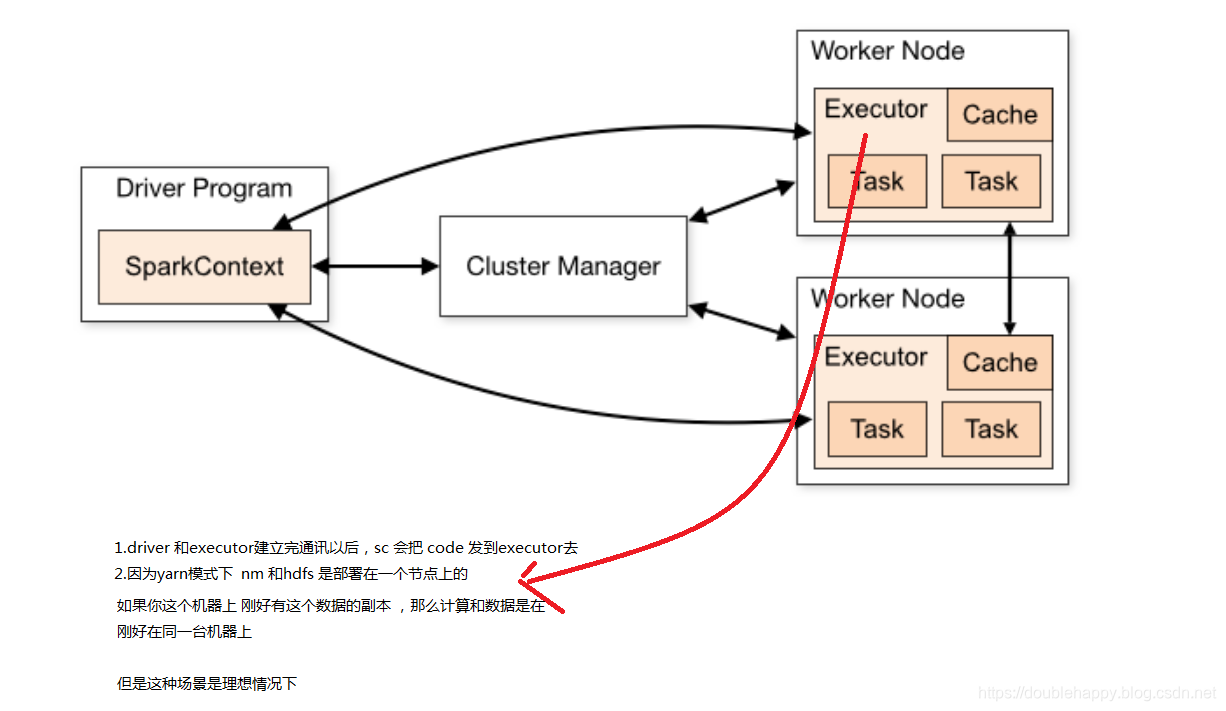
But if code and data are separated, one must move to the other. Typically it is faster to ship serialized code from place to place than a chunk of data because code size is much smaller than data. Spark builds its scheduling around this general principle of data locality.
1 | one must move to the other 就是这两个总有一个要移动的 |
Data locality is how close data is to the code processing it. There are several levels of locality based on the data’s current location. In order from closest to farthest:
1 | levels of locality: |
总结shuffle参数:
1 | 1.spark.shuffle.consolidateFiles hashshuffle优化开启参数 |