1 | 1.数据如下 |
1 | package com.ruozedata.spark.spark04 |
1 | 2.广告投放 收费标准: |
1 | 使用reduceBykey和groupBykey都实现一下: |
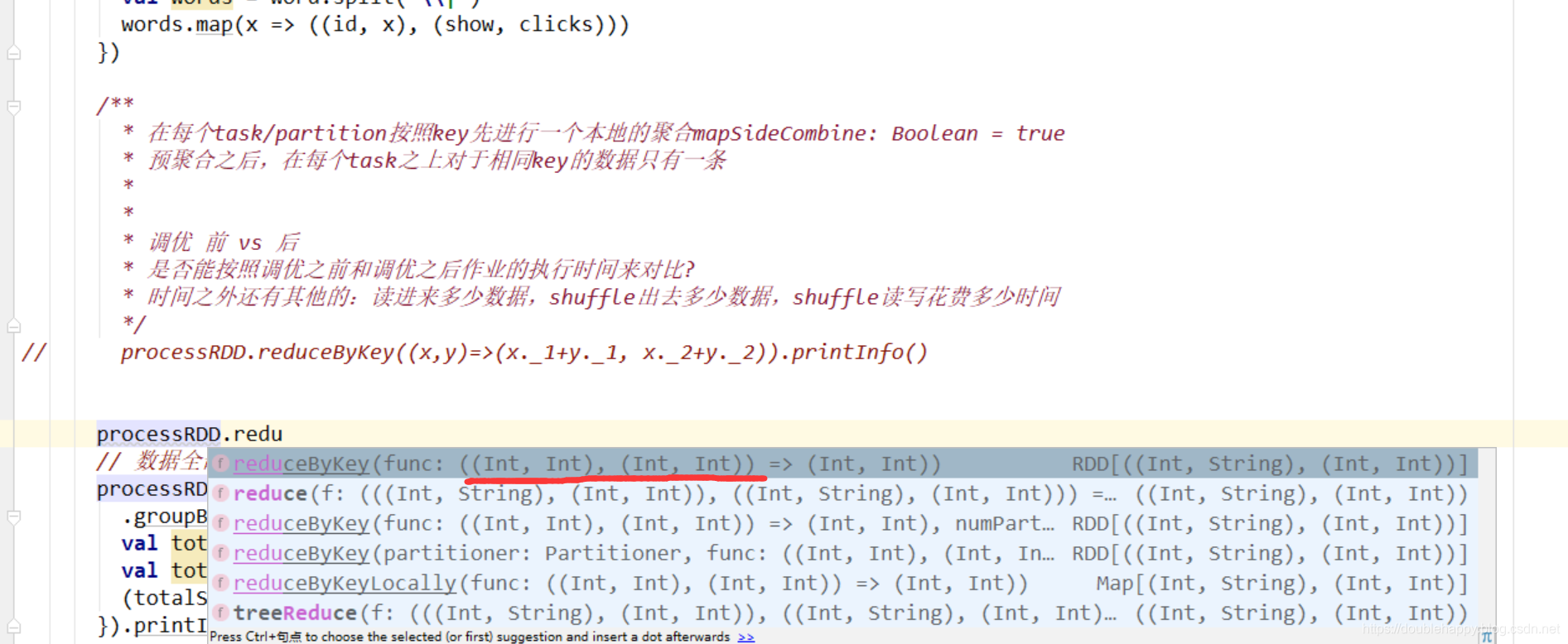
一定要注意数据结构
1 | object InterviewApp02 { |
1 | 3. 分组排序/组内排序 |
我们一步步来:
1 | object InterviewApp03 { |
