依赖关系
1 | rdd ==> transformation s ==> action |
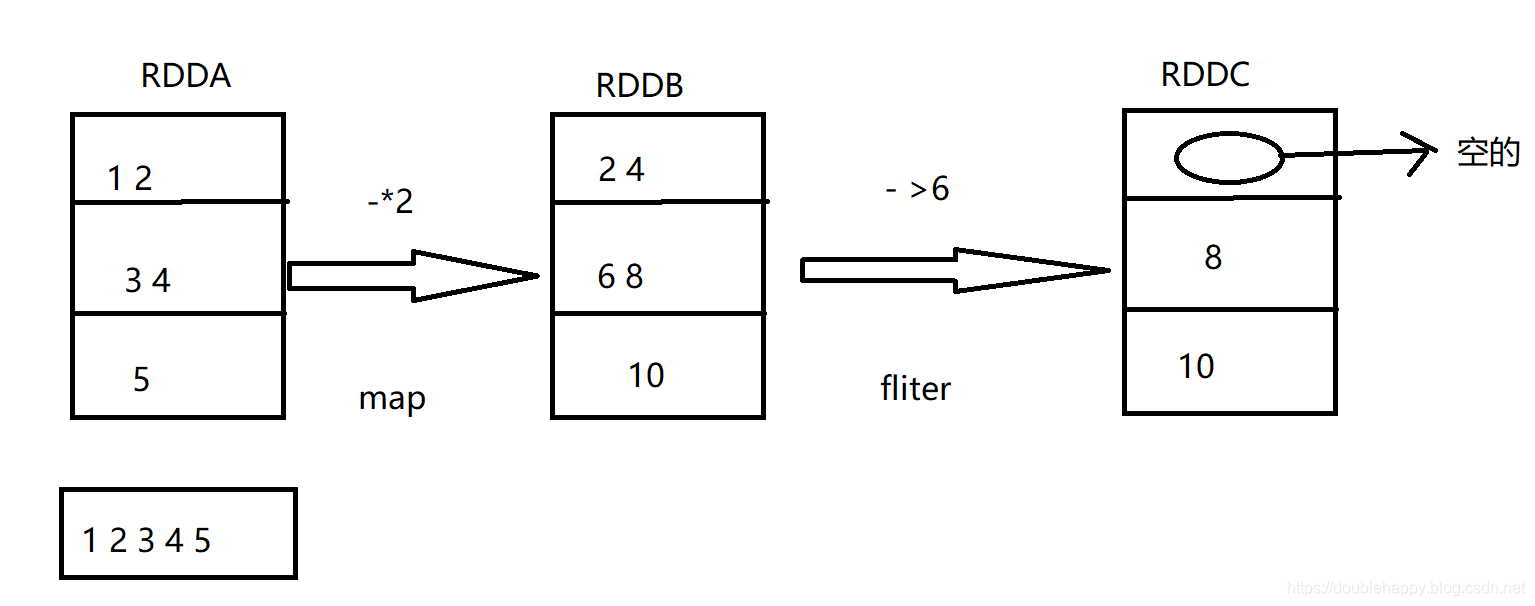
对于这个场景他们之间是有一个依赖关系的
1 | 注意: |
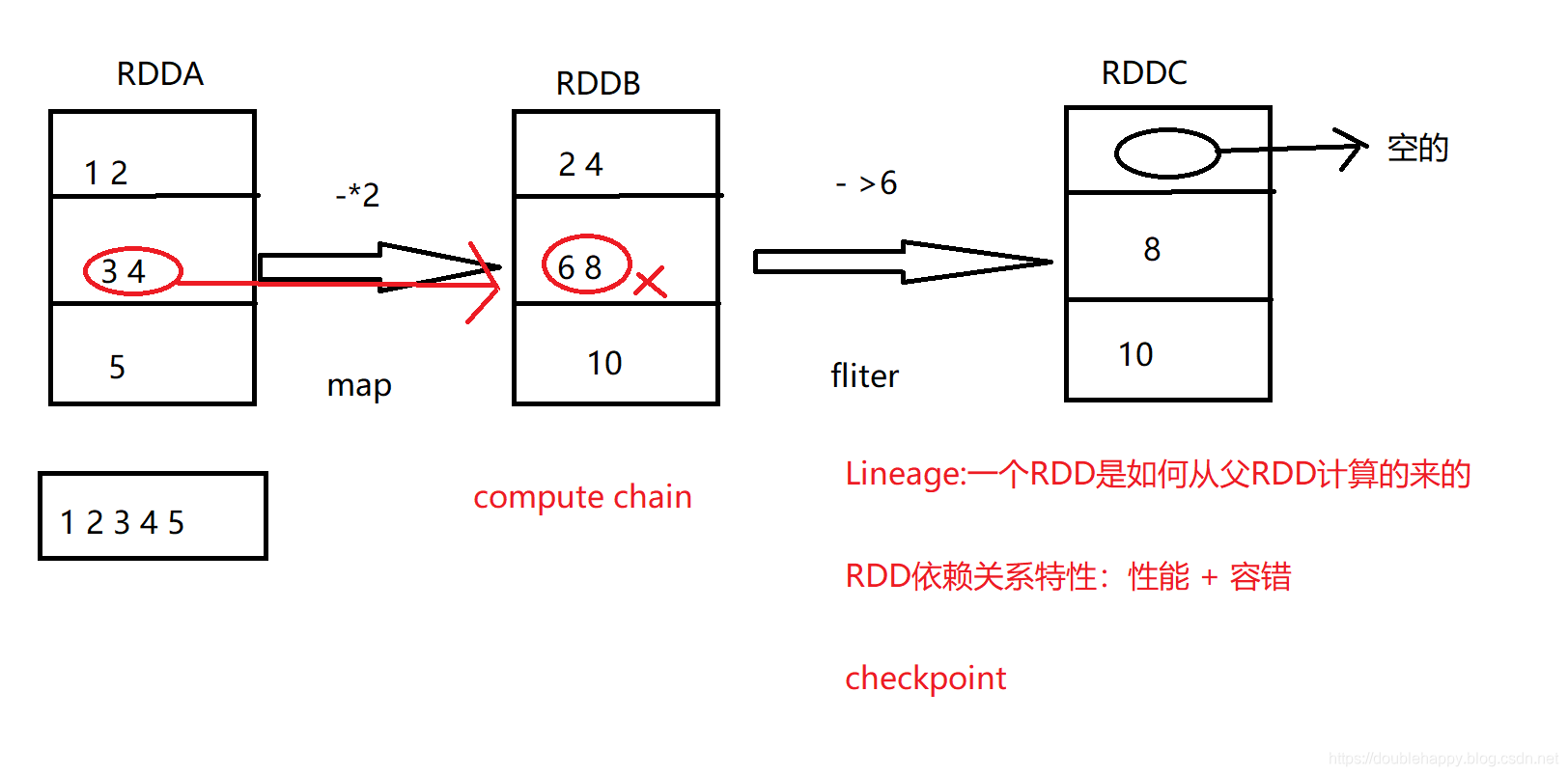
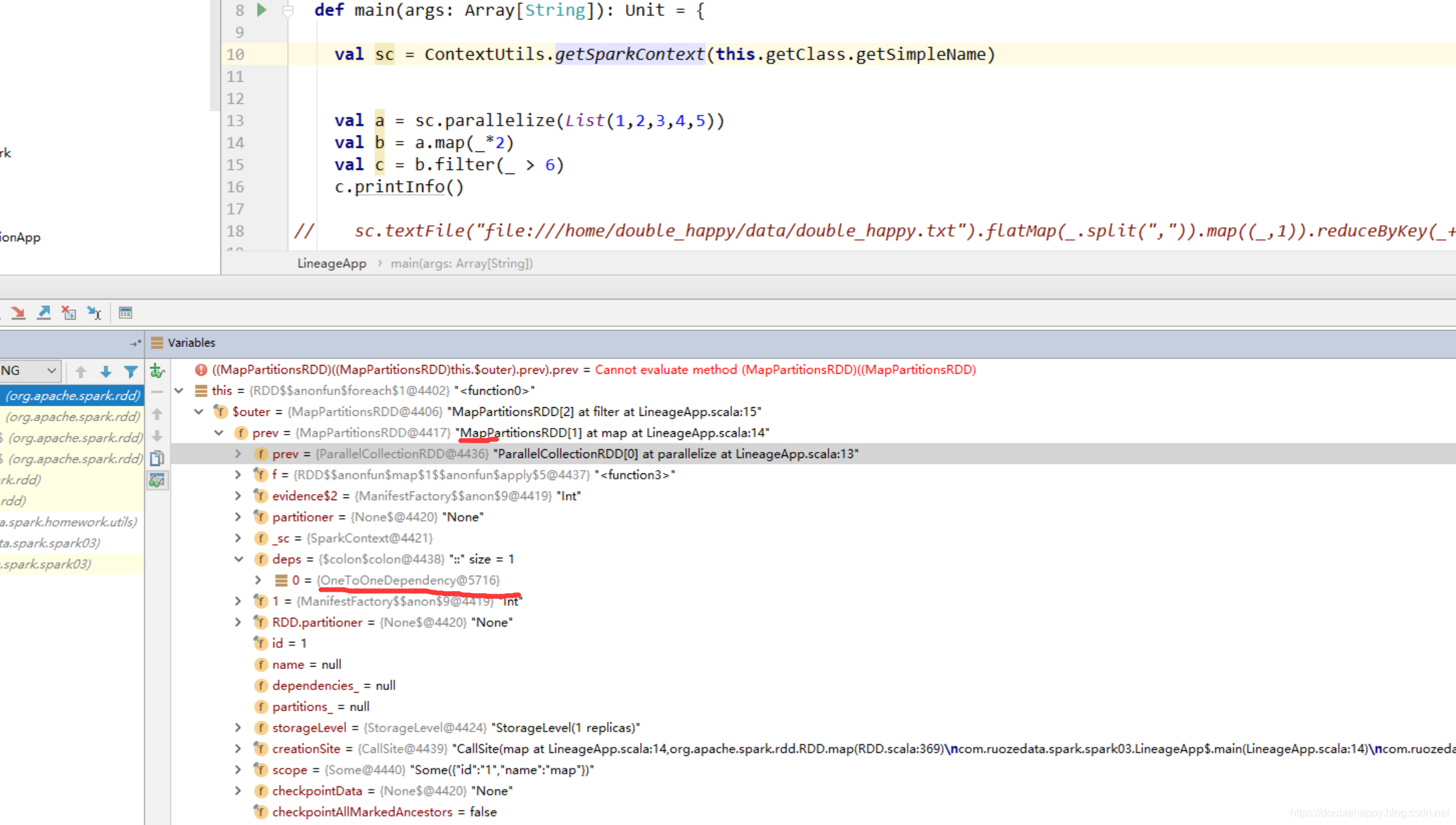
(1)idea中debug是可以看到依赖关系的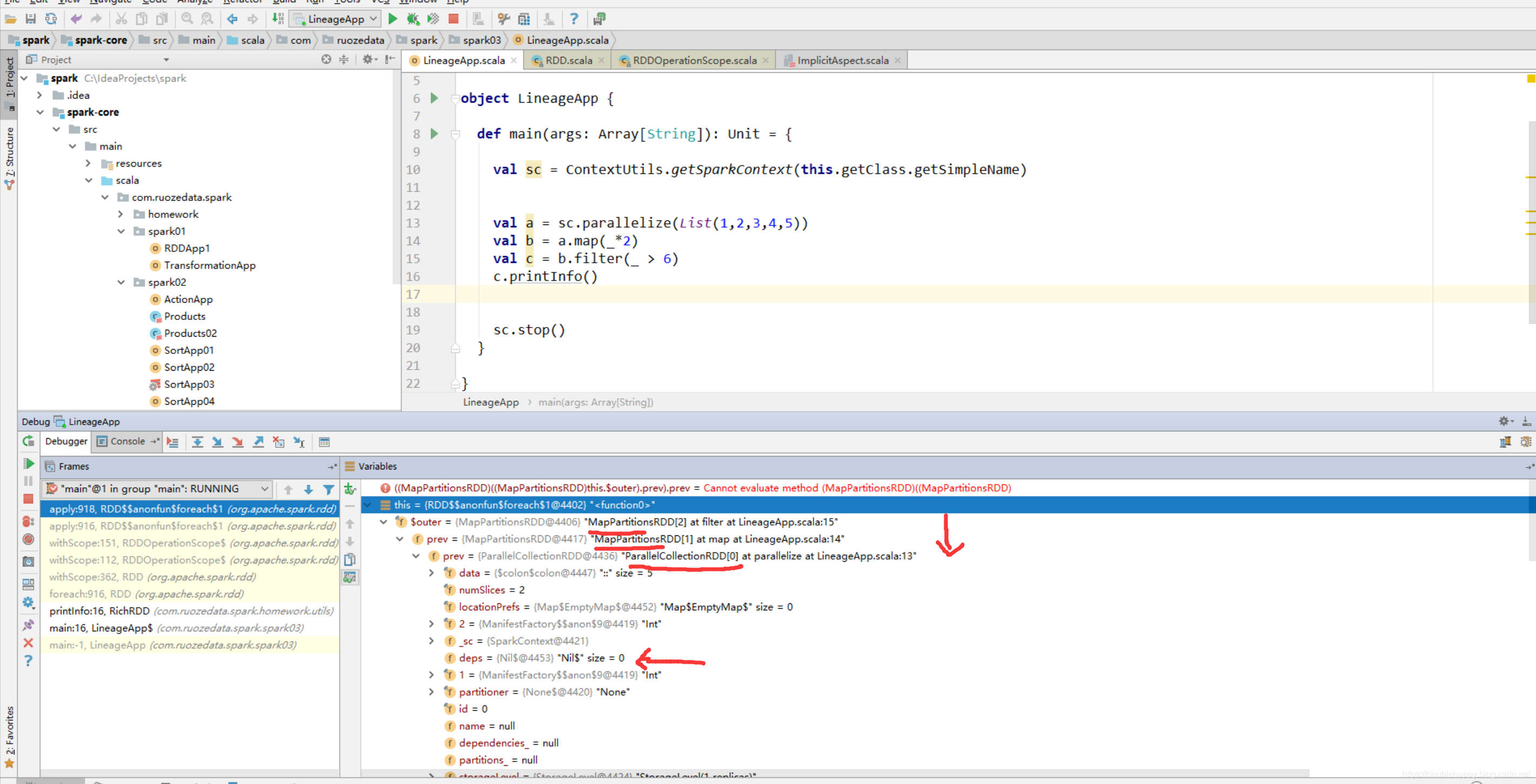
所以整个过程中 你的RDD是怎么来的 spark是知道的
(2) spark-shell中
1 | scala> val a = sc.parallelize(List(1,2,3,4,5)) |
