Speed
Spark是支持pipline操作的,根据Shufle进行切分的,中间的过程是不落地的。
运行的角度来说:
线程的
mapreduce是进程的 map task 、reduce task
RDD
1.Represents an immutable,
partitioned collection of elements that can be operated on in parallel.
2.
1 | 5大特性: 弹性分布式数据集 |
程序开发入口
开发Spark应用程序
1)SparkConf
appName
master
2)SparkContext(sparkConf)
3)spark-shell –master local[2] 底层自动为我们创建了SparkContext sc
算子
1 | RDD:创建 |
1 | scala> val rdd = sc.parallelize(List(1,2,3,4)) |
并行度 –简单版
1 | scala> rdd |
产看ui界面: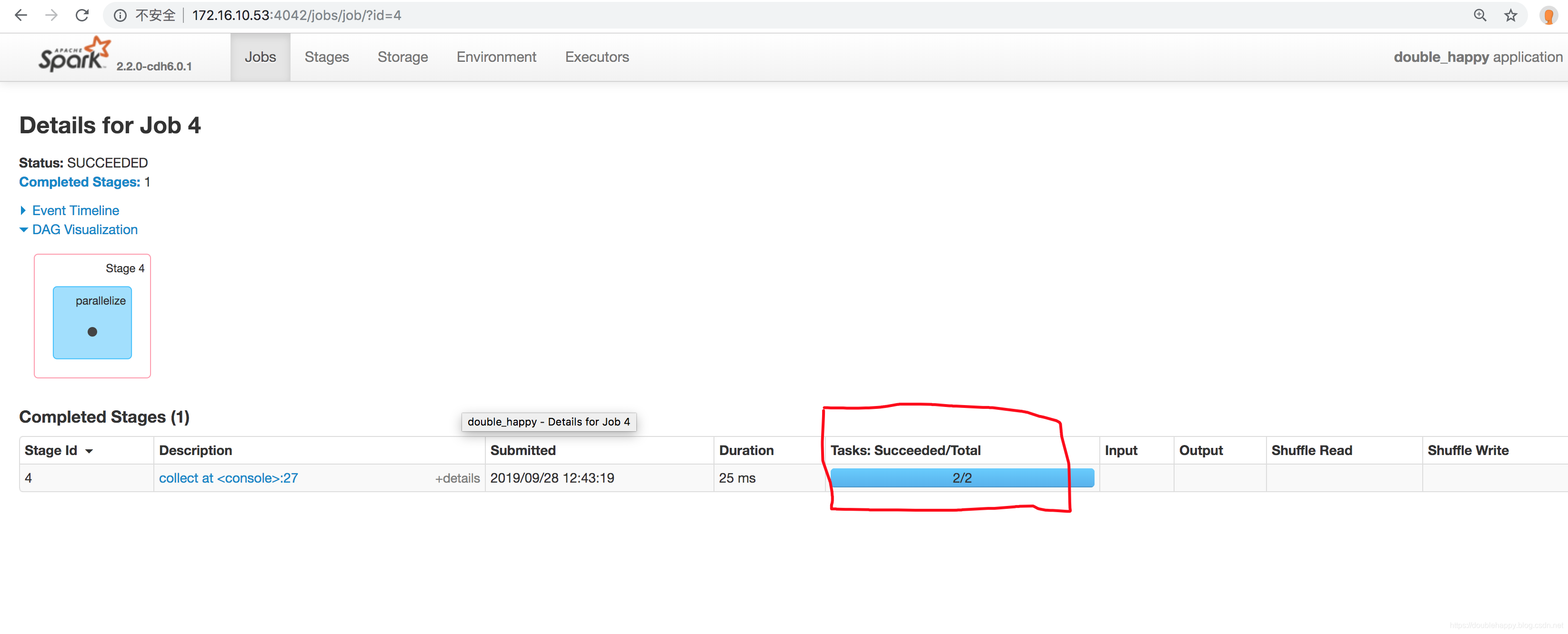
为什么是2呢?