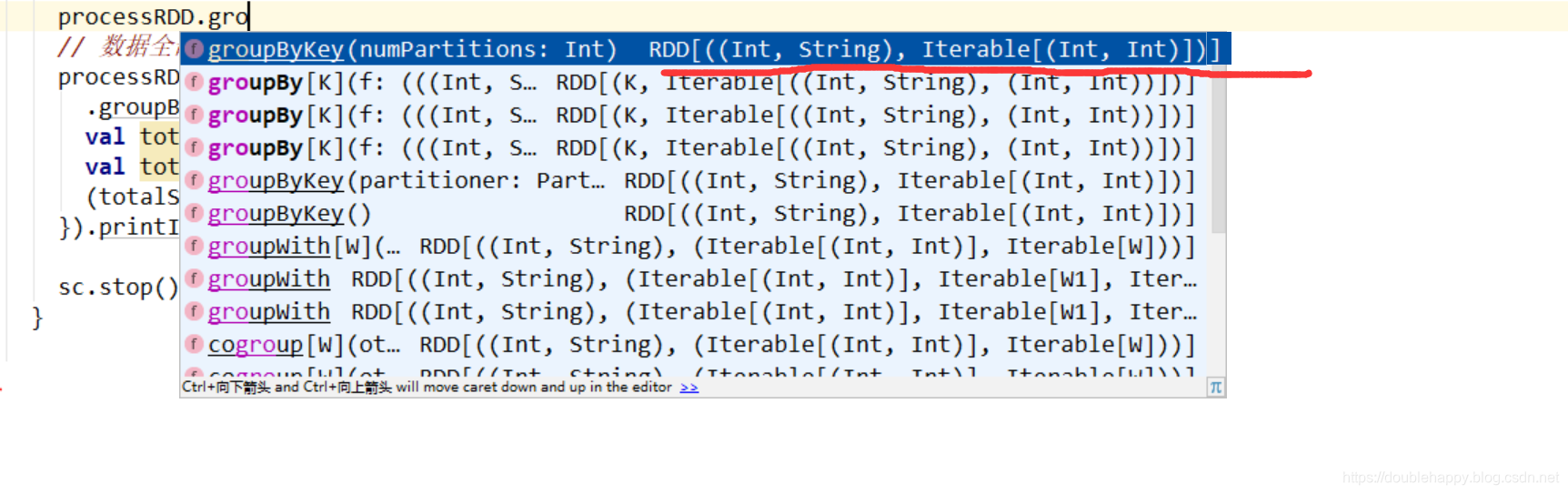
分组 : 如何分组? 不分组行不行?
1 | object InterviewApp03 { |
结果:
1 | object InterviewApp03 { |
x.toList.sortBy(-.2) // toList是一个很大的安全隐患,为什么这么说呢?
x来了一亿条数据 list就炸掉了 所以这样 虽然能出结果 但是不能用
如何规避掉呢 这块就使用rdd算子 不用scala的高级函数
