续集细节03
(8)抽象类
1 | /** |
(9)数据结构
1.数组: 长度可变、长度不可变
1 | 长度不可变: new 的方式创建 |
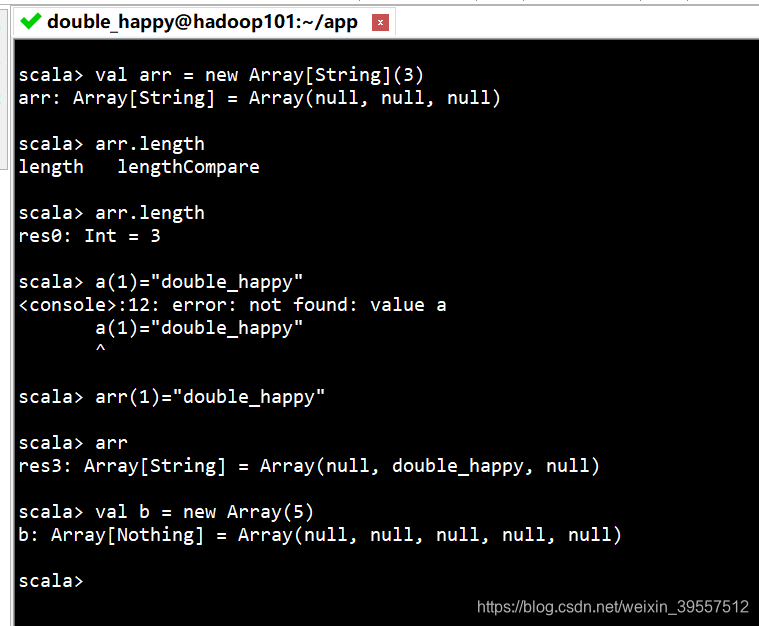
1 | 不用new的方式 : |
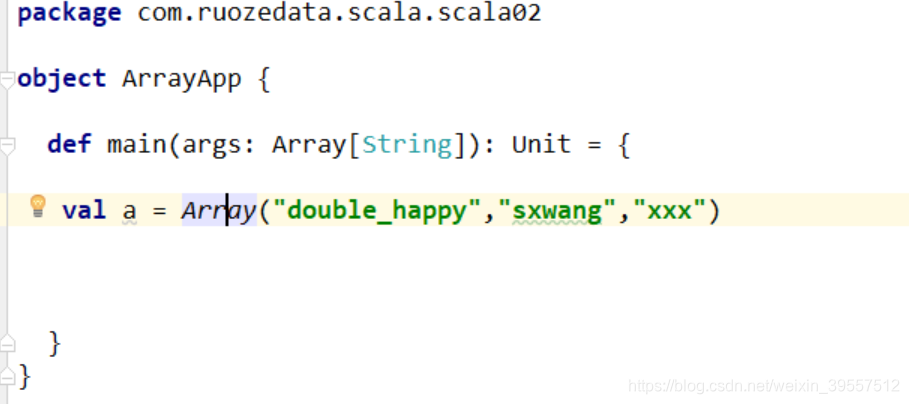
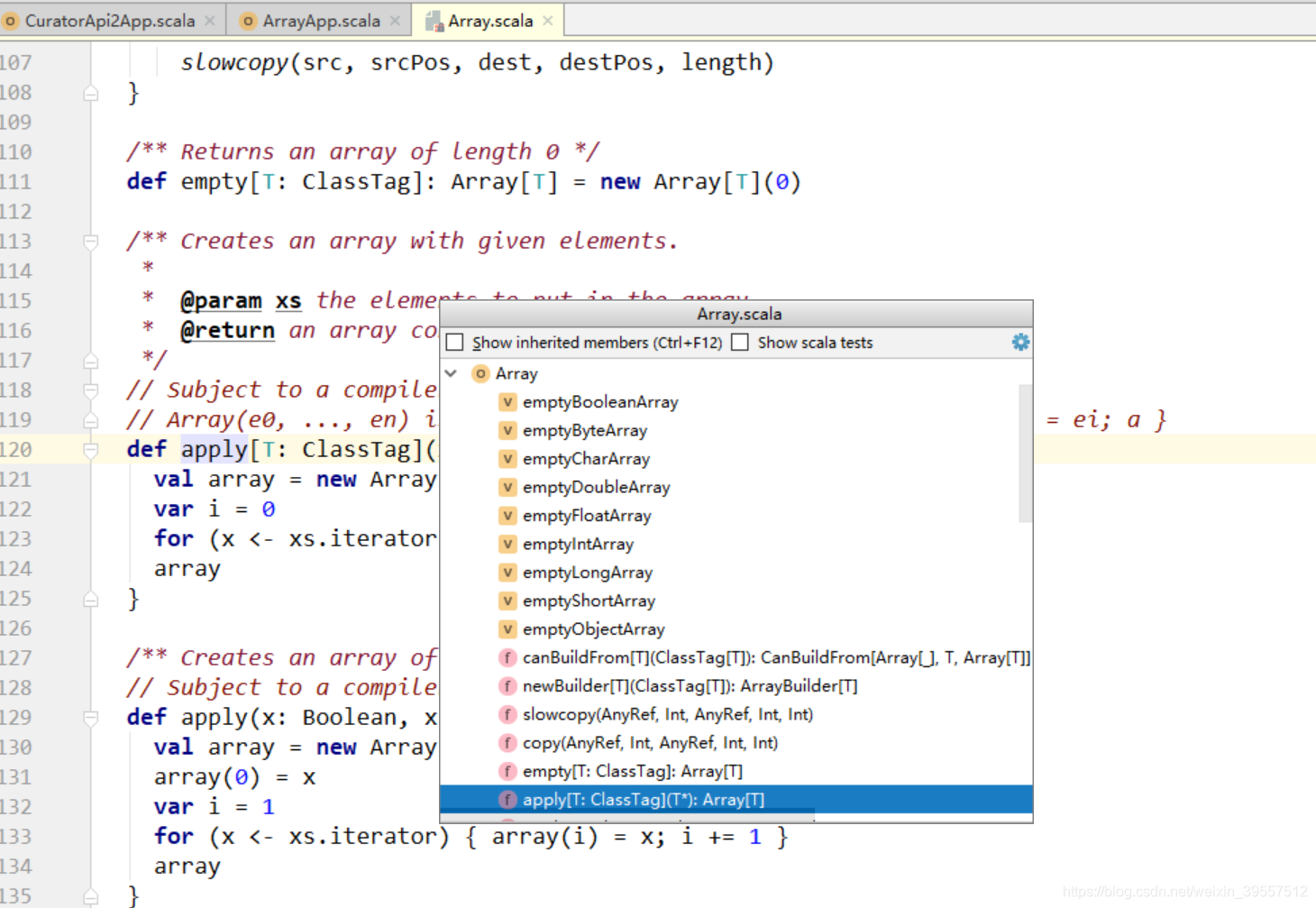
