RDD操作
转换
转换操作不会立即执行的,不触发作业的执行
1 | RDD操作 |
官网RDD算子介绍:
RDD Operations:
RDDs support two types of operations: transformations, which create a new dataset from an existing one, and actions, which return a value to the driver program after running a computation on the dataset. For example, map is a transformation that passes each dataset element through a function and returns a new RDD representing the results. On the other hand, reduce is an action that aggregates all the elements of the RDD using some function and returns the final result to the driver program (although there is also a parallel reduceByKey that returns a distributed dataset).
All transformations in Spark are lazy, in that they do not compute their results right away. Instead, they just remember the transformations applied to some base dataset (e.g. a file). The transformations are only computed when an action requires a result to be returned to the driver program. This design enables Spark to run more efficiently. For example, we can realize that a dataset created through map will be used in a reduce and return only the result of the reduce to the driver, rather than the larger mapped dataset.
By default, each transformed RDD may be recomputed each time you run an action on it. However, you may also persist an RDD in memory using the persist (or cache) method, in which case Spark will keep the elements around on the cluster for much faster access the next time you query it. There is also support for persisting RDDs on disk, or replicated across multiple nodes.
1 | This design enables Spark to run more efficiently: |
Transformations讲解前的说明
先说明我们的程序里创建SparkContex的方式,由于每次创建都要写appname,master,以及RDD数据集在Driver端打印出来查看都要写foreach(println),每次都要写很麻烦,这里我们给封装一下。
效果展示:
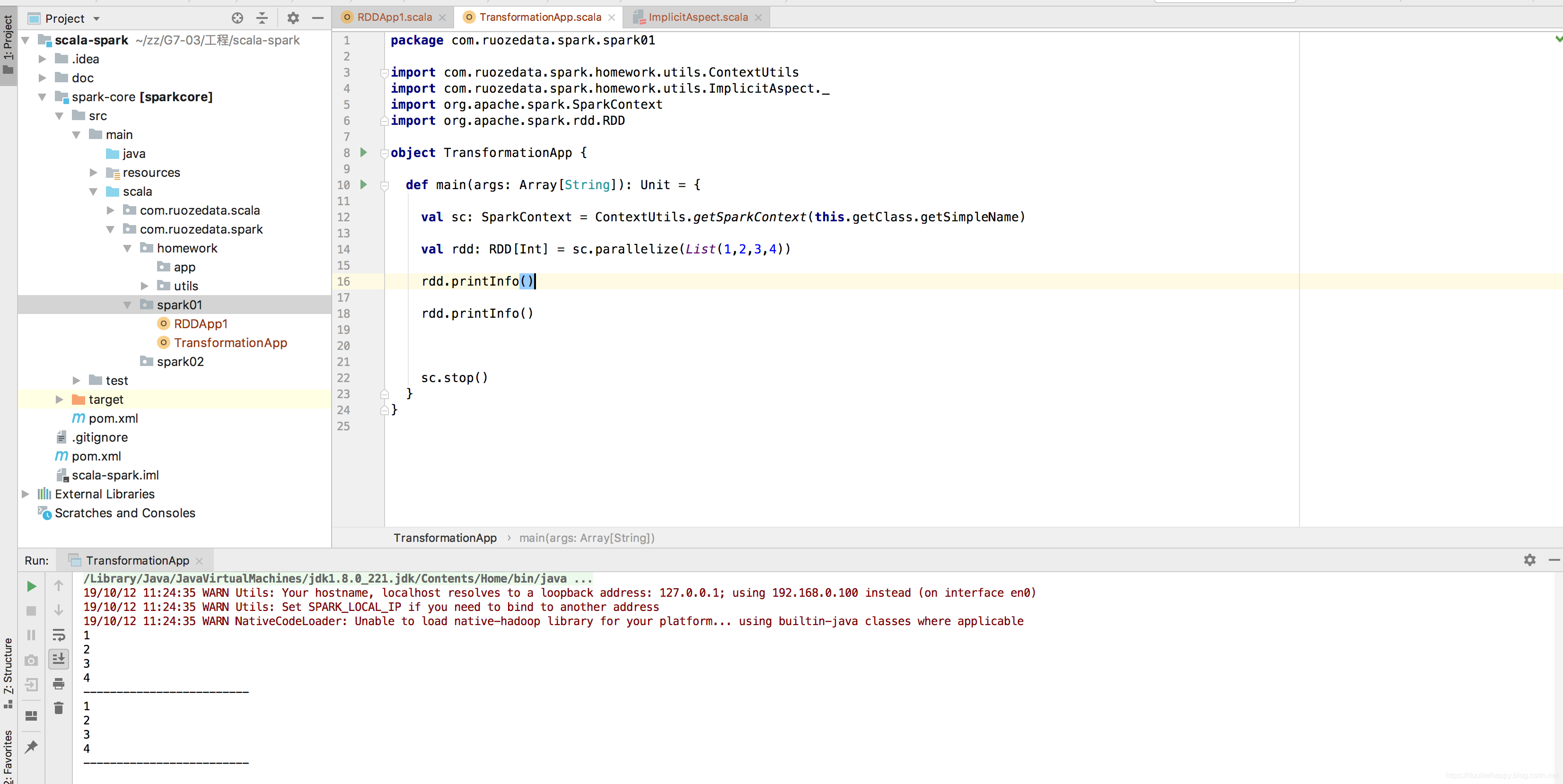
如果我不想输出 我输入一个1进去即可: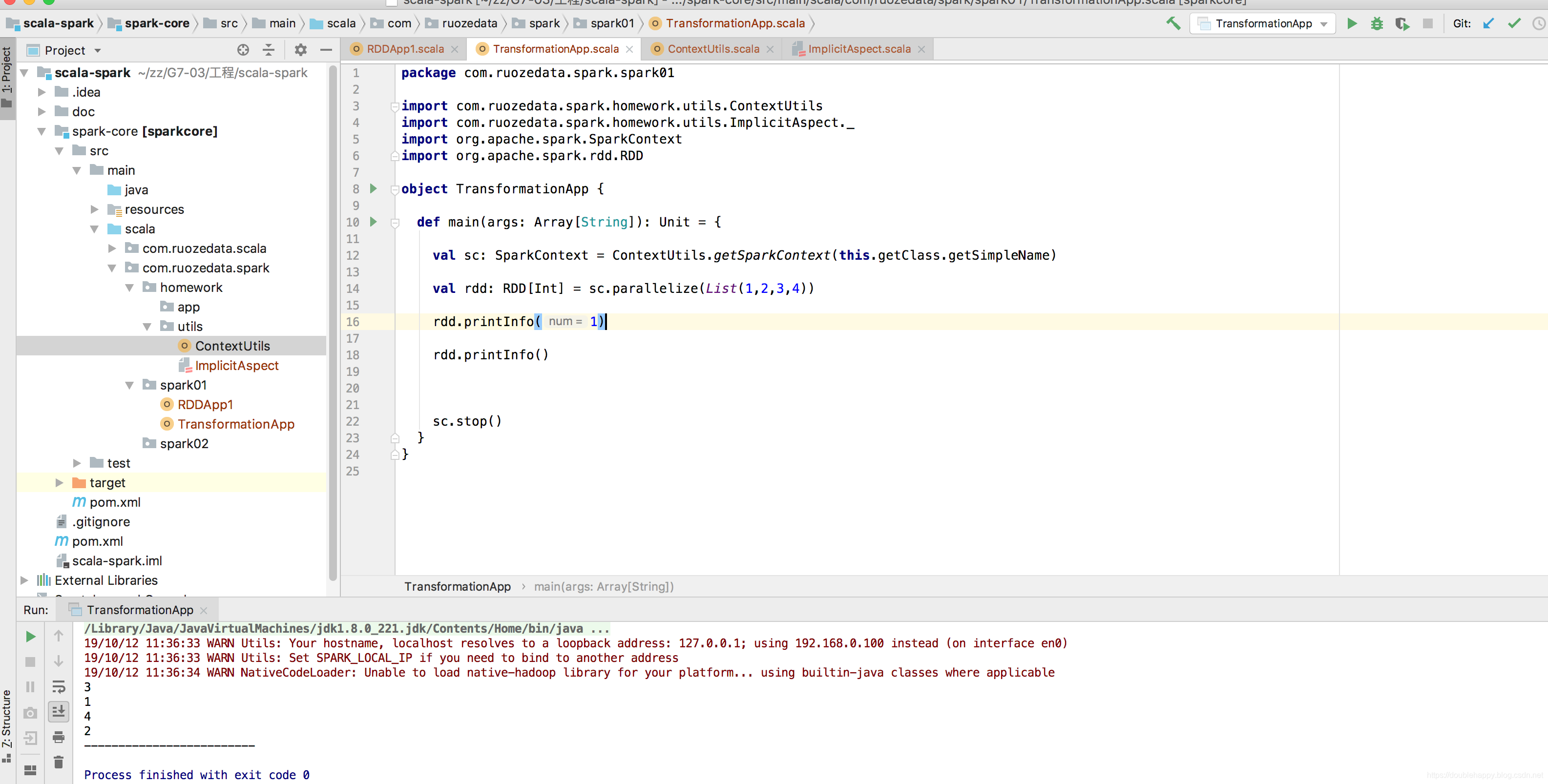
这是自己写的哈 ,老师上课留的作业 人家要求动手能力。不会全部给你,让你做一个伸手党就没意义。
1 | package com.ruozedata.spark.homework.utils |
下面这个主要使用隐式转换,看不懂可以查看Scala博客:
1 | package com.ruozedata.spark.homework.utils |
Transformations
源码面前,了无秘密。通过源码进行学习
(1)Map相关的算子
1 | 1.makeRDD / parallelize |
1 | 2.map : 处理每一条数据 |
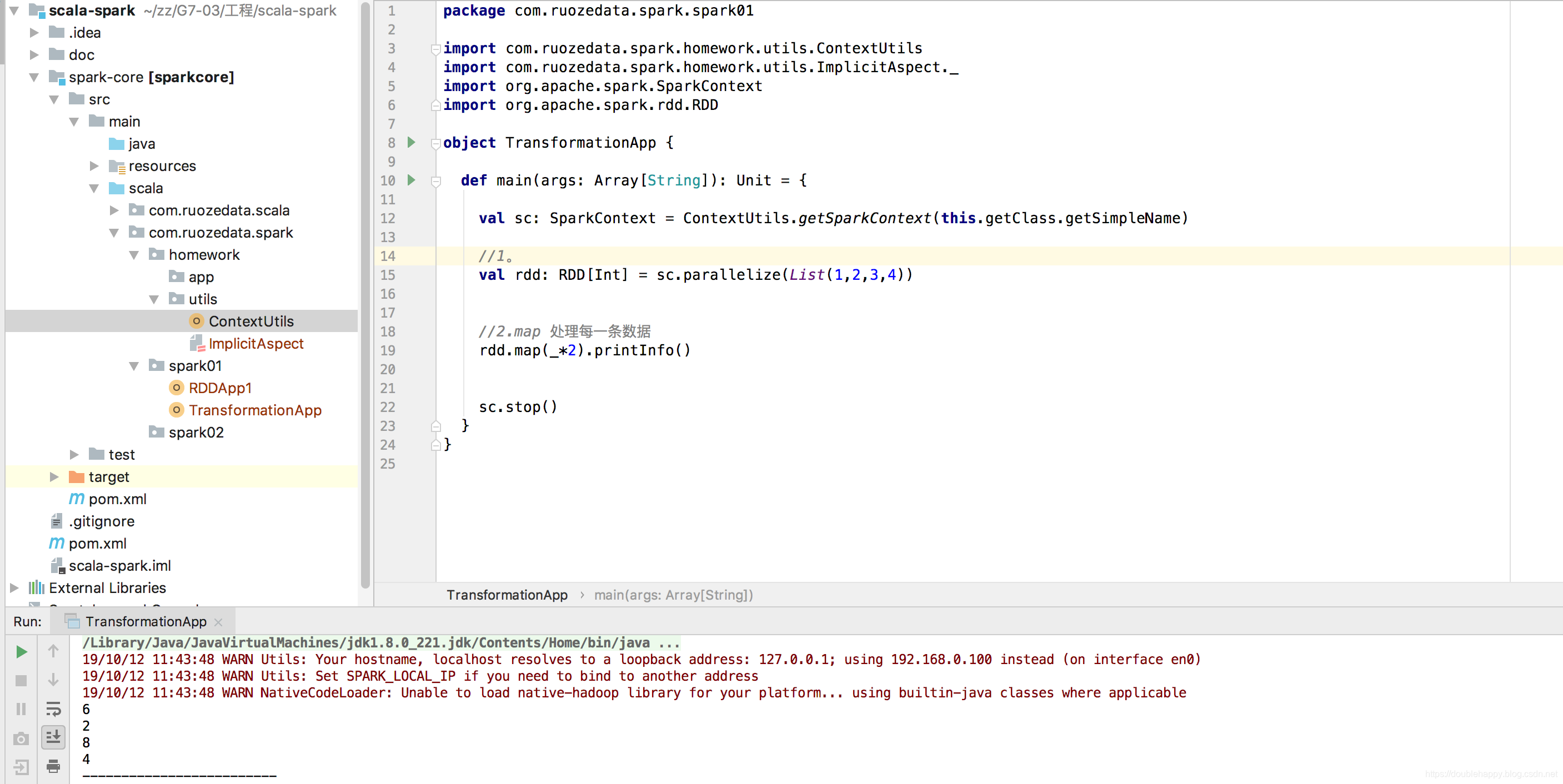
1 | RDD是有多个partition所构成的, |