1 | 如何解决呢? |
1 | 方法2; 优化方法1 |
Partitioner
1 | def reduceByKey(func: (V, V) => V): RDD[(K, V)] = self.withScope { |

1 | def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length) |
1 | def groupByKey(): RDD[(K, Iterable[V])] = self.withScope { |
多路径输出 ***定制化业务
1 | 日志格式: |
1.假设按照不同的 品牌进行落盘
1 | 输出的时候相当于根据某一个字段进行输出 |
我们一步一步的来:
1 | object MulitOutputApp { |
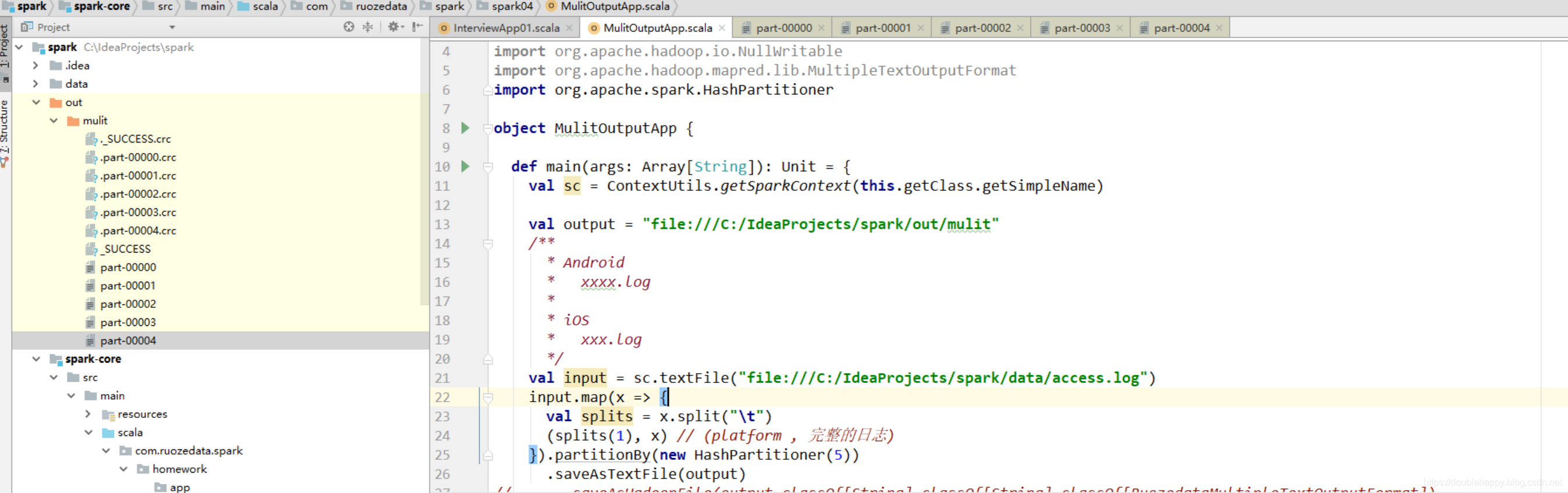
1 | 所有日志到在一个文件夹下: |
1 | 1.我们是要把某一个字段作为输出文件夹名 |
1 | class MyDataMultipleTextOutputFormat