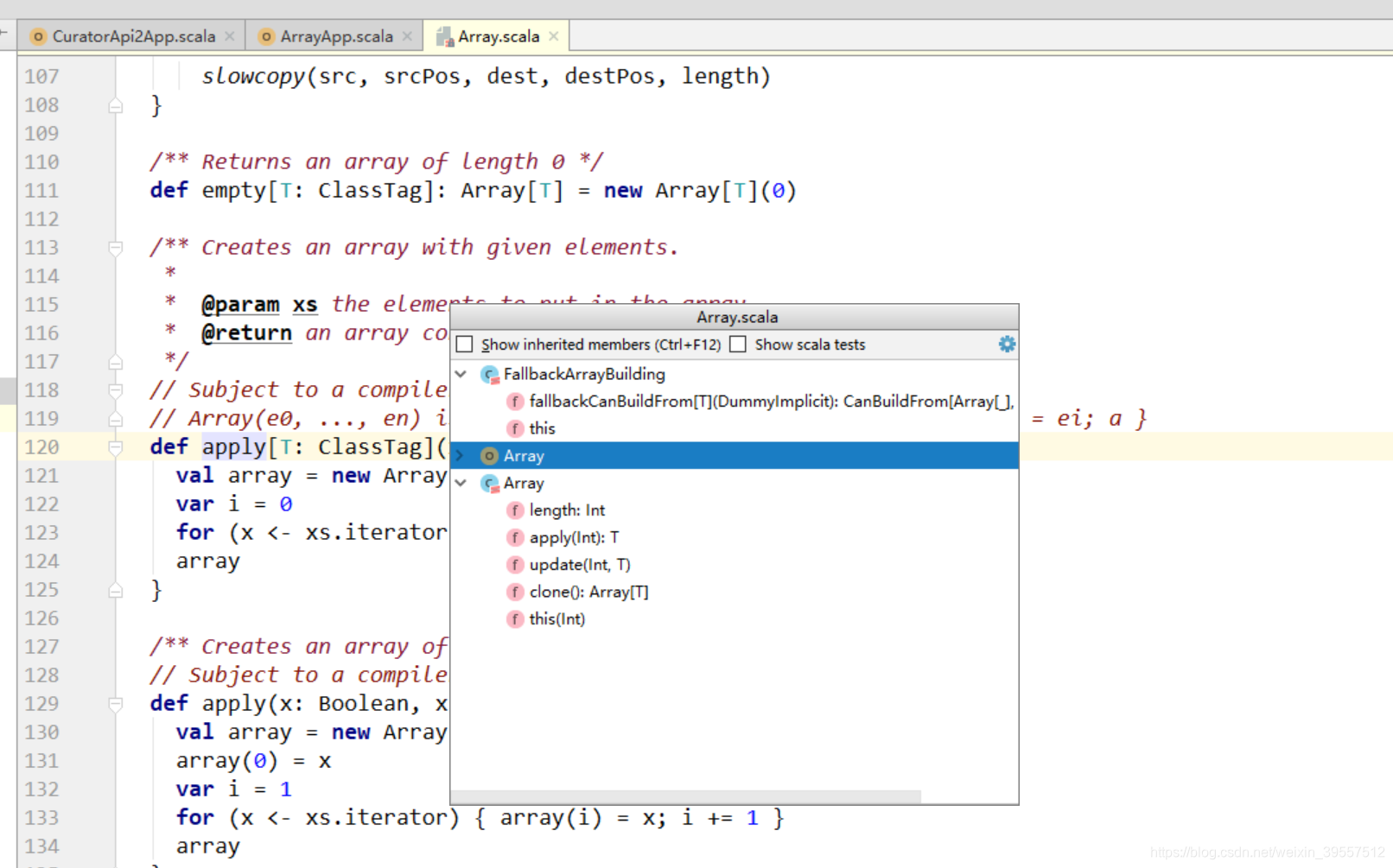
1 | 底层调用的是 object的 apply方法: |
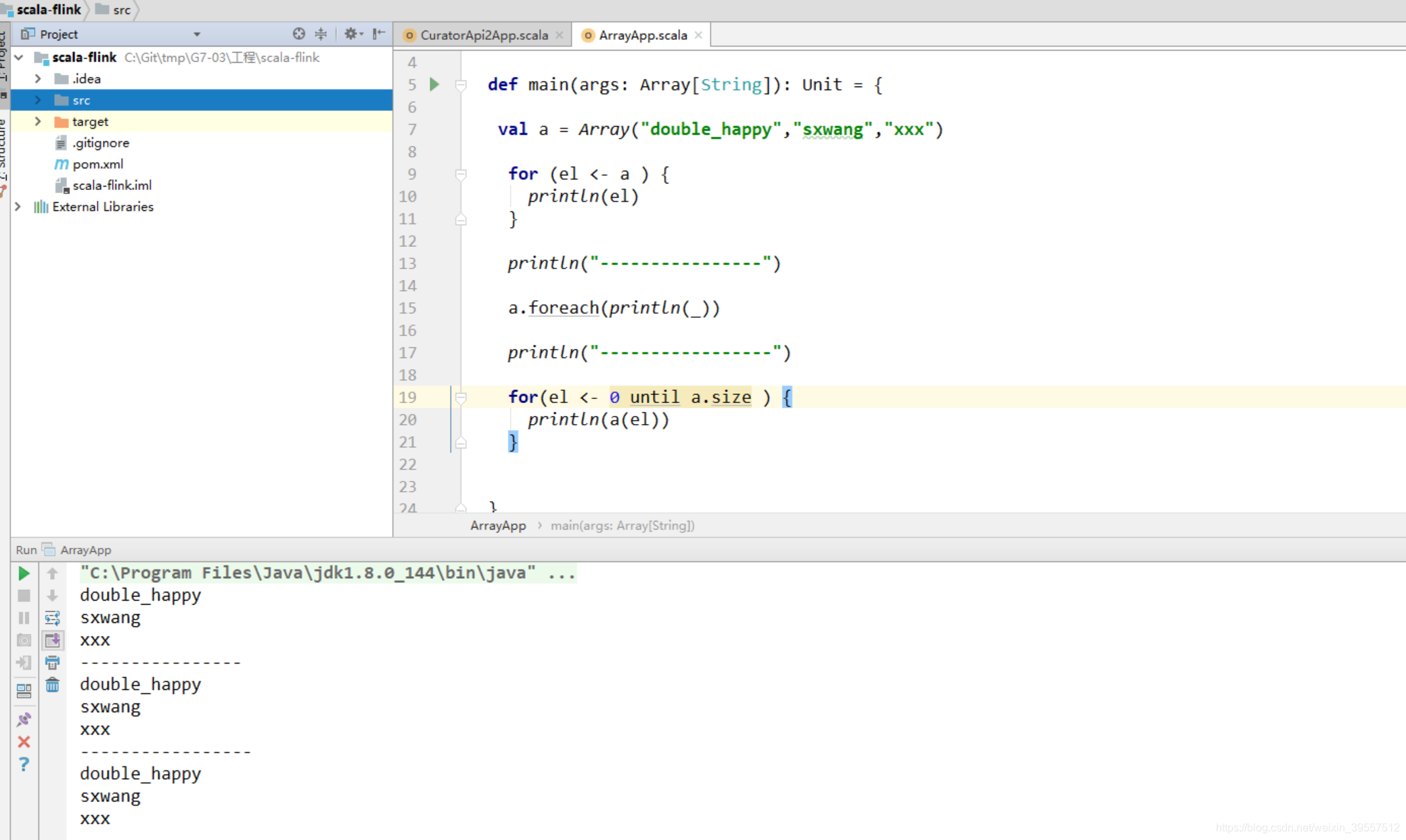
1 | 遍历:这里列出三种 |
1 | 其他知识点补充: |

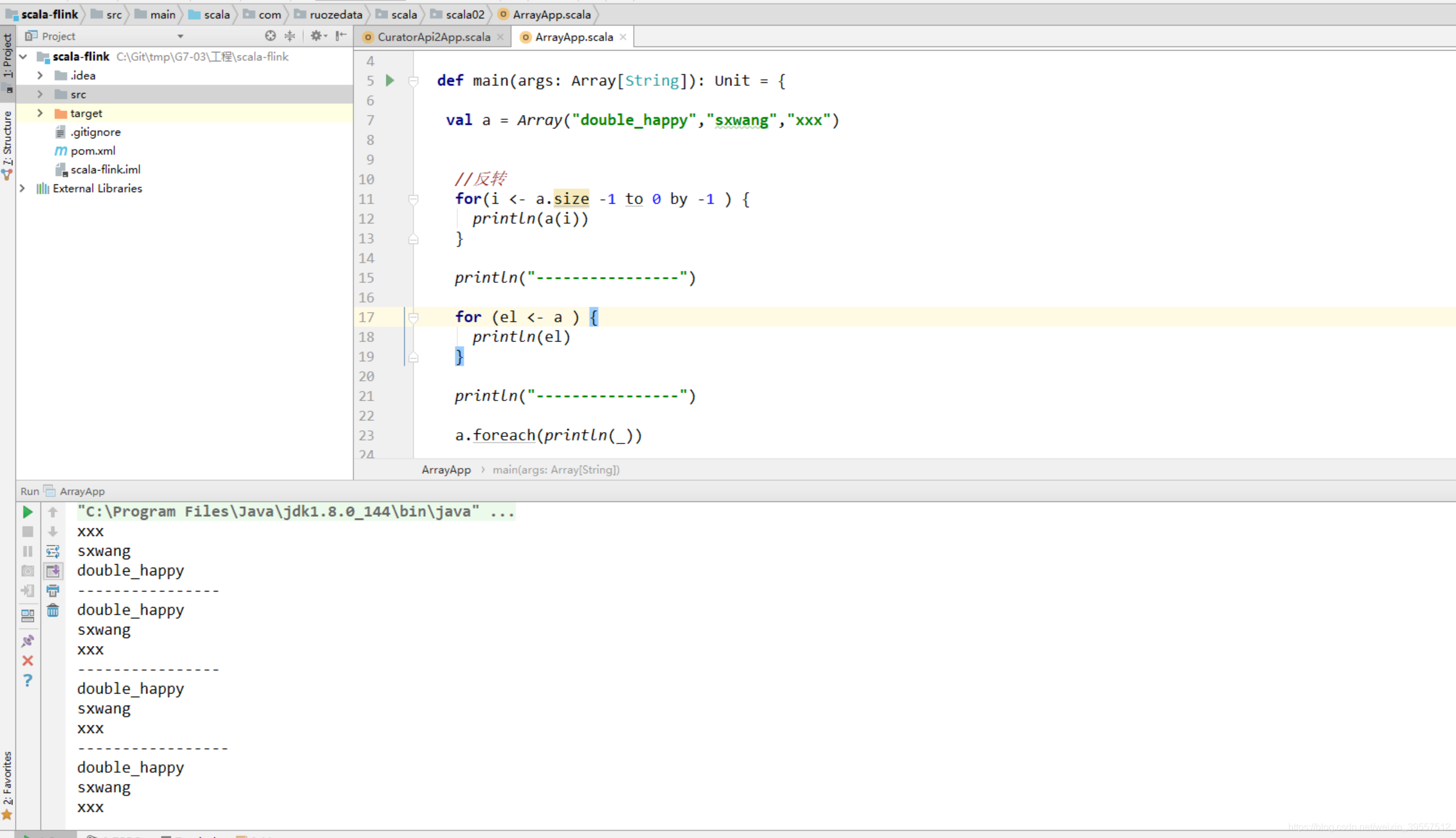
1 | 不适用reverse: |
1 | 两个Array 相加: |


1 | mkString使用:查看数组内容 |