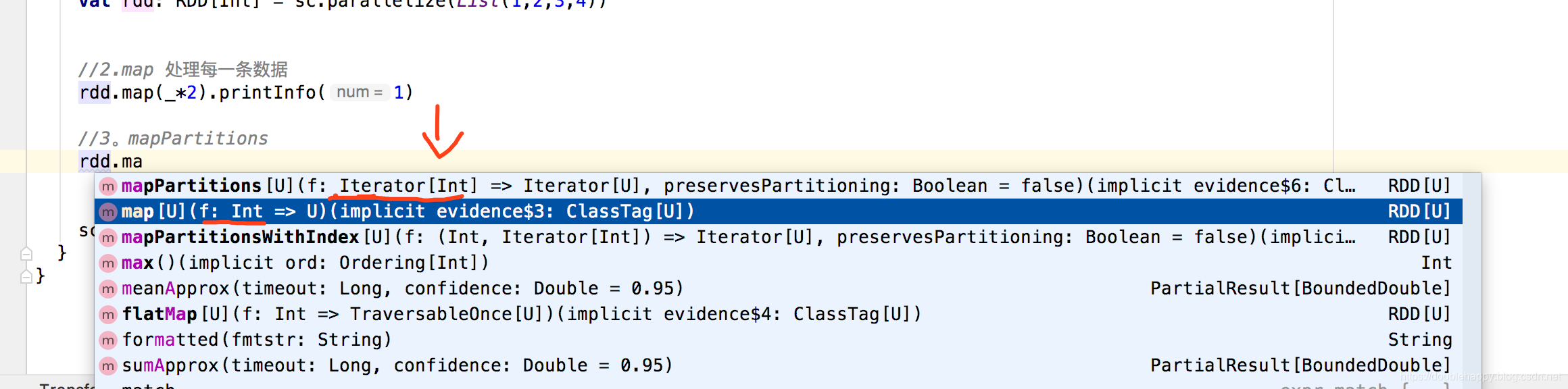
一个是作用于每个元素,一个是作用于每个分区。
这是作用于每个分区里的每个元素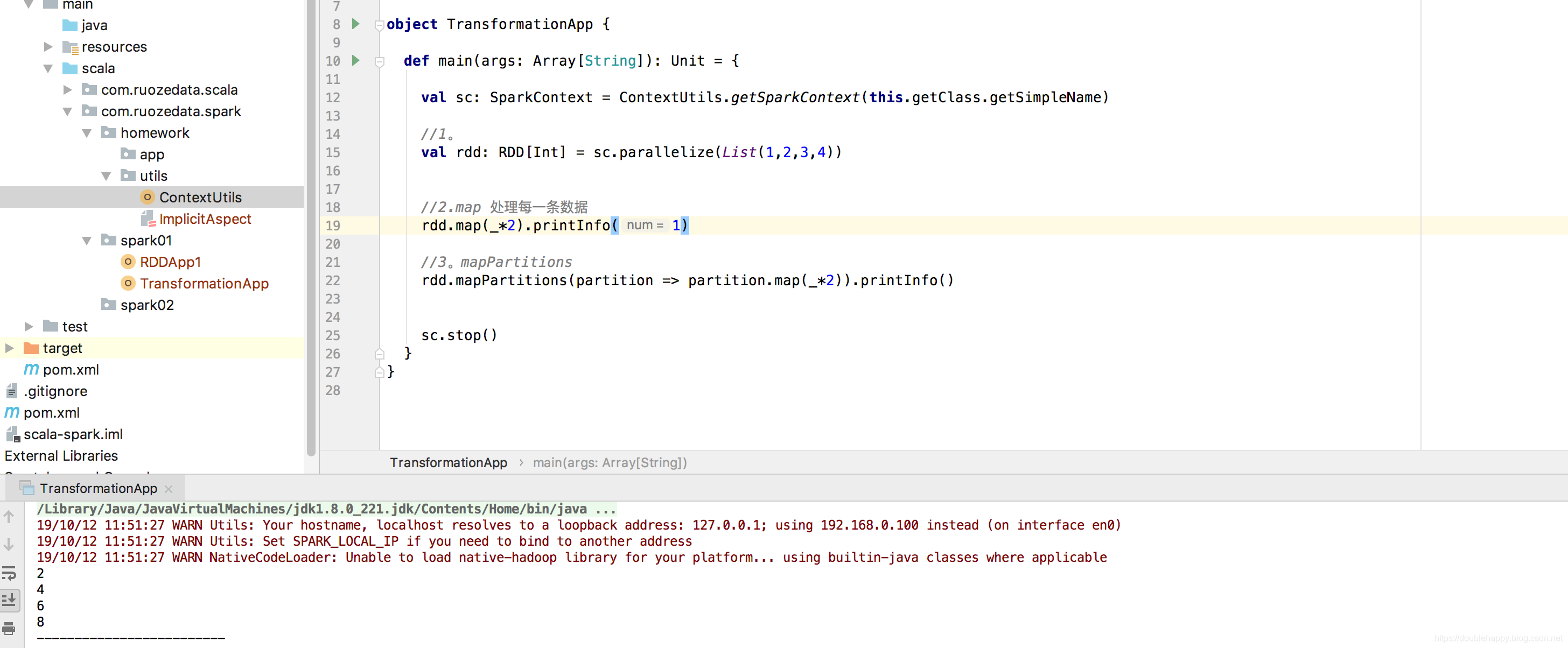
结果和map是一样的。
1 | 总结: |
1 | 4.mapPartitionsWithIndex |
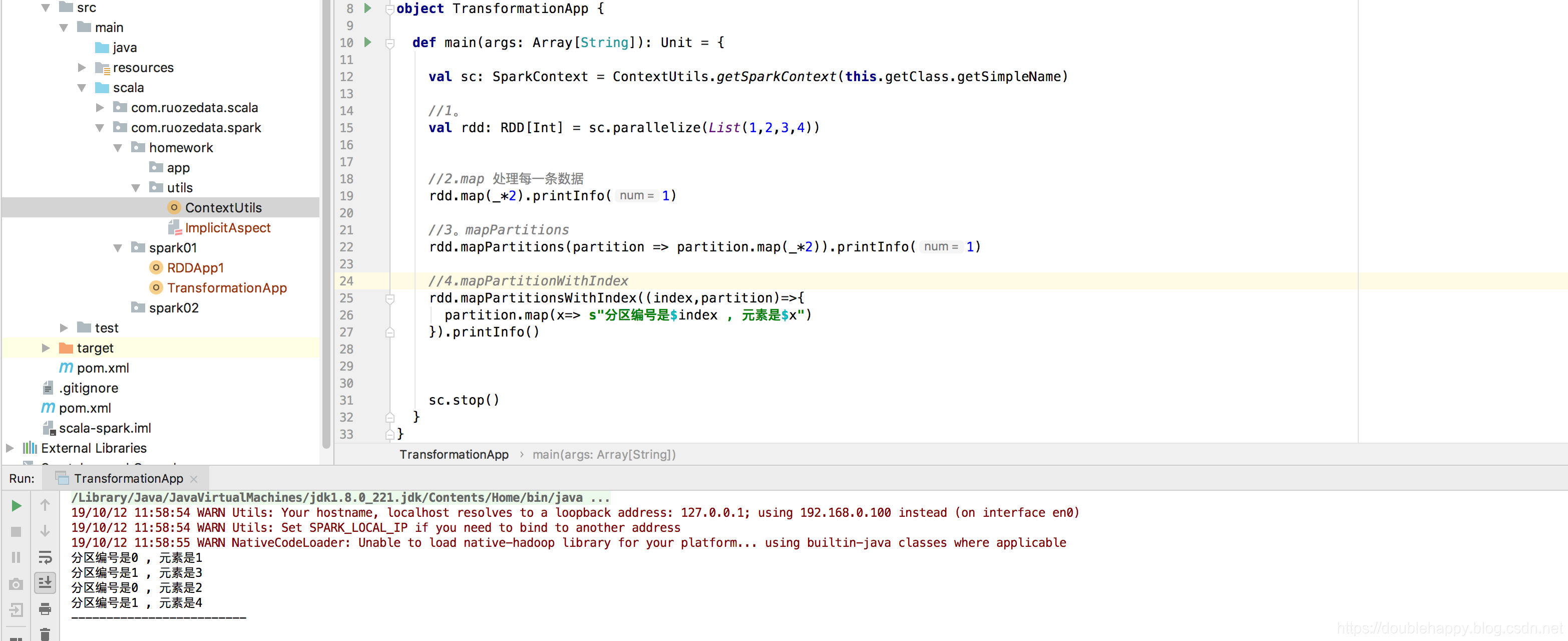
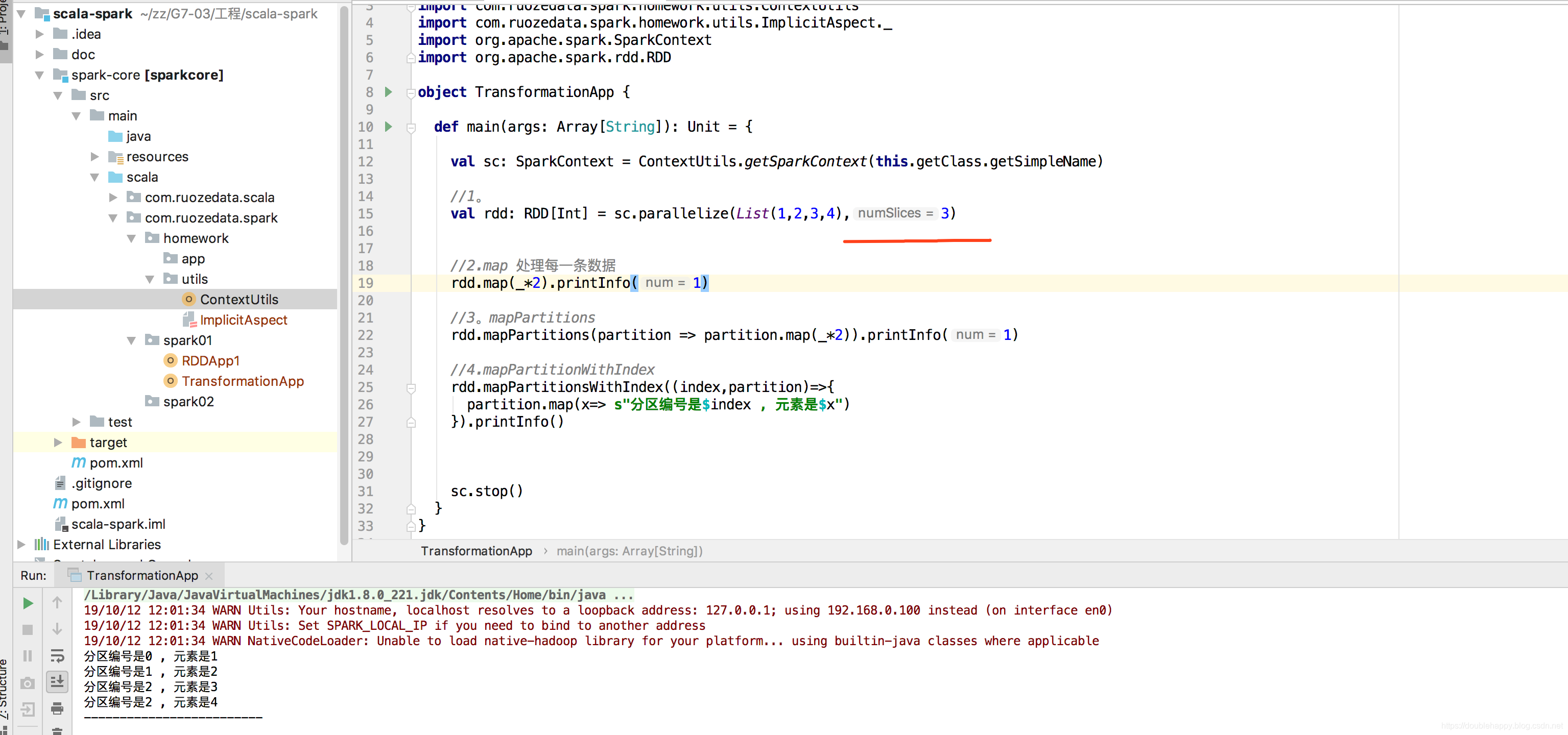
元素为什么这么存放的呢?之后再来讲解。
生产上是不关注这个分区里的哪个元素的 只是用来学。
1 | 5.mapValues |

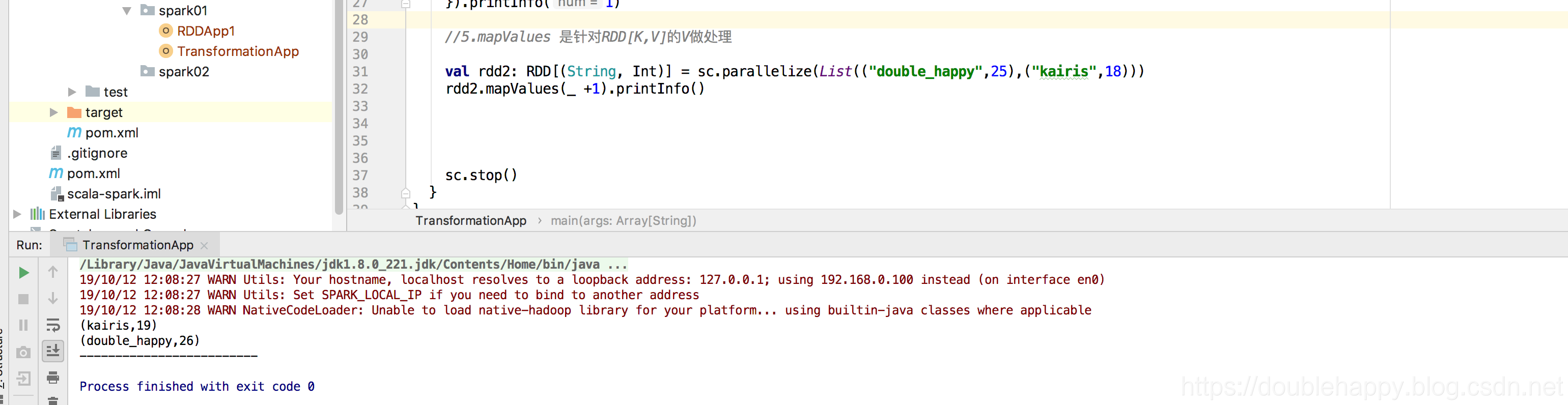
1 | 6.flatmap = map + flatten 就是打扁以后 做map |
对比map:
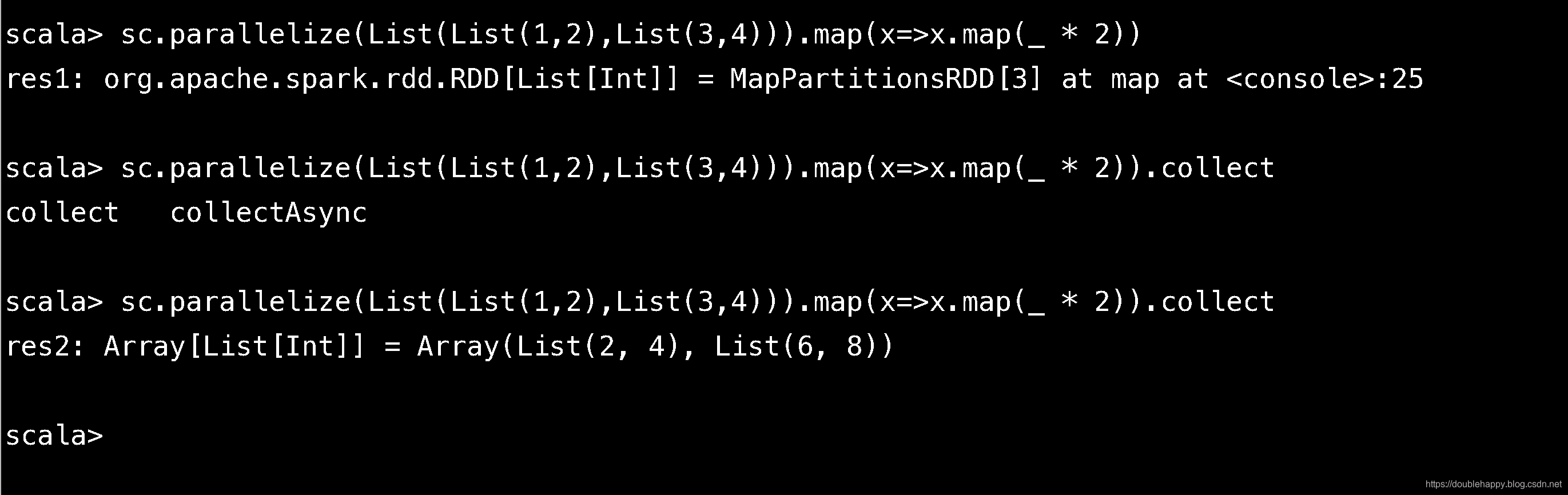
map对里面元素做处理,是不会改变 内部的结构的 。
flatMap:
结果: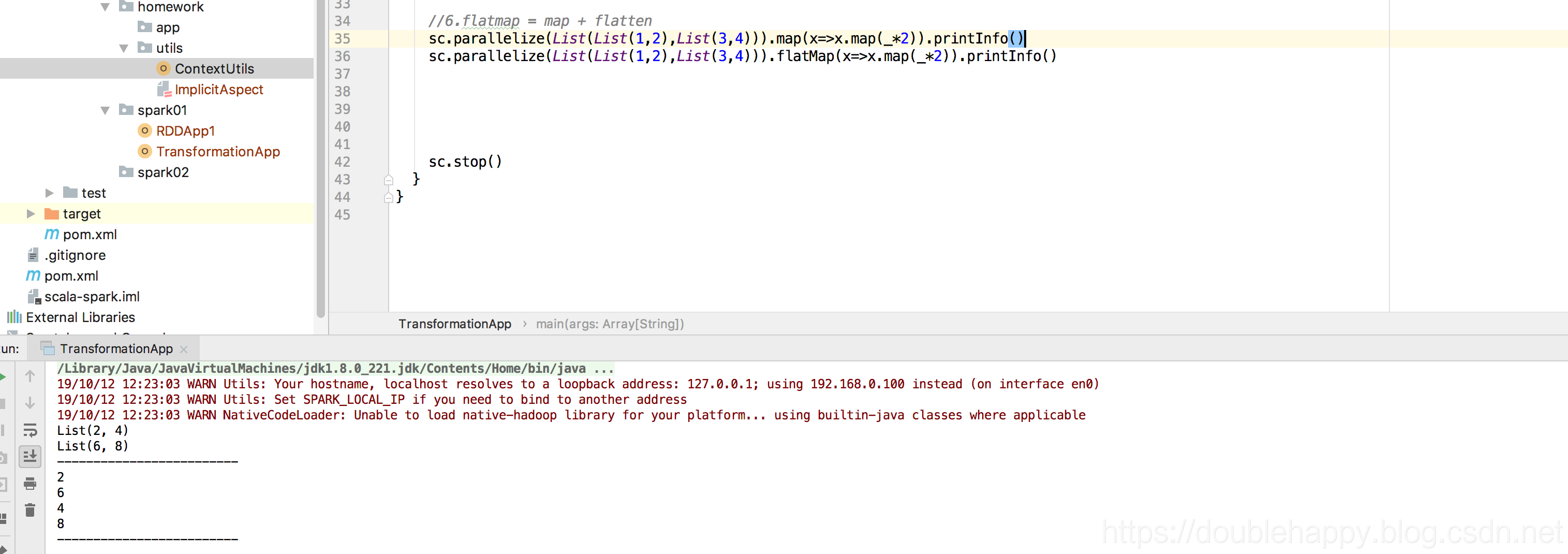
1 | 秀操作的:没什么用 |