extends MultipleTextOutputFormat[Any,Any]{ |
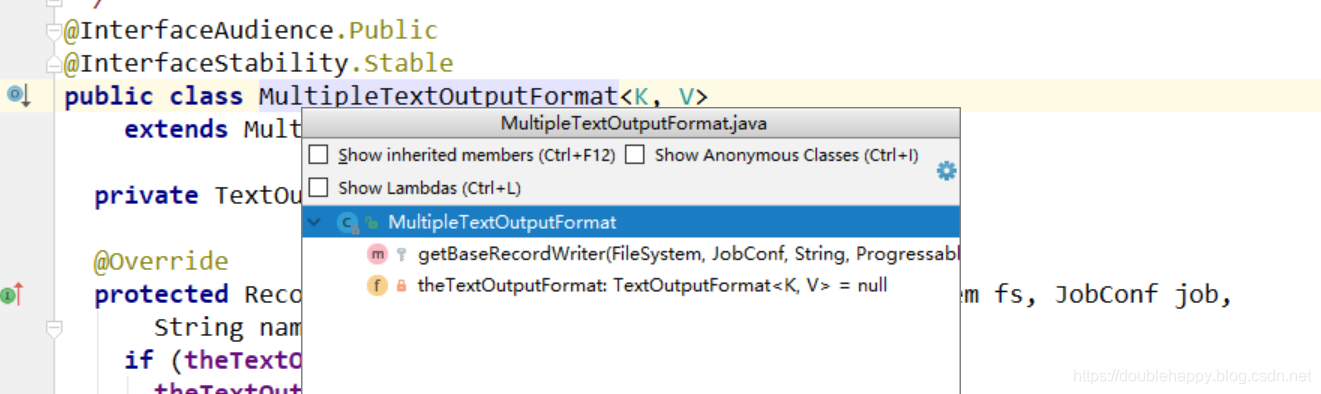
没有自己想要的方法,继续看MultipleTextOutputFormat的父类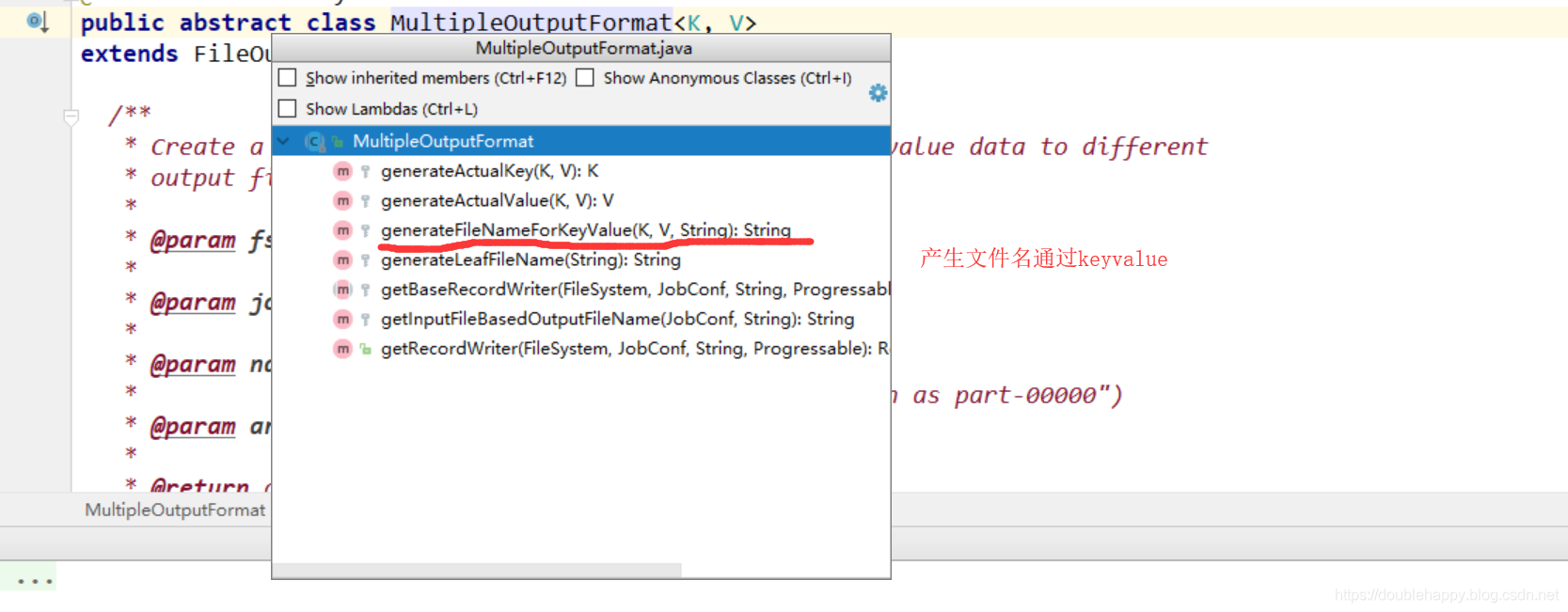
1 | class MyDataMultipleTextOutputFormat extends MultipleTextOutputFormat[Any,Any]{ |