1 | def mkString(start: String, sep: String, end: String): String = |
能不能用toString呢?
不能哈 toString 默认是 打印 包名类名hashcode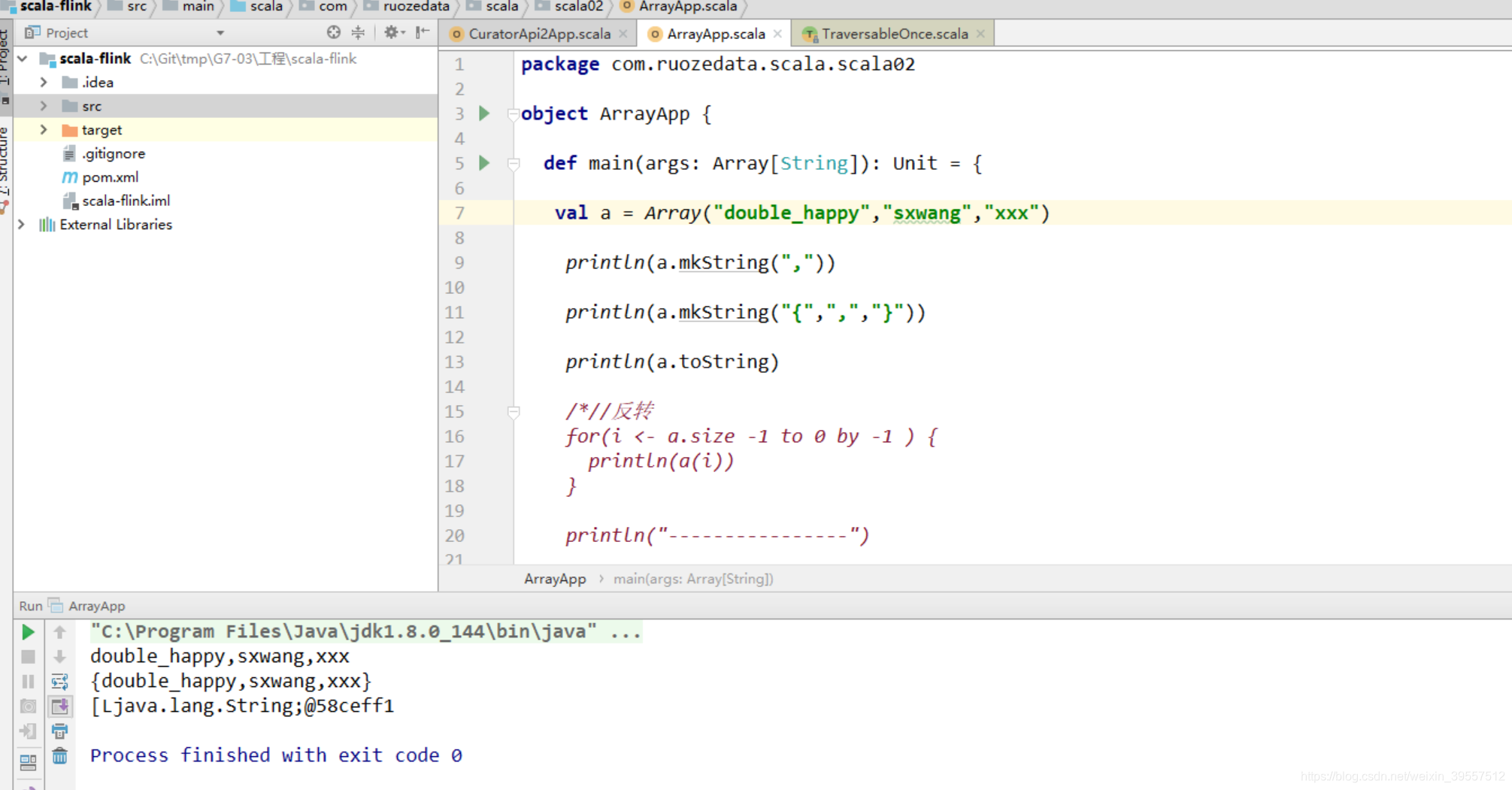
变长数组:ArrayBuffer
1 | ++ 代表加的是类似的数据结构的 |
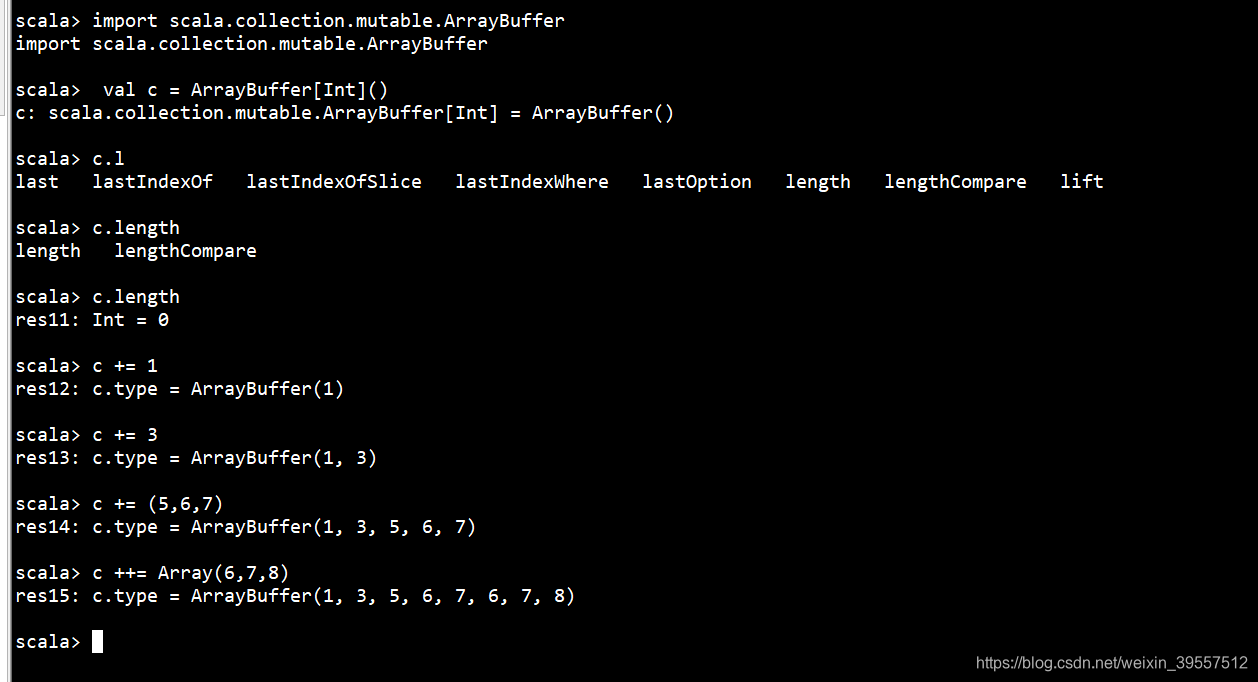