(2)glom
1 | glom:把每一个分区里的数据 形成一个数组 比mapwithindex好用 |
1 | scala> sc.parallelize(1 to 30).glom().collect |
(3)sample
1 | sample: |
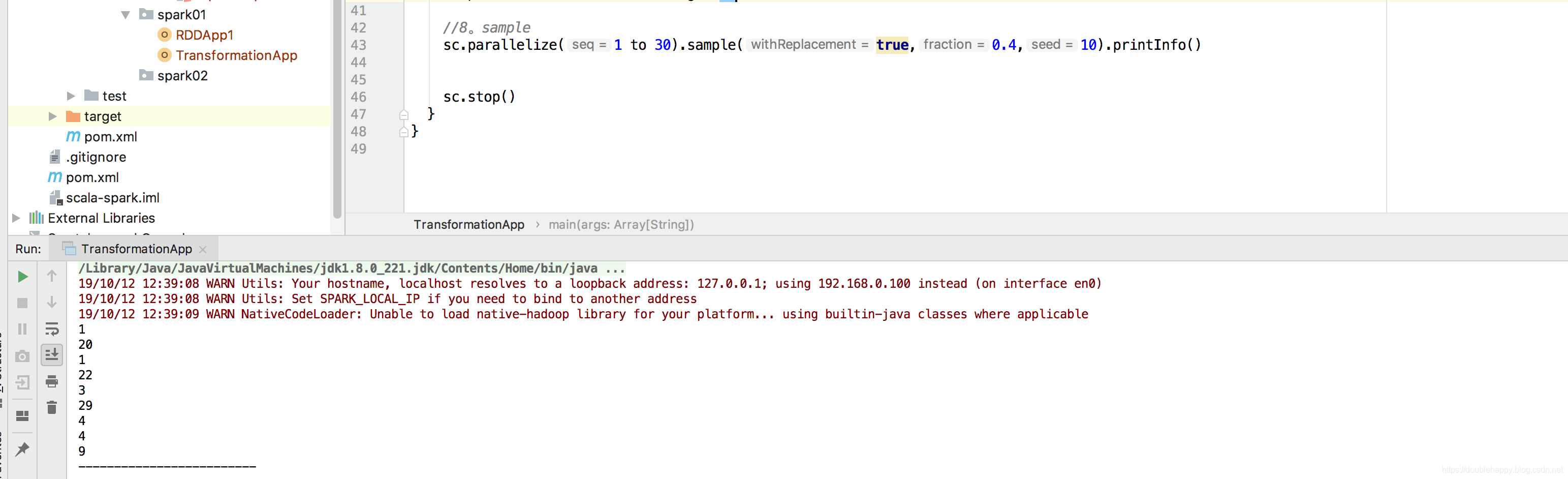
1 | 解释: |
(4)filter
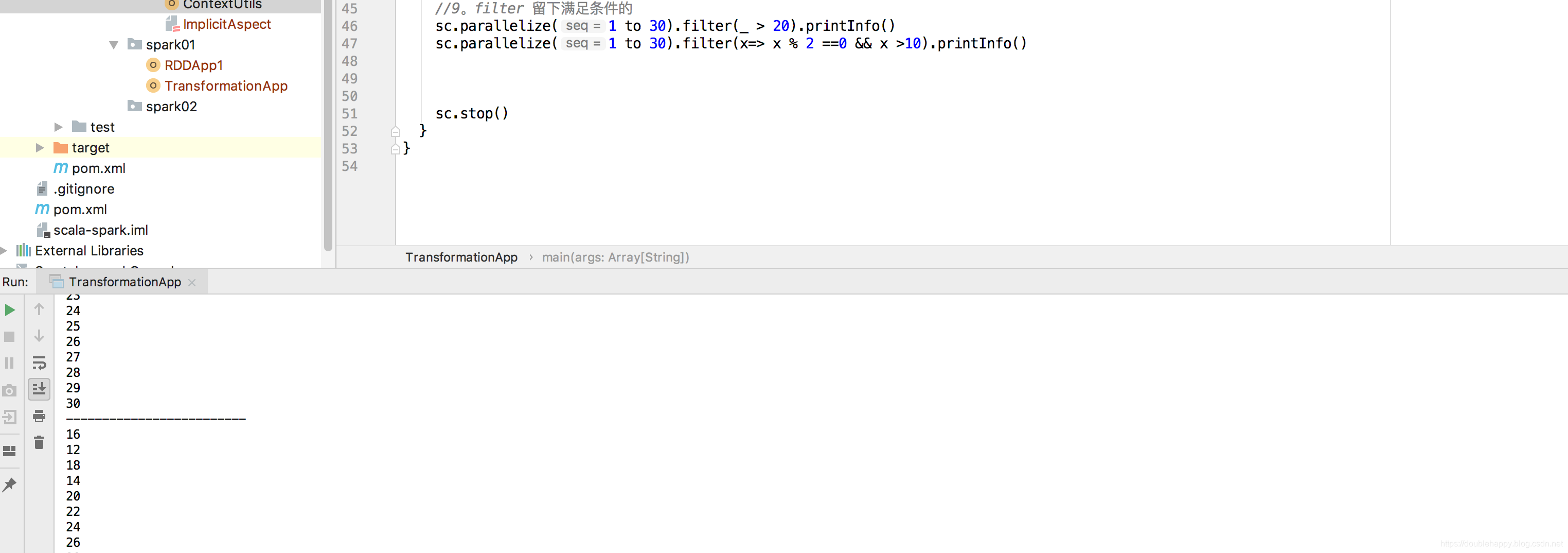
1 | scala> sc.parallelize(1 to 30).filter(_ > 20).collect |
(5)other类型的
1 | union: 就是简单的合并 是不去重的哈 |
1 | scala> val a = sc.parallelize(List(1,2,3,4,5,6)) |
1 | intersection: 交集 |
1 | scala> val a = sc.parallelize(List(1,2,3,4,5,6)) |
1 | subtract:差集 出现在a里面的没有出现在b里面的 叫差集 |
1 | scala> val a = sc.parallelize(List(1,2,3,4,5,6)) |