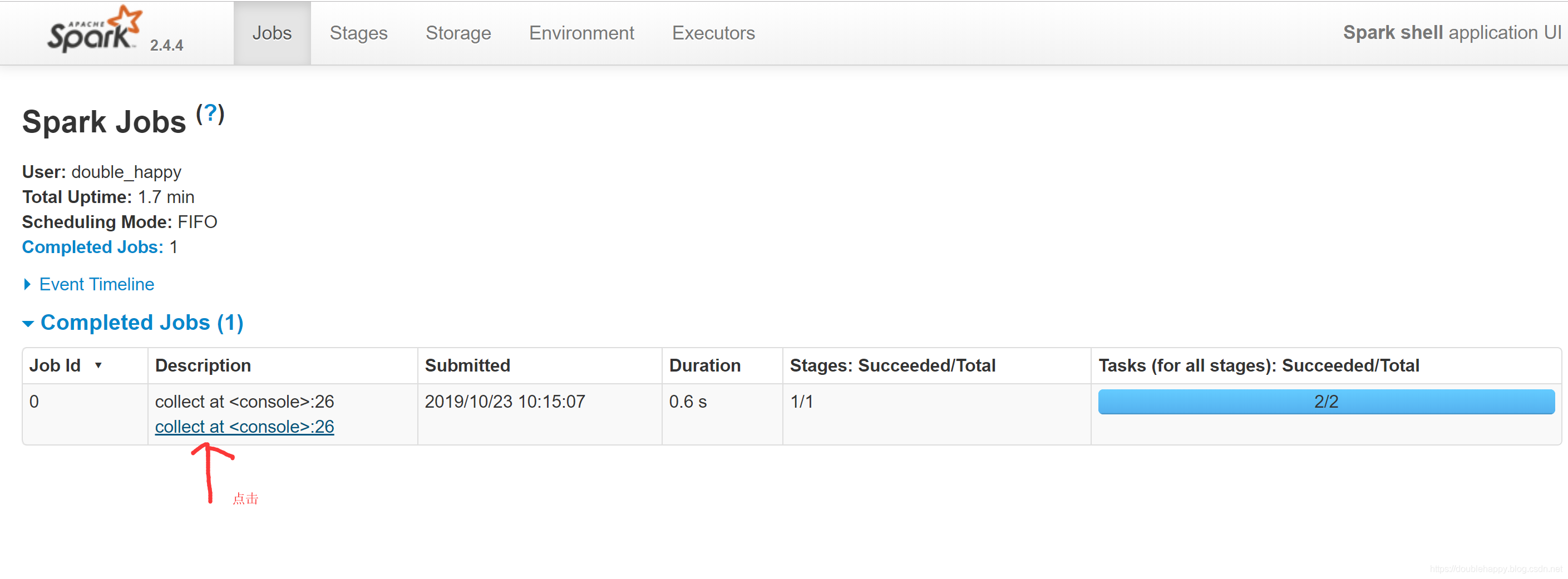
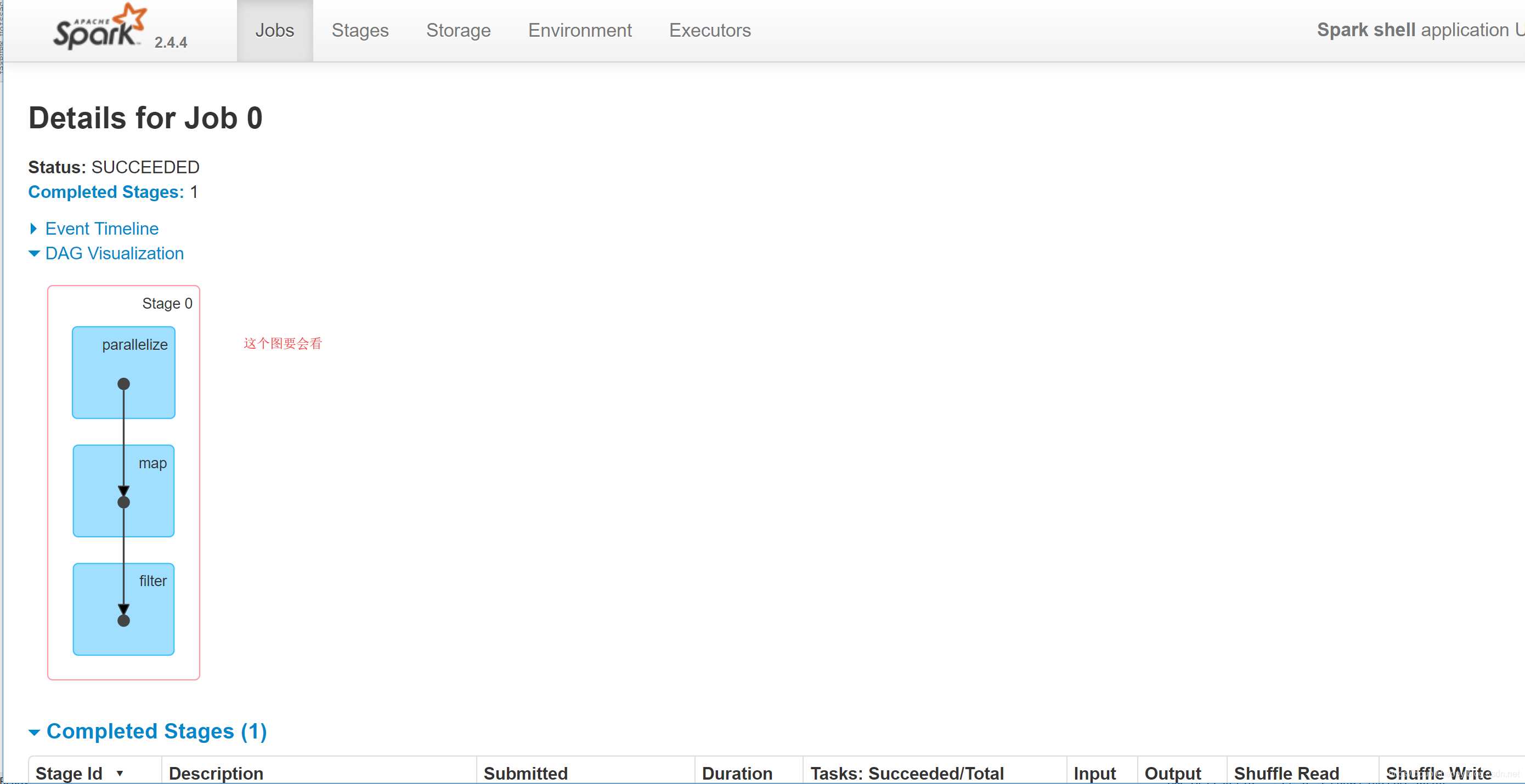
1 | 那么这个过程中到底产生多少个RDD呢? |
textFile
1 | sc.textFile() 这一个过程产生多少个RDD呢? |
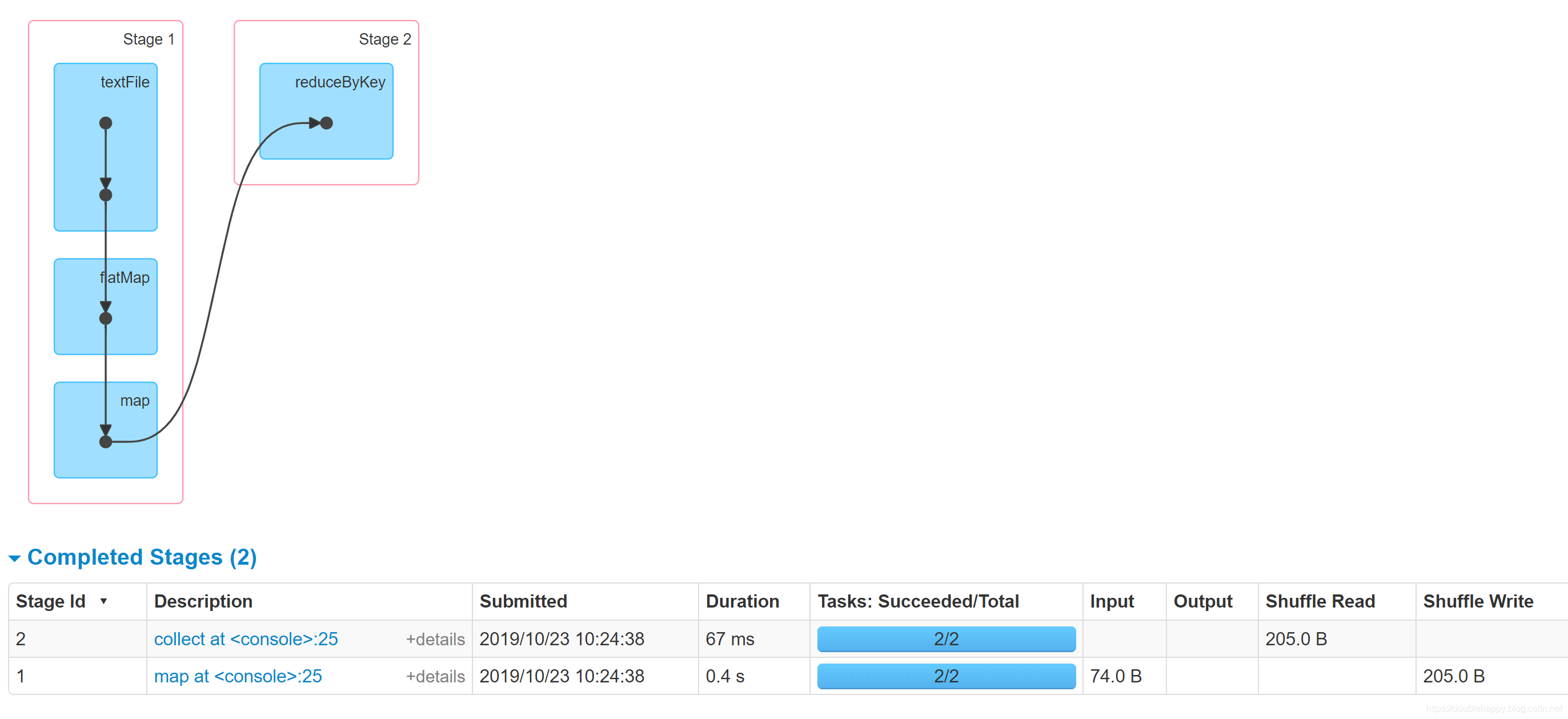
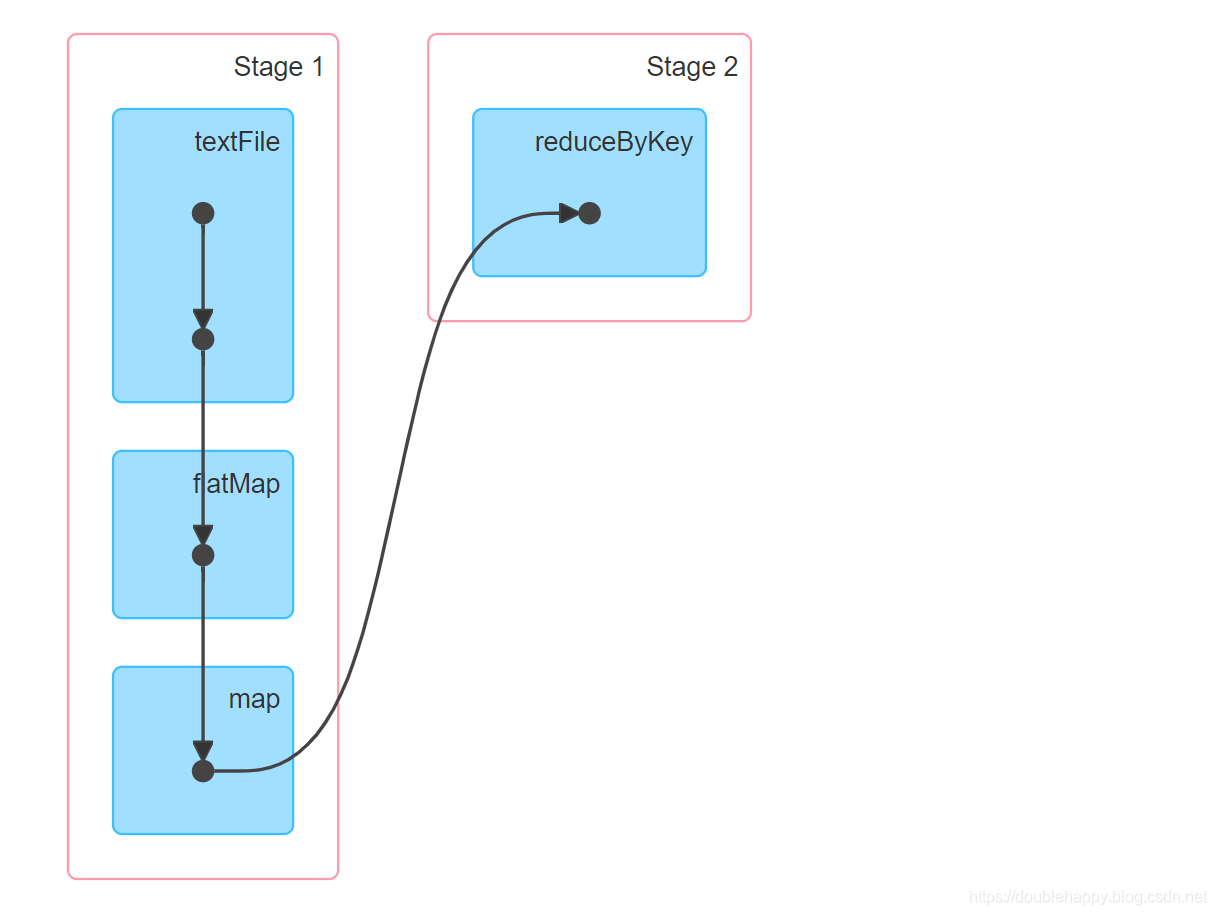
1 | 这个过程产生了多少rdd呢? |
1 | textFile 过程: |
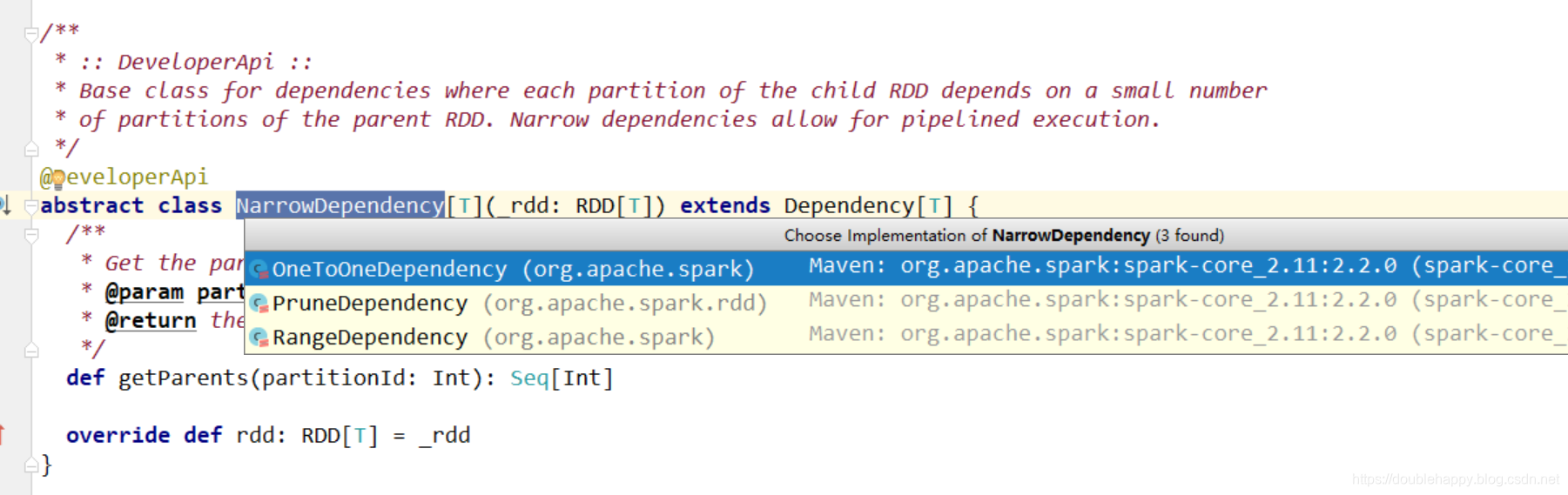
Dependency
1 | 窄依赖 |
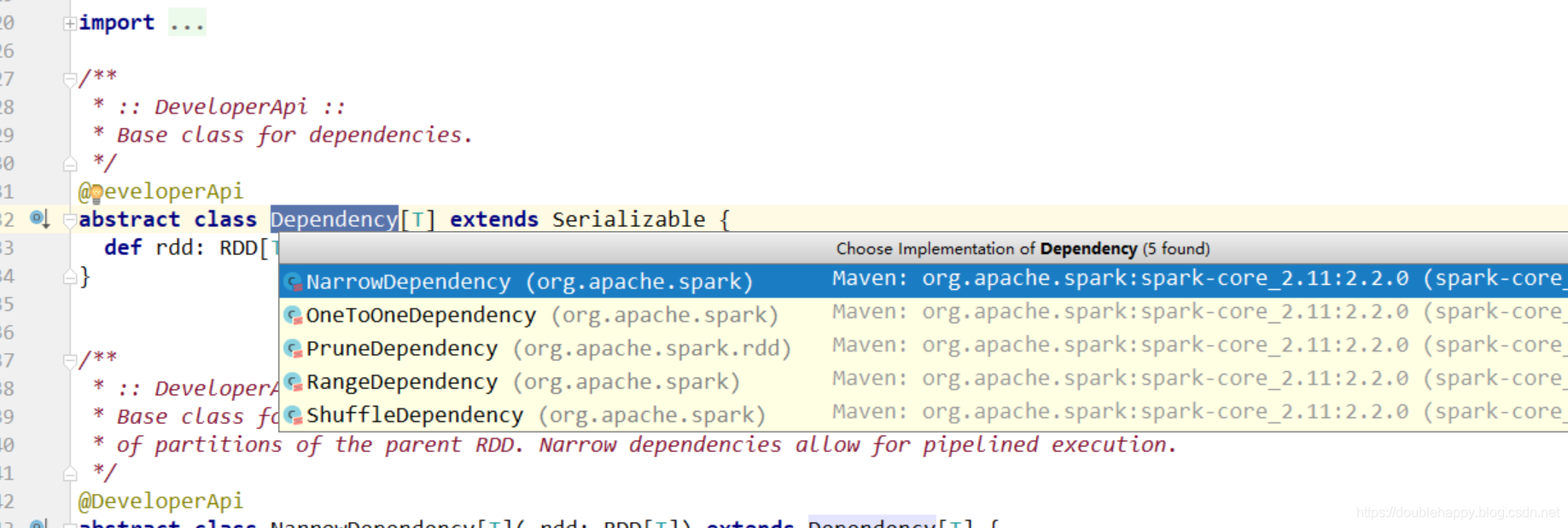