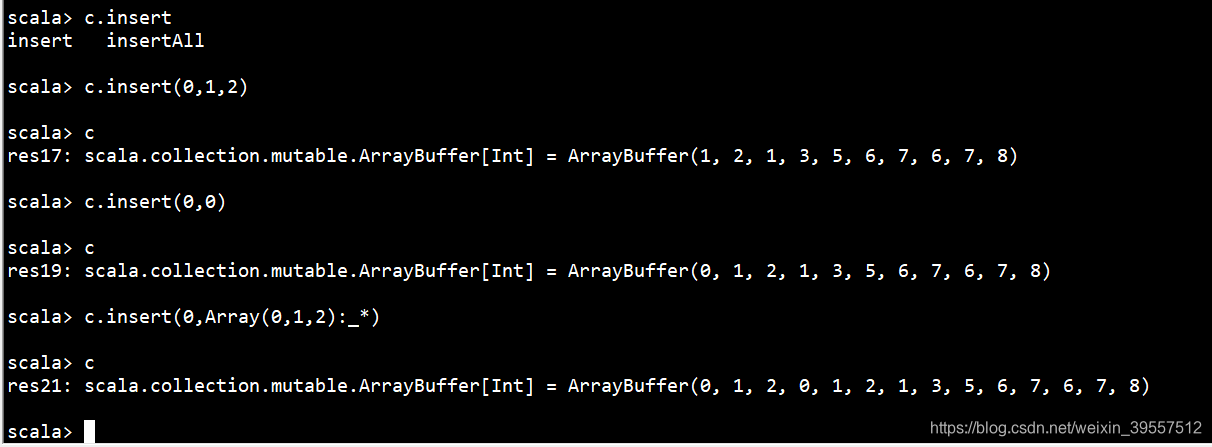
1 | /** Inserts new elements at a given index into this buffer. |
1 | /** Removes the element on a given index position. It takes time linear in |
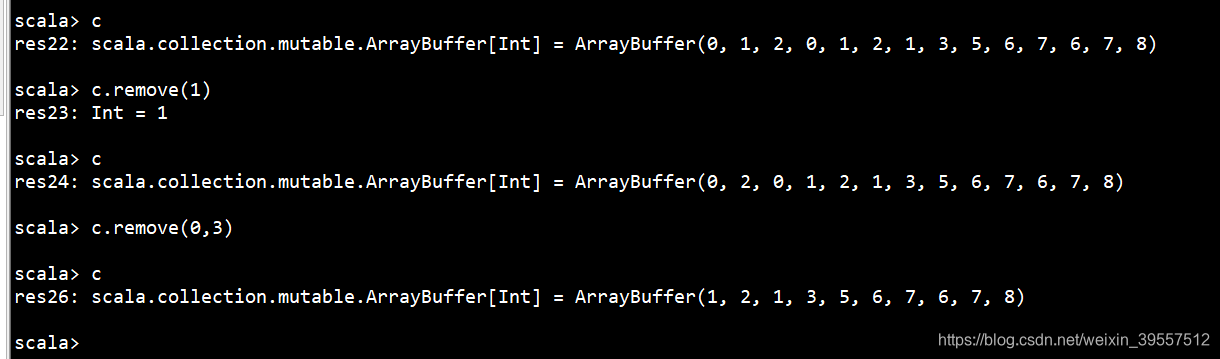