1 | /** |
1 | object MulitOutputApp { |
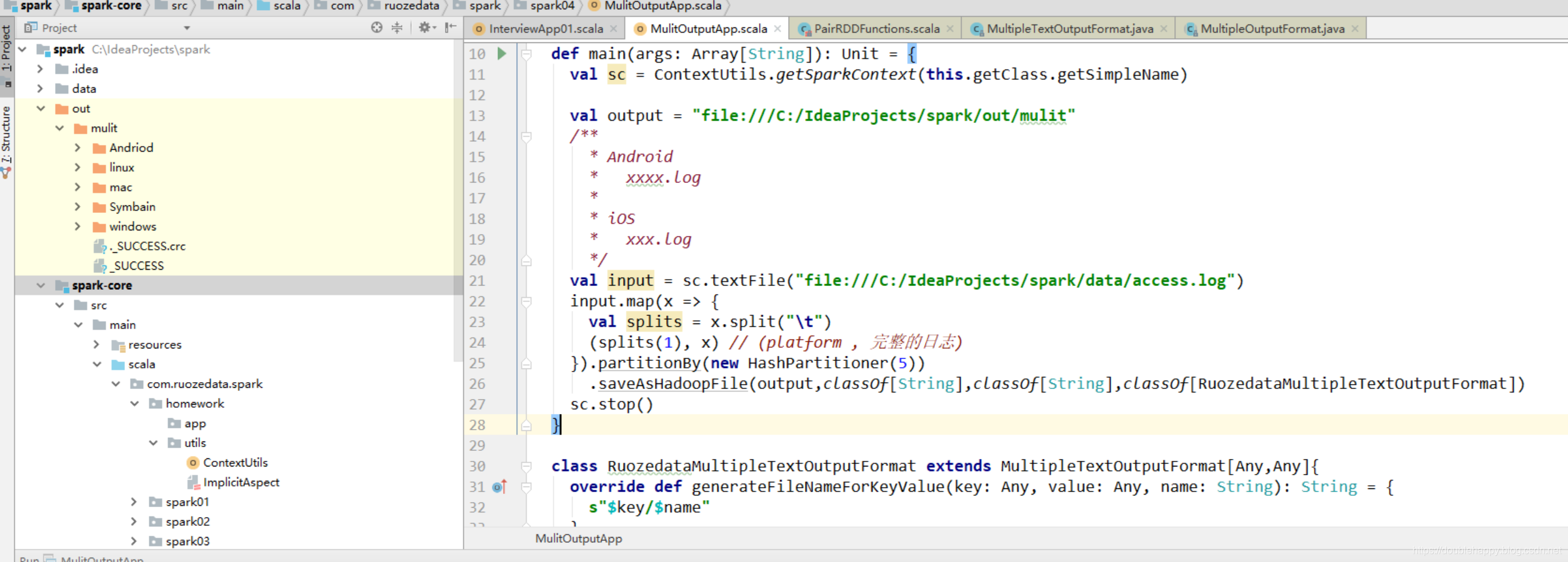
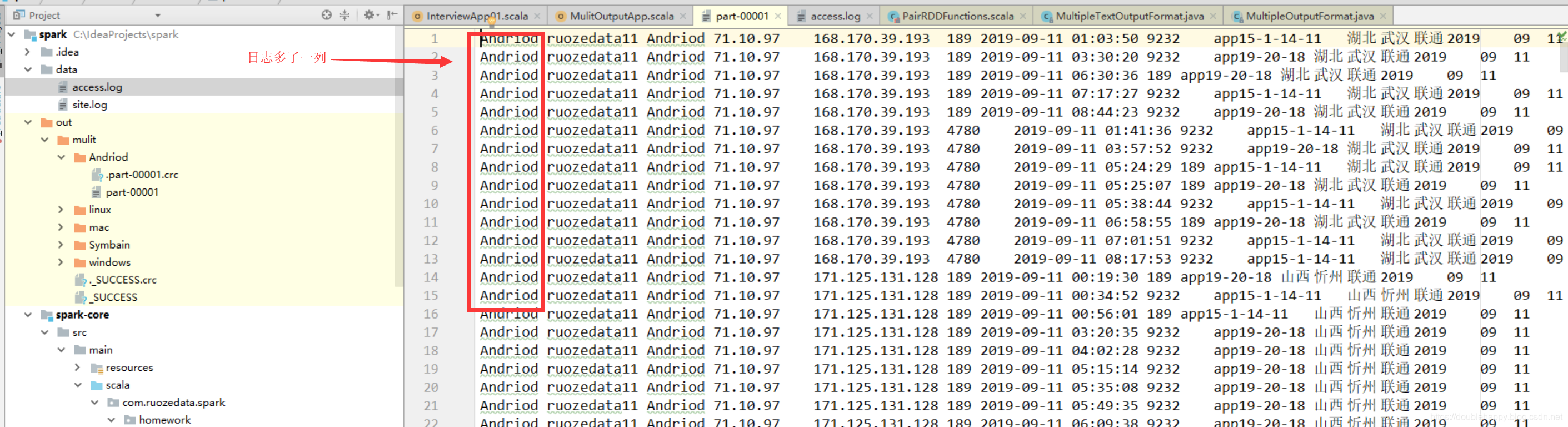
怎么才能去掉呢?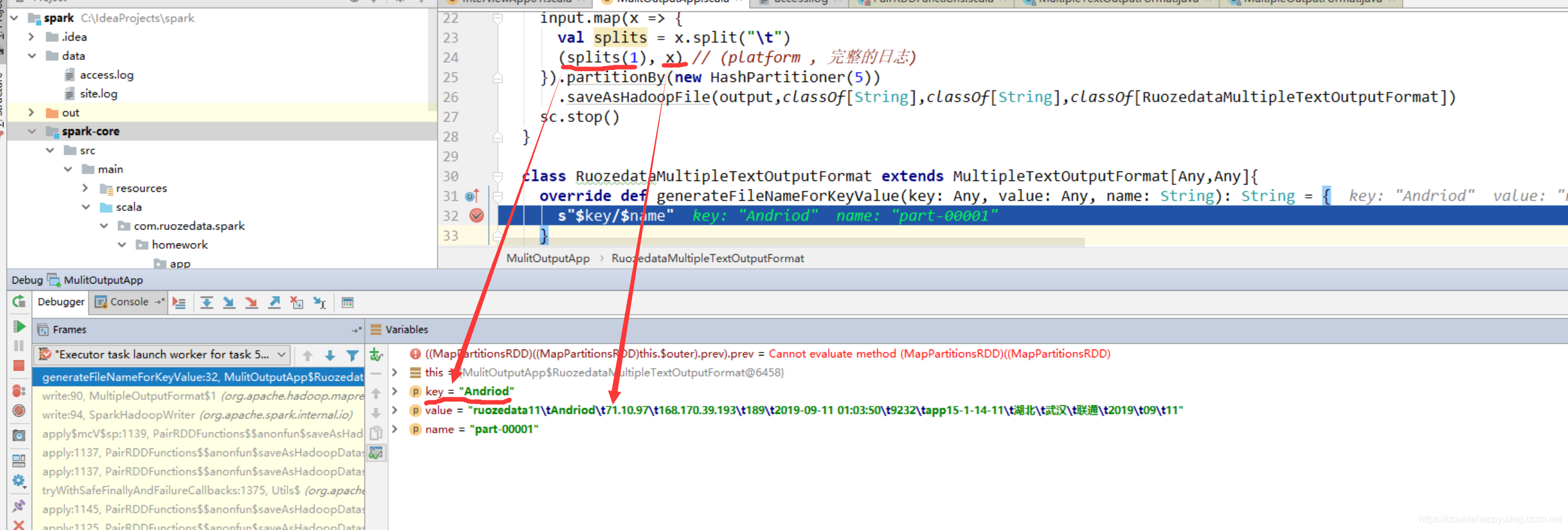
1 | 知道了kv代表了什么。那么如何去掉文件里的多出那一列key值呢? |
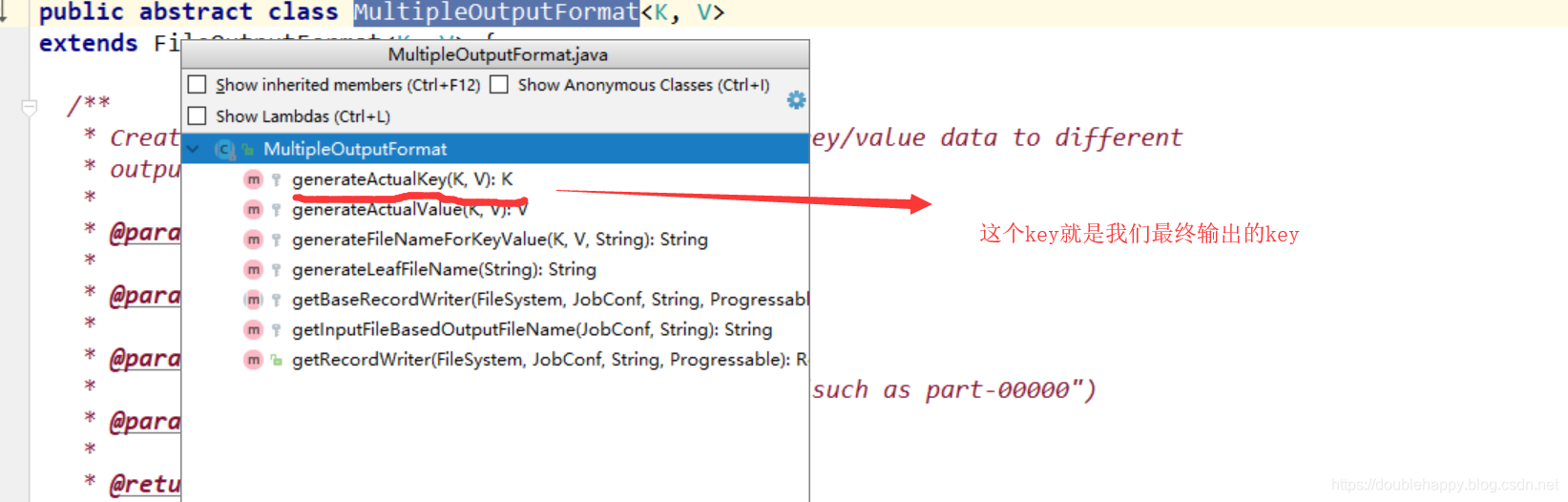