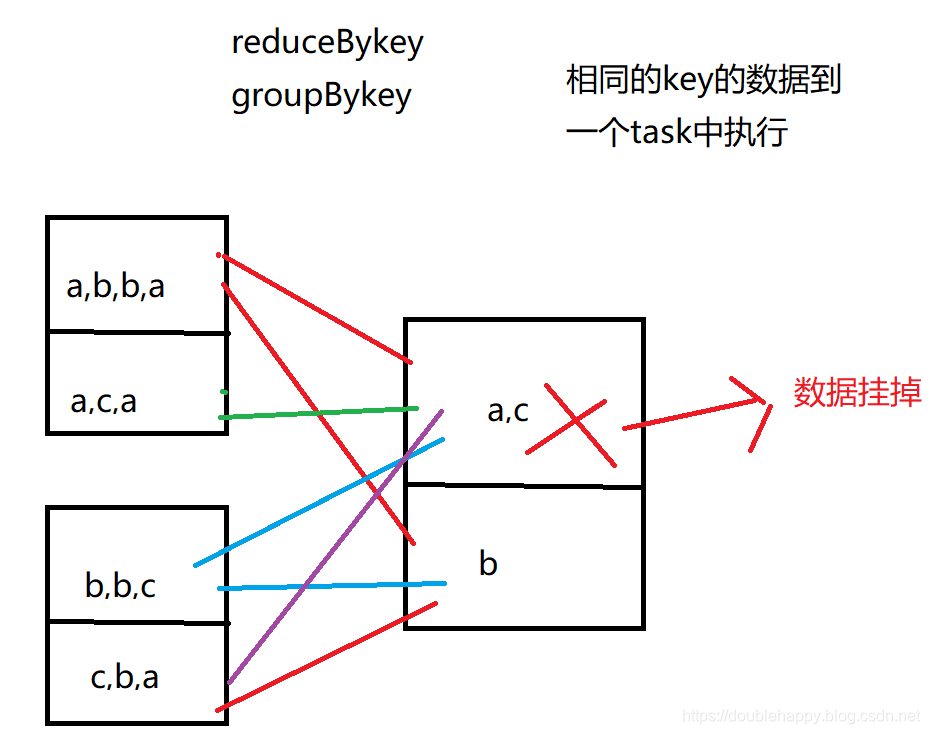
1 | 如果经过宽依赖之后的RDD的某一个分区数据挂掉 |
解析wc过程
1 | val lines = sc.textFile("file:///home/double_happy/data/double_happy.txt") |
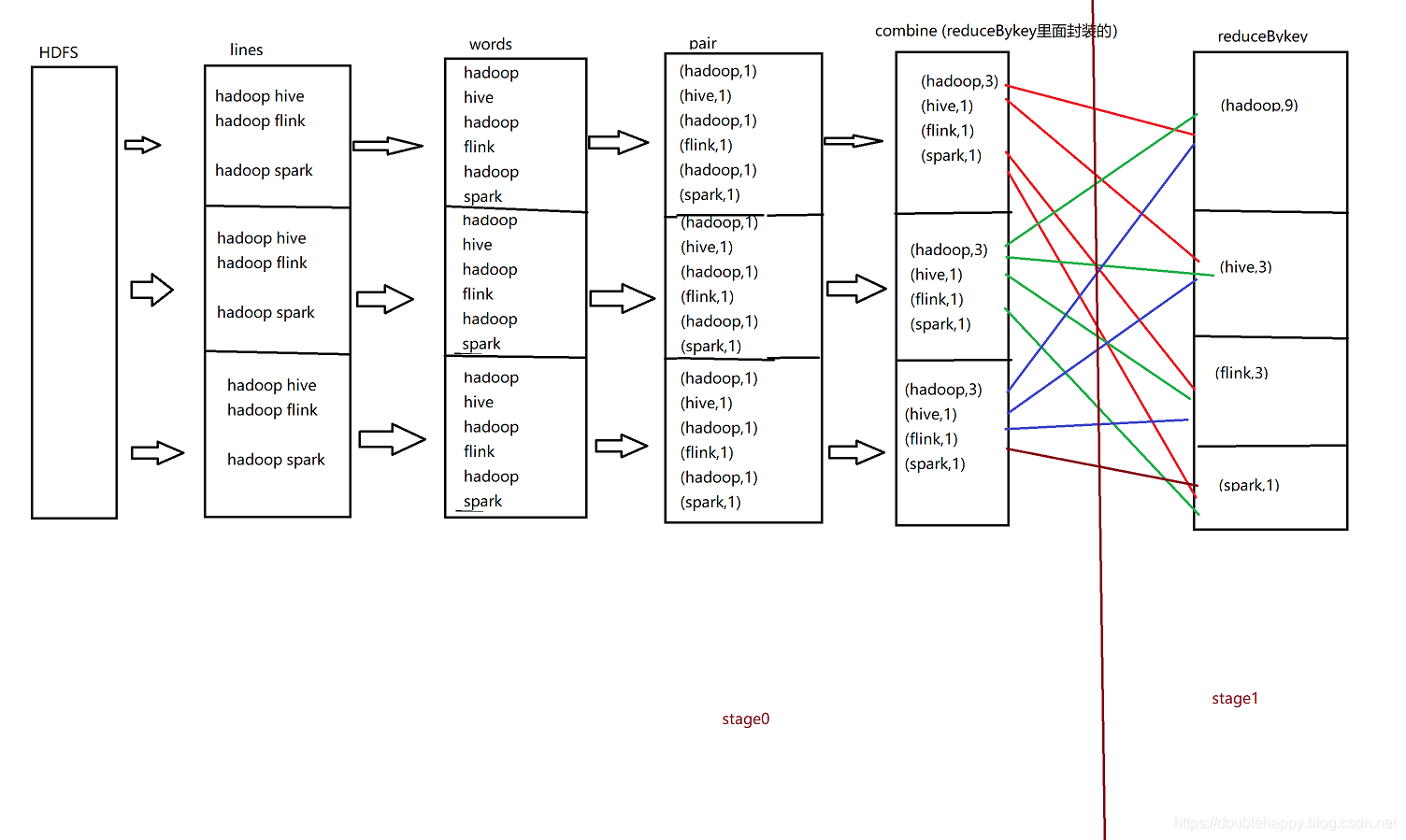
1 | 为什么会多一个conbine操作呢? |
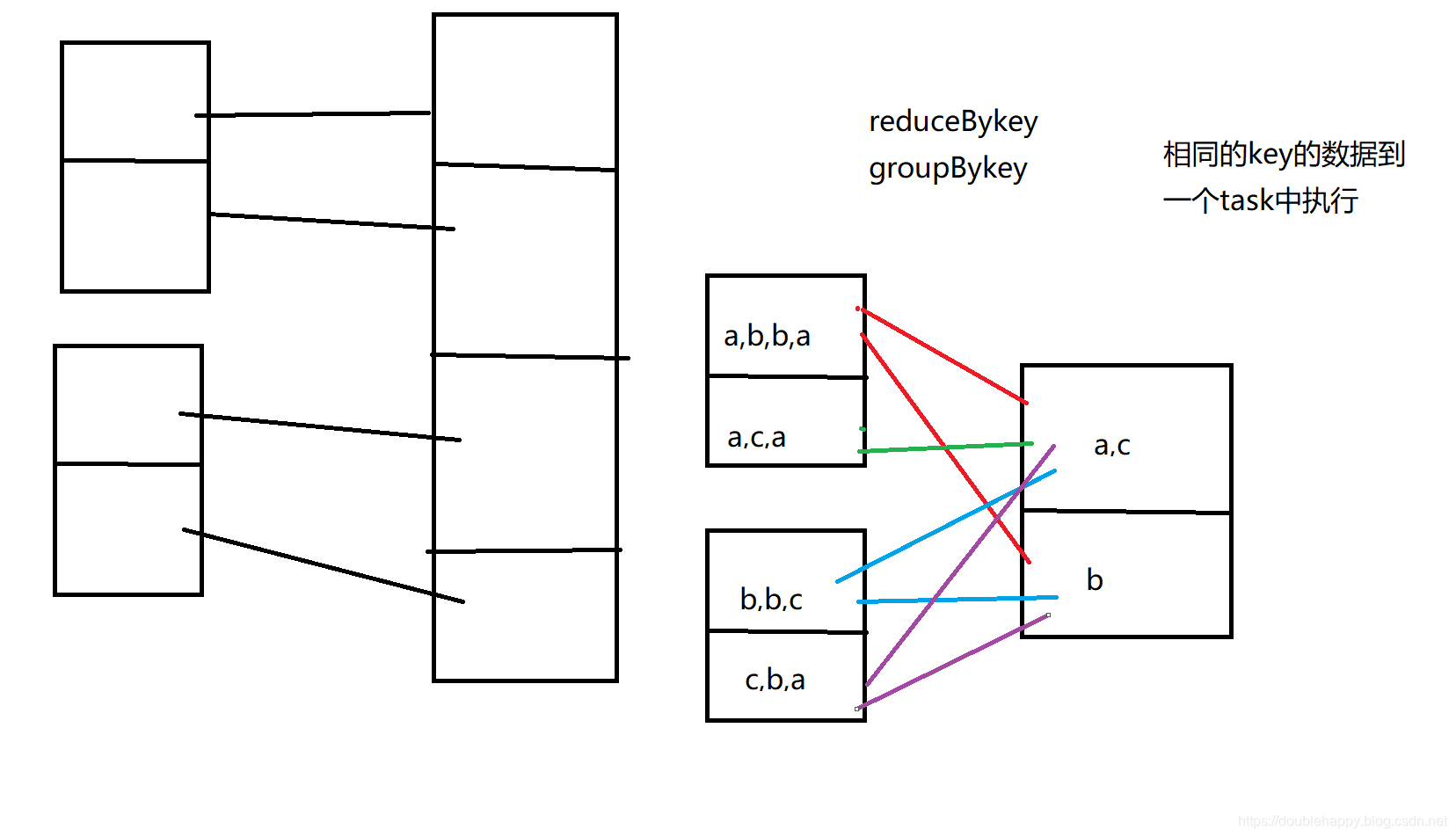
shuffle operations
The shuffle is Spark’s mechanism for re-distributing data so that it’s grouped differently across partitions. This