1 |
|
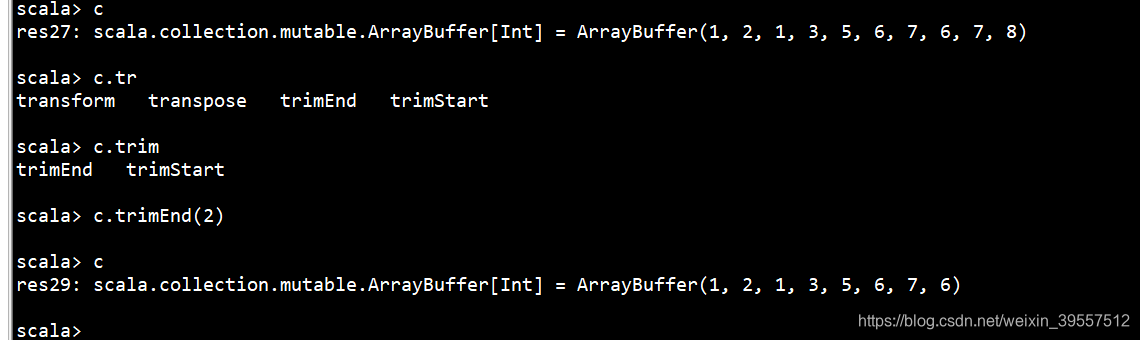
(10)高阶函数
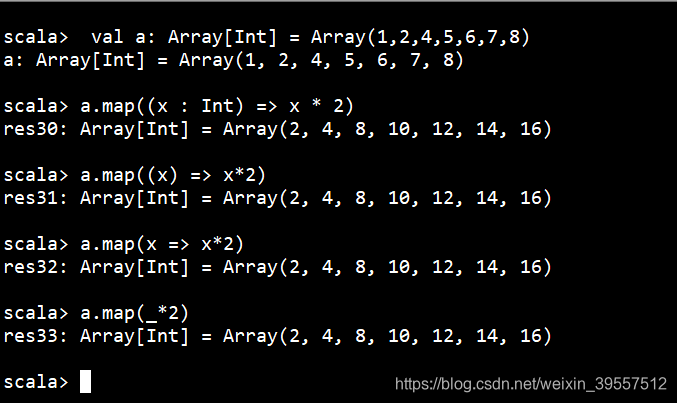
1 | map:映射 一一映射 |

1 | filter:过滤掉不需要的东西 (true留下 false不留) |

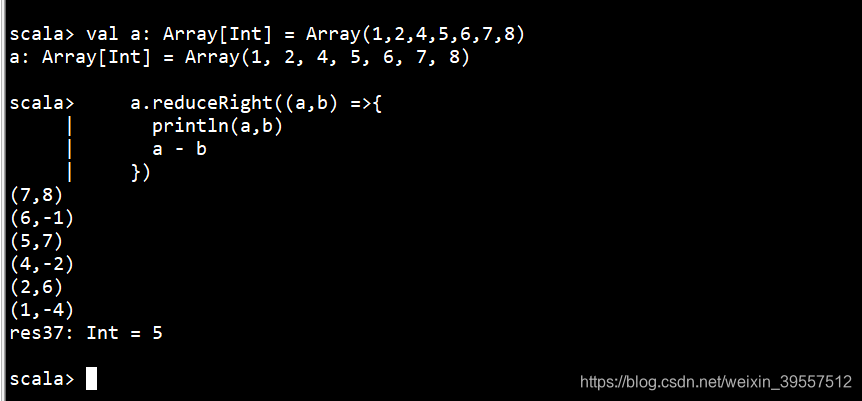
1 | reduce:入参是两个 |