1 | 默认generateActualKey 返回是最终输出的key 所以我们自定义的类里 重写这个方法 就ok了 |
1 | class RuozedataMultipleTextOutputFormat extends MultipleTextOutputFormat[Any,Any]{ |
1 | object MulitOutputApp { |
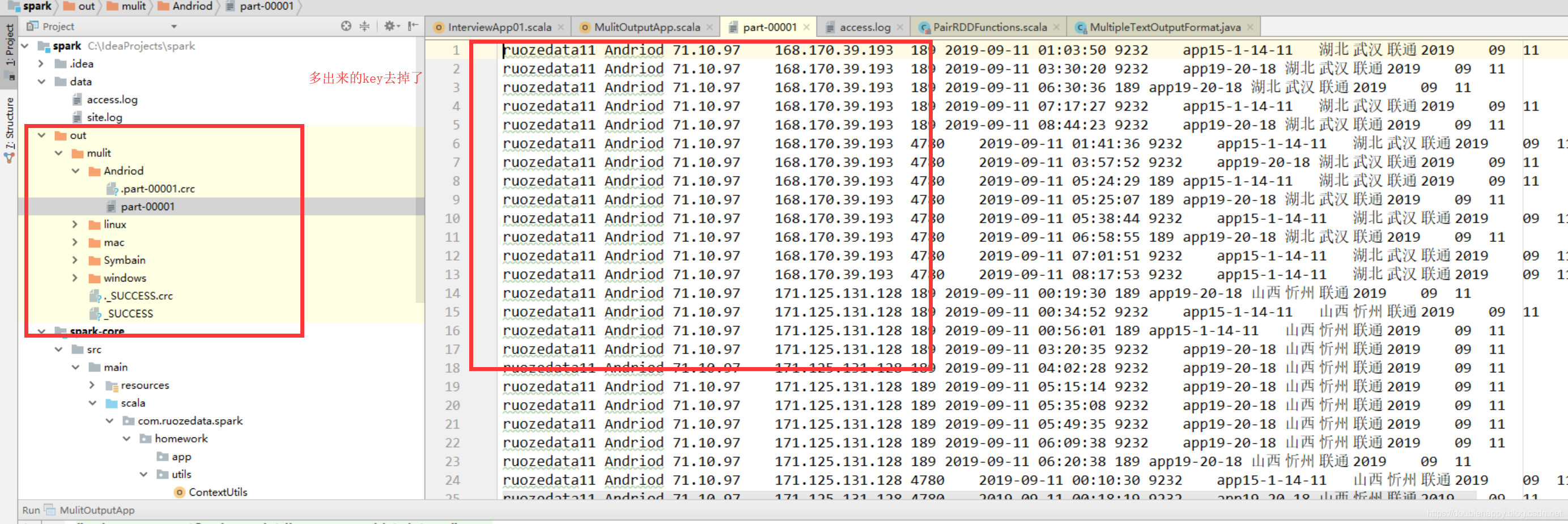
基本功能实现完成