typically involves copying data across executors and machines, making the shuffle a complex and costly operation.
1 | re-distributing data: |
Operations which can cause a shuffle include repartition operations like repartition and coalesce, ‘ByKey operations (except for counting) like groupByKey and reduceByKey, and join operations like cogroup and join.
上面这句话是不严谨的 之后测试证实。
The Shuffle is an expensive operation since it involves disk I/O, data serialization, and network I/O.
这块官网好好读读
缓存
1 | val lines = sc.textFile("file:///home/double_happy/data/double_happy.txt") |
(1)没有做cache测试
1 | scala> val re = sc.textFile("file:///home/double_happy/data/double_happy.txt").flatMap(_.split(",")).map((_,1)) |
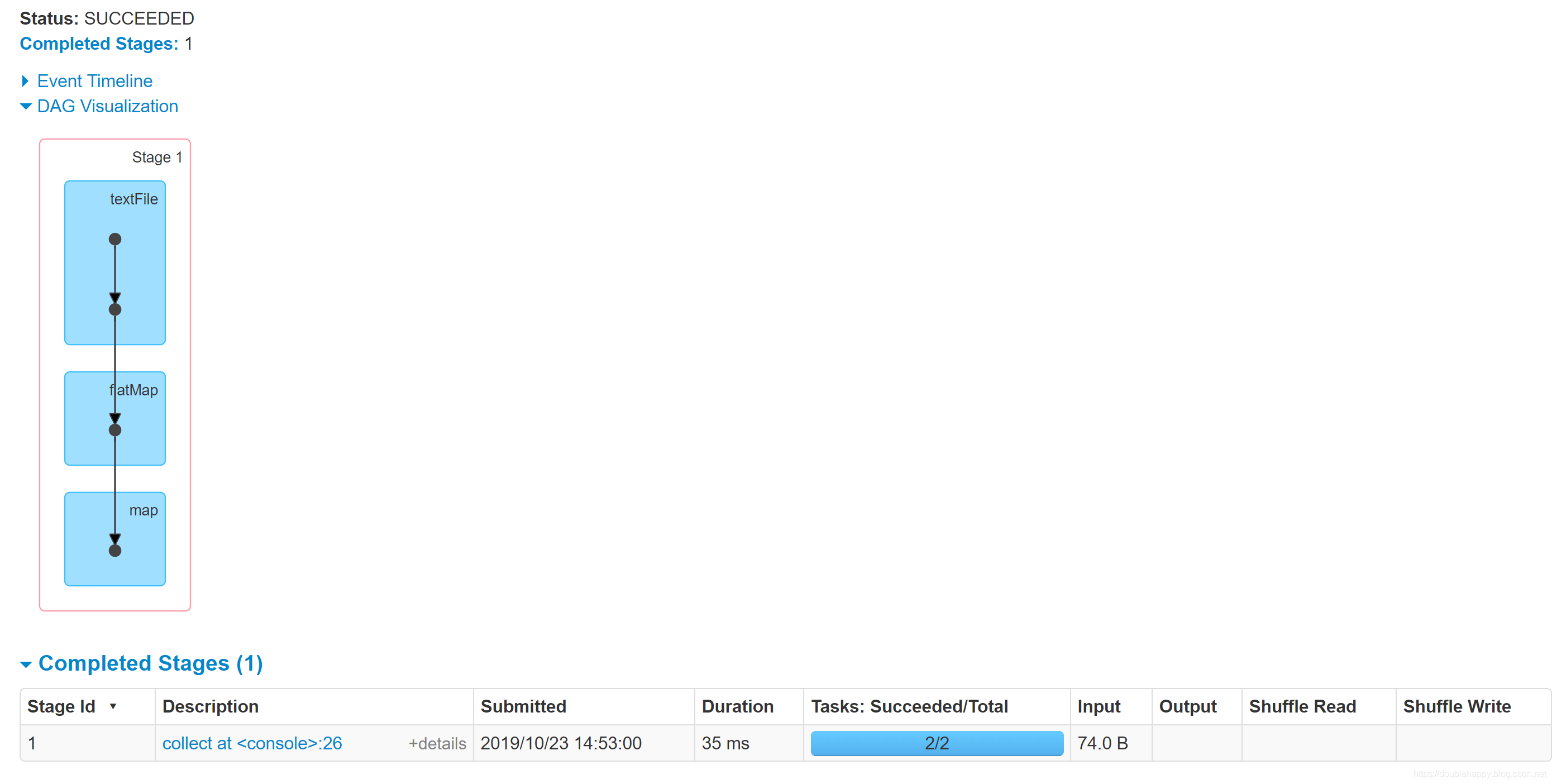