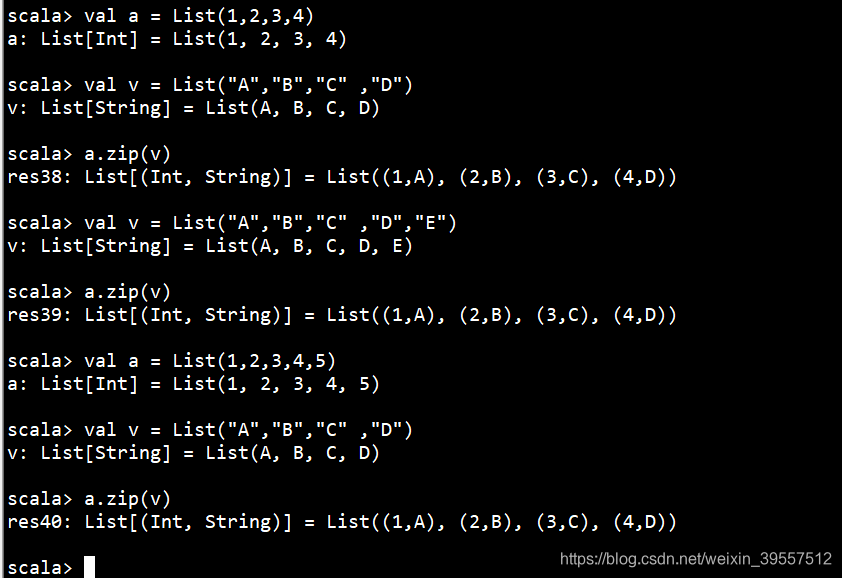
1 | zip : 相同位置的放在一块 只有同等位置有的才有 没有就是没有 |
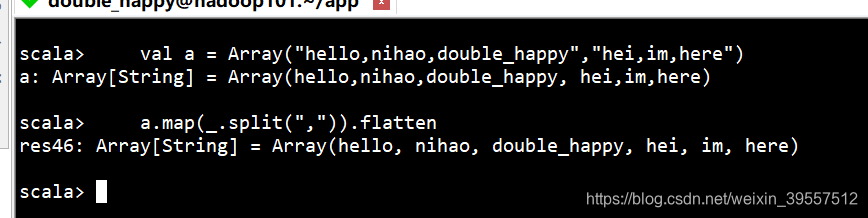
1 | flatten:把所有元素抽出来 放到一个Array里面 |
1 | flatmap: 注意 flatten 和 flatmap的区别 |
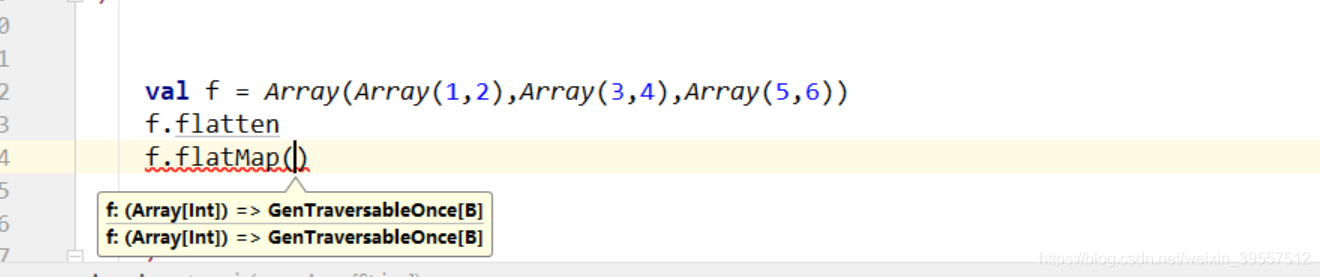