1 | 去重:distinct |
1 | scala>val b = sc.parallelize(List(4,5,6,77,7,7)) |
1 | 去重这块 是可以传入分区参数的 : 也可以没有的 没有的就是默认的分区 |
1 | scala>val b = sc.parallelize(List(4,5,6,77,7,7)) |
1 | 四个分区: 那是怎么分区的呢? 元素%partitions |
KV类型的
1 | groupKeyKey:不怎么用的哈 |
1 | scala> sc.parallelize(List(("a",1),("b",2),("c",3),("a",99))).groupByKey() |
接着上面的值 求相同的key的和 是多少使用什么算子呢? 上面讲过了哈
1 | scala> sc.parallelize(List(("a",1),("b",2),("c",3),("a",99))).groupByKey().collect |
1 | reduceByKey: |
distinct 底层
1 | /** |
1 | /** |
1 | org.apache.spark.rdd.RDD[(Int, Null)] :一定要看清reduceByKey的数据结构哈 |
所以使用常用的算子一定要手点进去看看底层的实现哈 。
个人理解 这个算子超重要
1 | groupBy:自定义分组 分组条件就是自定义传进去的 |
1 | 参数是传入一个分组条件 怎么传呀?不要紧 可以测试 |
1 | 那我给一个需求:把上面的字母次数算出来 |
1 | sortBy:自定义排序 你想怎么排序就怎么排序 默认是升序的 |
1 | scala> sc.parallelize(List(("double_happy",30),("老哥",18),("娜娜",60))).sortBy(_._2) |
1 | sortBykey:是按key进行排序的哈 注意和sortby的区别 sortby是自定义排序 非常的灵活 |
1 | sc.parallelize(List(("double_happy",30),("老哥",18),("娜娜",60))).sortByKey().collect |
Join
1 | join: 默认是内连接 |
1 | 第一个:名字 第二个:城市 第三个:年龄 (B,(上海,18)) |
1 | /** |
1 |
|
1 | scala> j1.fullOuterJoin(j2).collect |