再执行一遍 re.collect 页面还是这样的
(2)做cache
1 | scala> val re = sc.textFile("file:///home/double_happy/data/double_happy.txt").flatMap(_.split(",")).map((_,1)) |
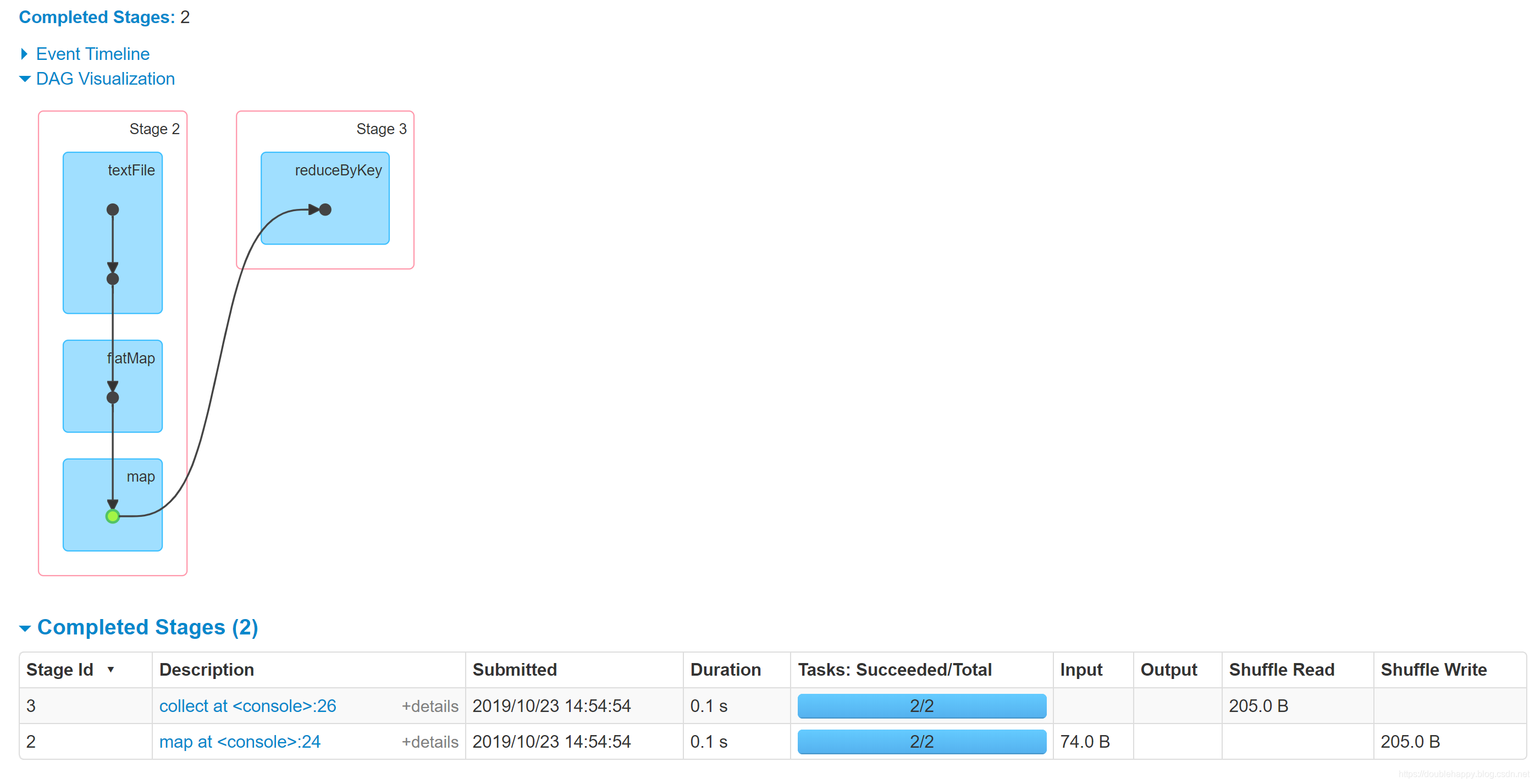
再执行一边
1 | scala> re.reduceByKey(_+_).collect |
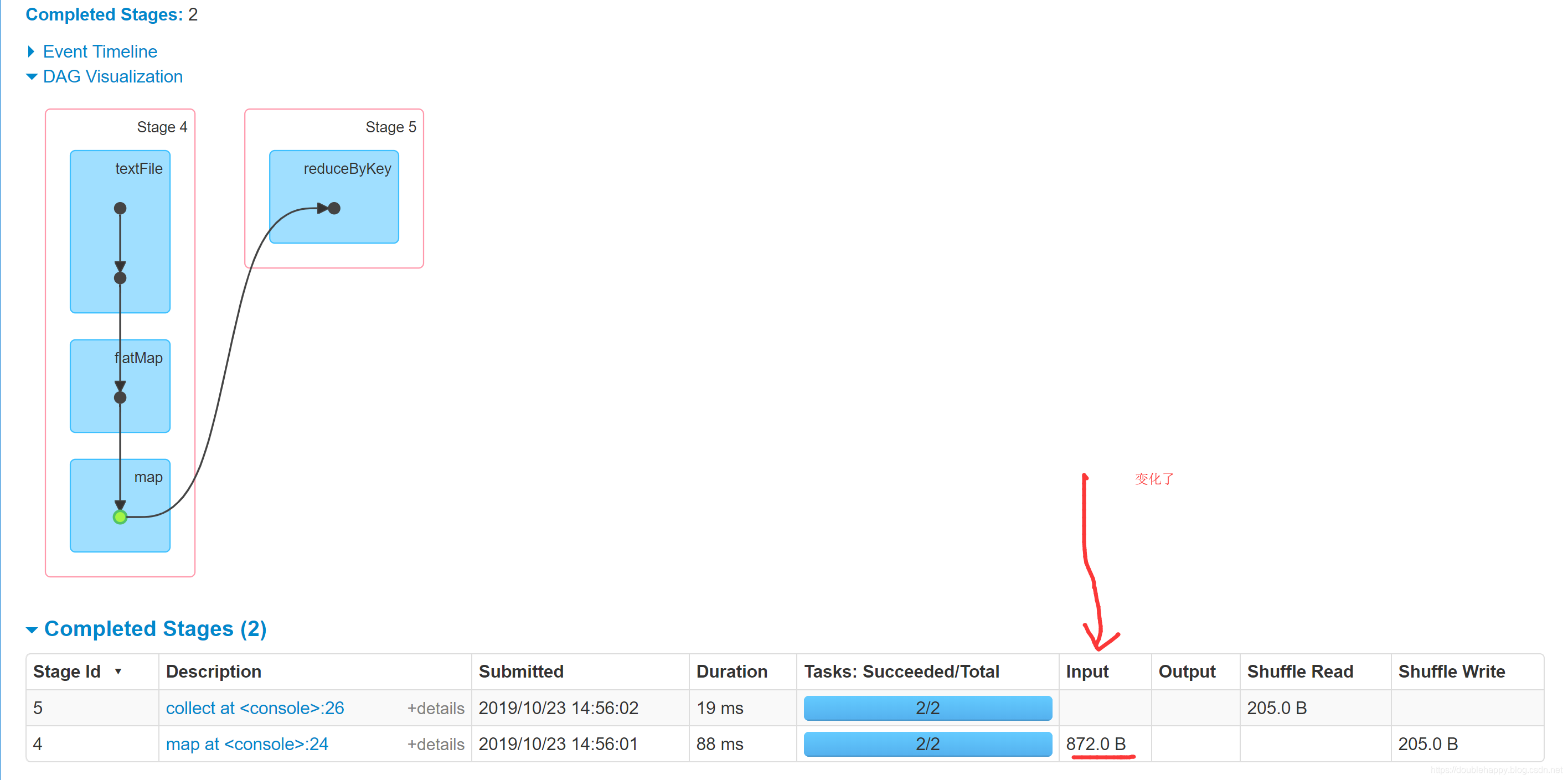
会发现执行了两次 就根本不是一个东西了 ,做了cache已经把我们的东西持久化到默认的存储级别里去了,下次就会去缓存里读取数据了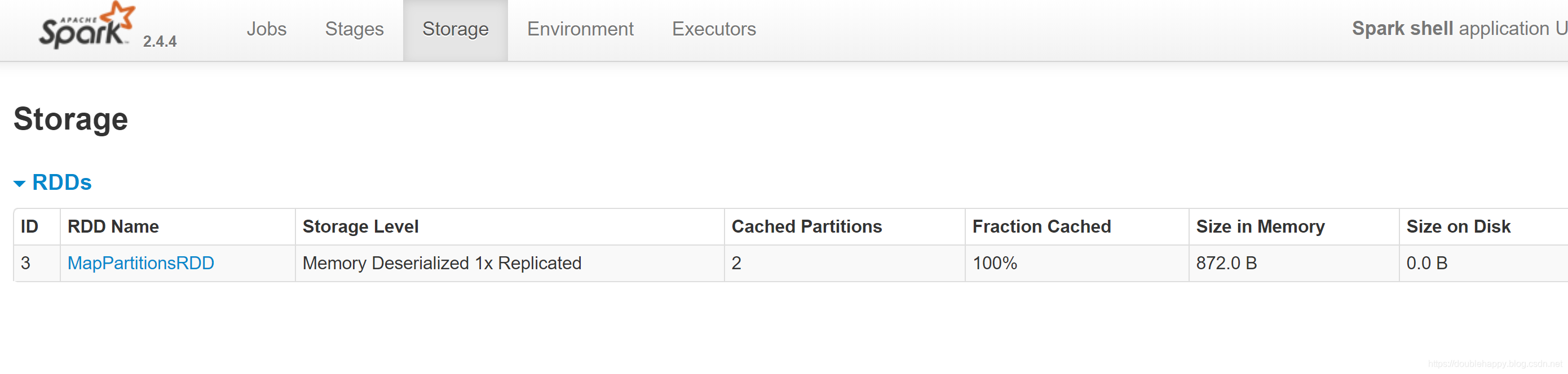
1 | 1.不做cache 如果你对同一个操作执行多次 下一次会从头开始执行 |
persist和cache的区别
You can mark an RDD to be persisted using the persist() or cache() methods on it. The first time it is computed in an action, it will be kept in memory on the nodes. Spark’s cache is fault-tolerant – if any partition of an RDD is lost, it will automatically be recomputed using the transformations that originally created it.