flatmap的入参 是 Array[Int] 哟
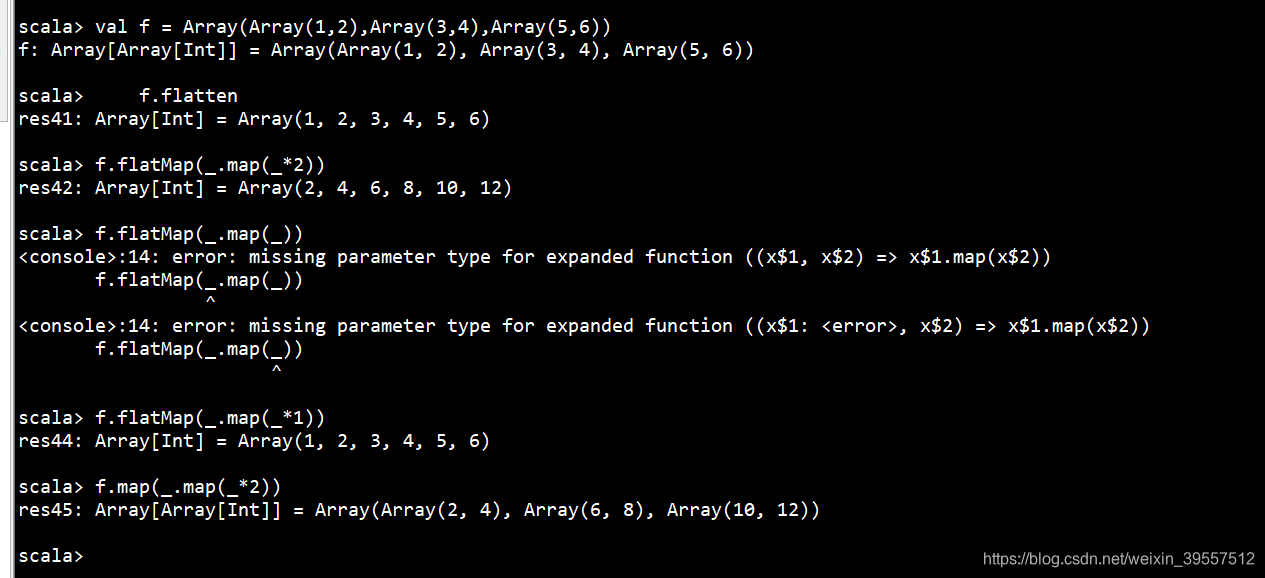
map和flatmap的区别
map并没有做压扁操作
1 | find : 最多查找出满足条件的第一个元素 |

1 | mapValues: 也是一一映射 map是作用在 value上面的 必须是 kv类型的 |
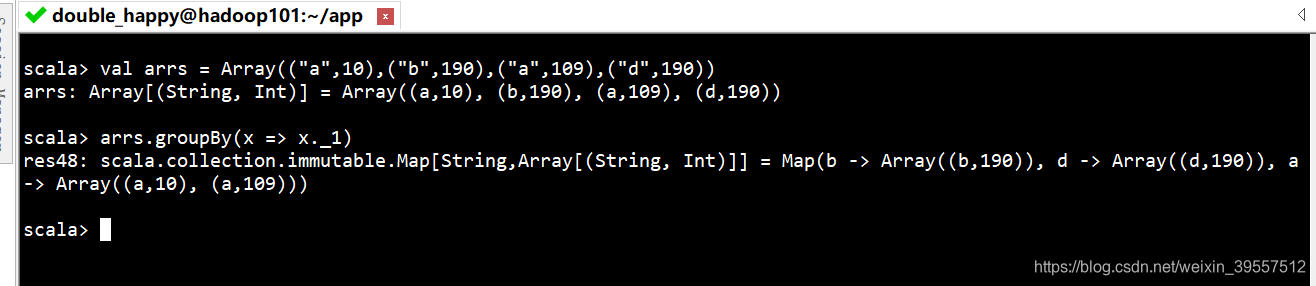
1 | groupBy : 自定义分组 |