查看源码:
1 | def parallelize[T: ClassTag]( |
1 | defaultParallelism: |
看他的实现的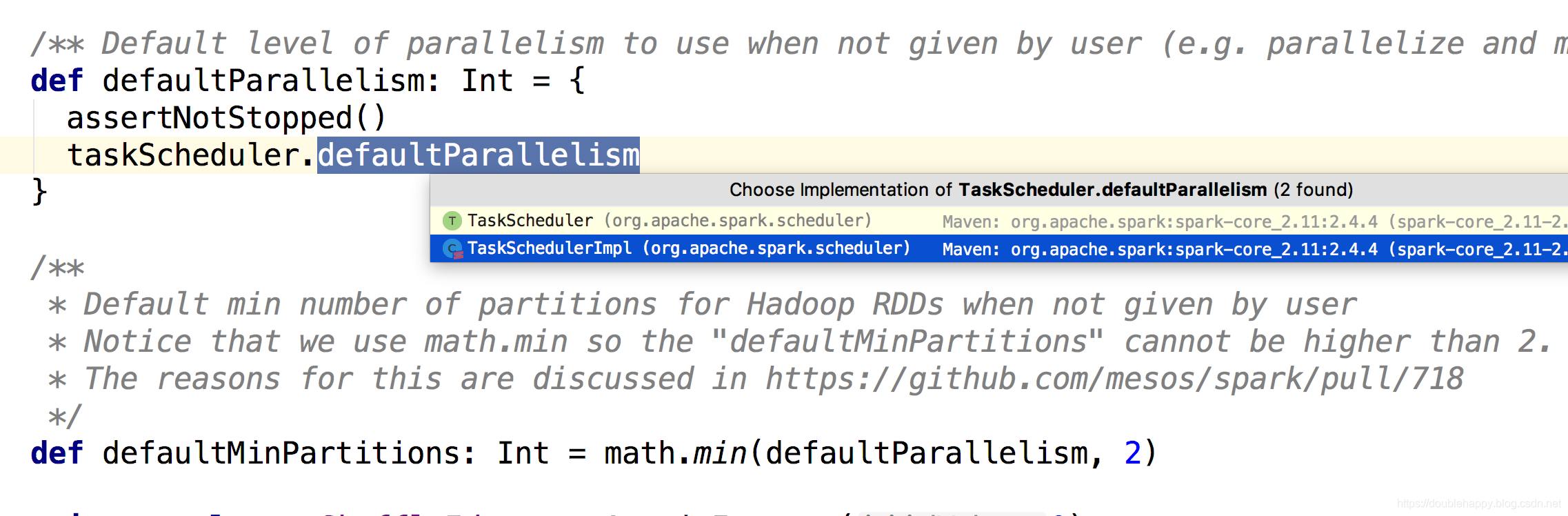
1 | taskScheduler.defaultParallelism: |
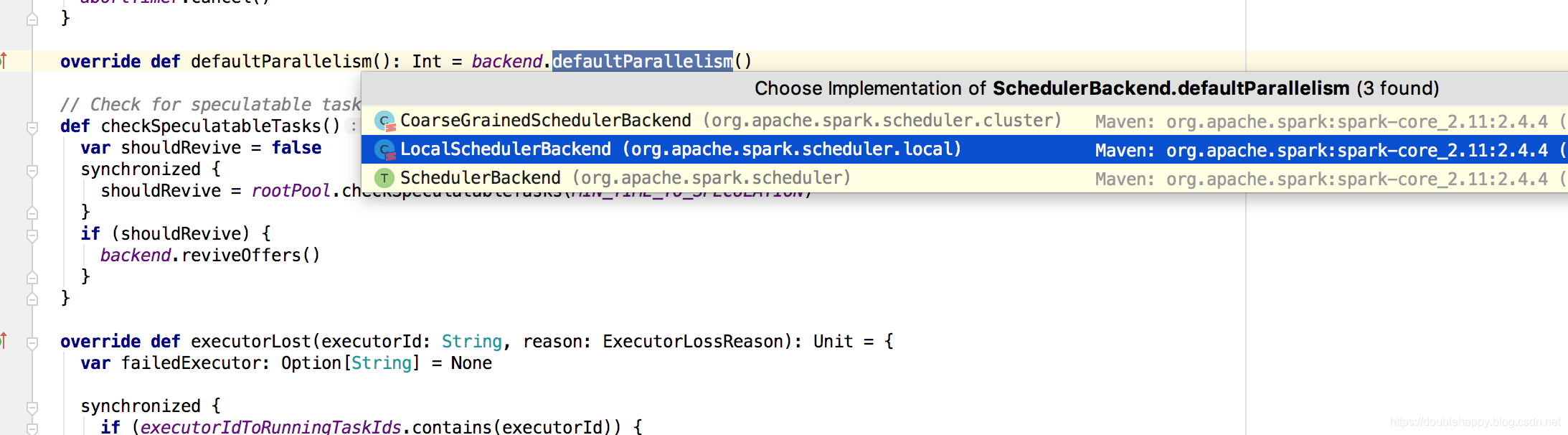
1 | 查看local的点进去: |