If you would like to manually remove an RDD instead of waiting for it to fall out of the cache, use the RDD.unpersist() method.
1 | The first time it is computed in an action |
1 | scala> val re = sc.textFile("file:///home/double_happy/data/double_happy.txt").flatMap(_.split(",")).map((_,1)) |
1 | 1.cache 、 persist 是 lazy的 |
1 | /** |
1 | object StorageLevel { |
1 | 1.cache |

换一种存储级别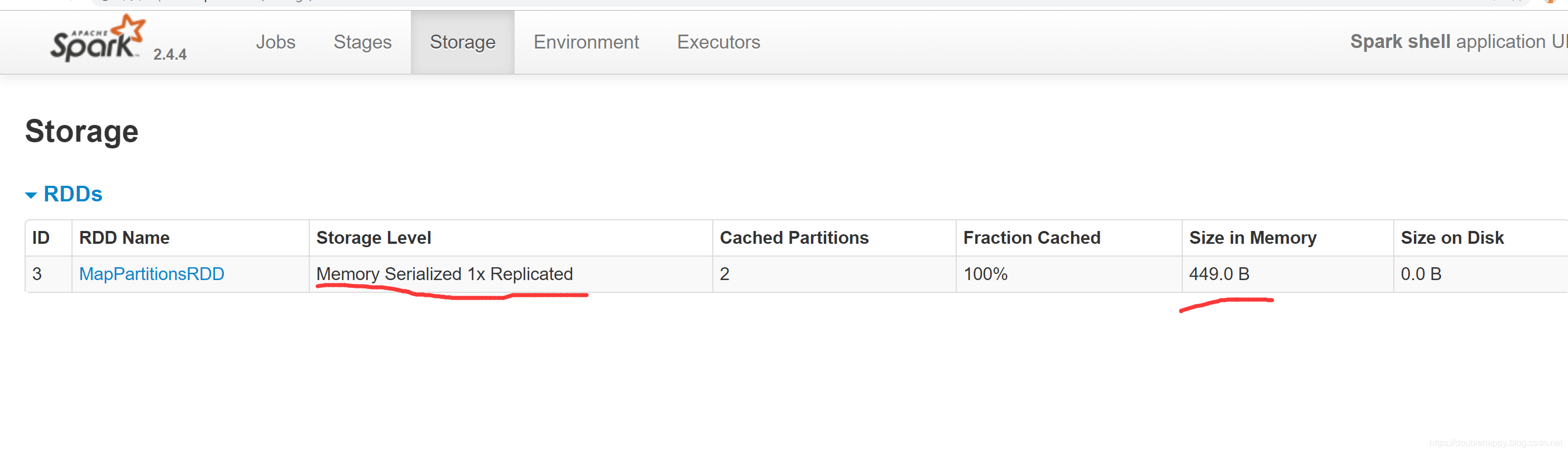
数据是不是小了 序列化的会节省空间
1 | scala> re.collect |
Which Storage Level to Choose?
Which Storage Level to Choose?
一定要做序列化么?这和压缩是一个道理
Spark’s storage levels are meant to provide different trade-offs between memory usage and CPU efficiency.
coalesce和repartition
repartition
1 | /** |
1 | package com.ruozedata.spark.spark03 |
1 | scala> val data = sc.parallelize(List(1 to 9: _*),3) |
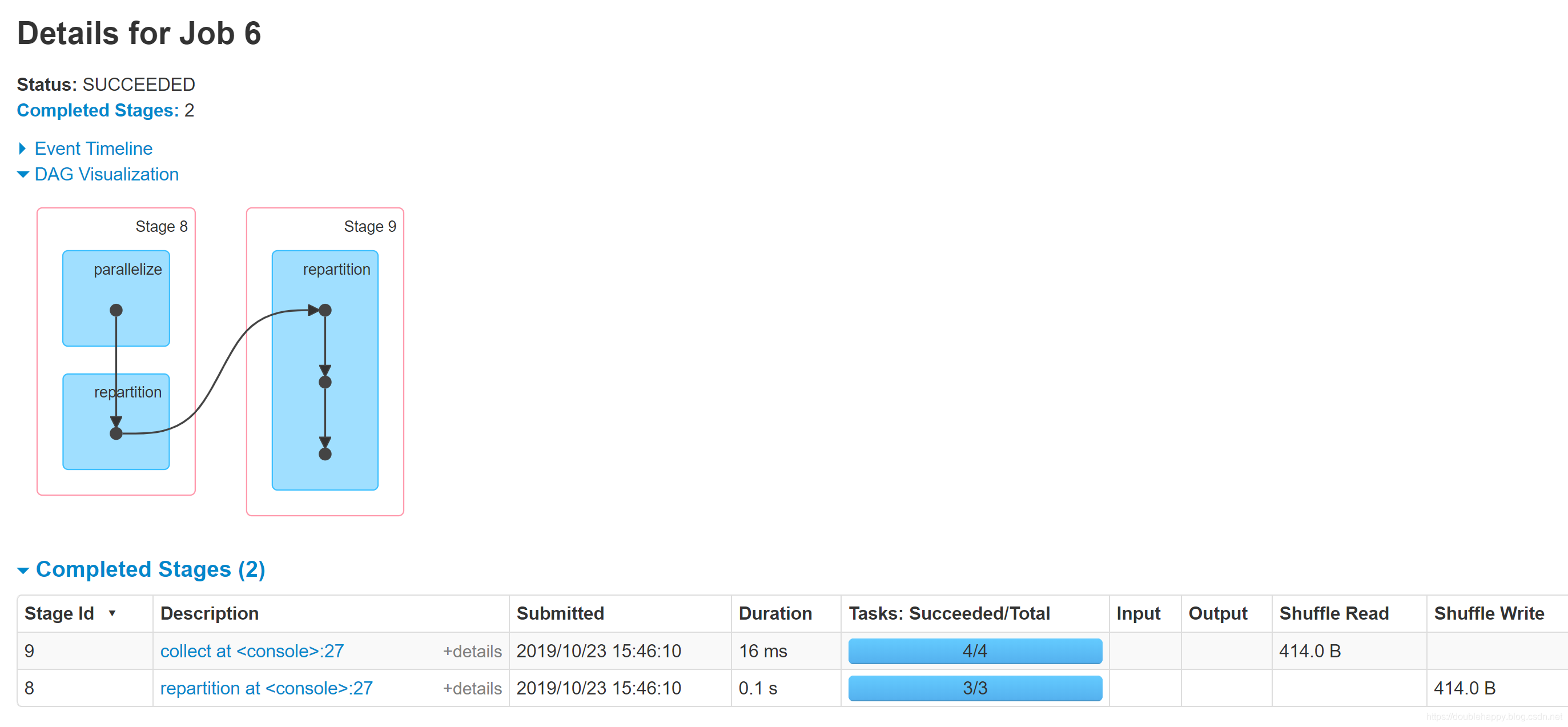
1 | 1.能够说明 repartition是走shuffle的 |
coalesce
1 | /** |
1 | scala> data.partitions.size |
1 | repartition调用的是coalesce算子,shuffle默认为true 会产生新的 stage |
Operations which can cause a shuffle include repartition operations like repartition and coalesce,
所以这句话 coalesce 默认是不会产生shuffle的 官网这话不严谨。