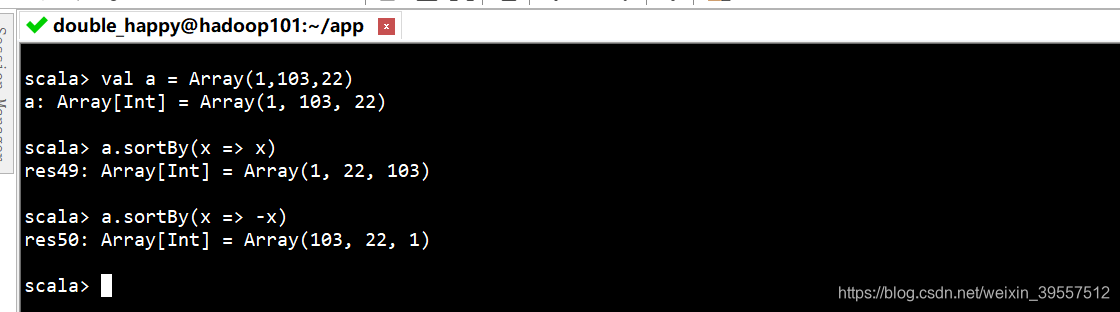
1 | sortBy : 自定义排序 最好利用 List使用 |
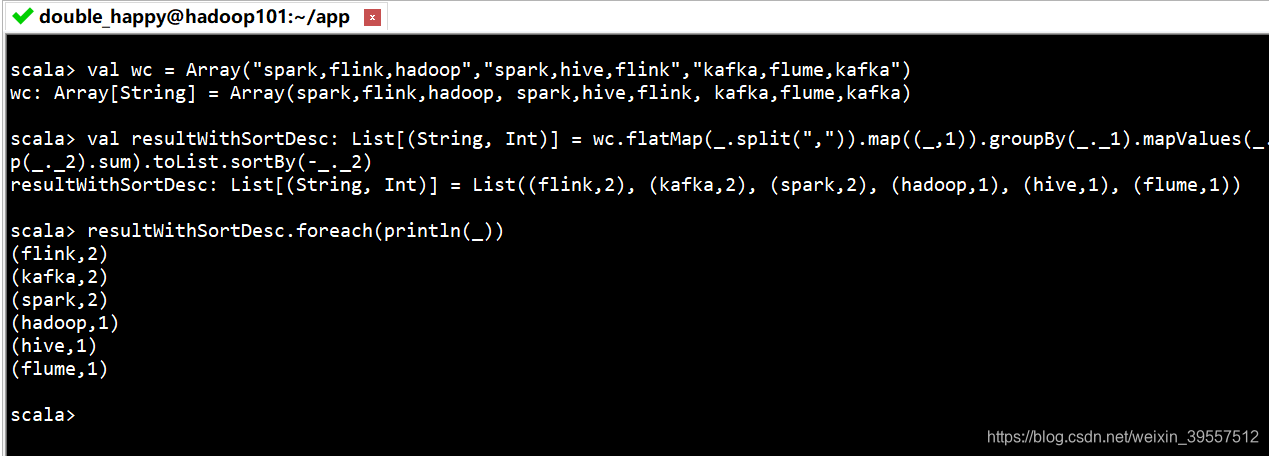
(11)scala编写wordcount 先压扁再做操作
1 | 代码:好好理解 这块最好结合 mapreduce的wc : map输出之后 相同的key 把不同的value值放到一个集合里 这个思想是重点 |
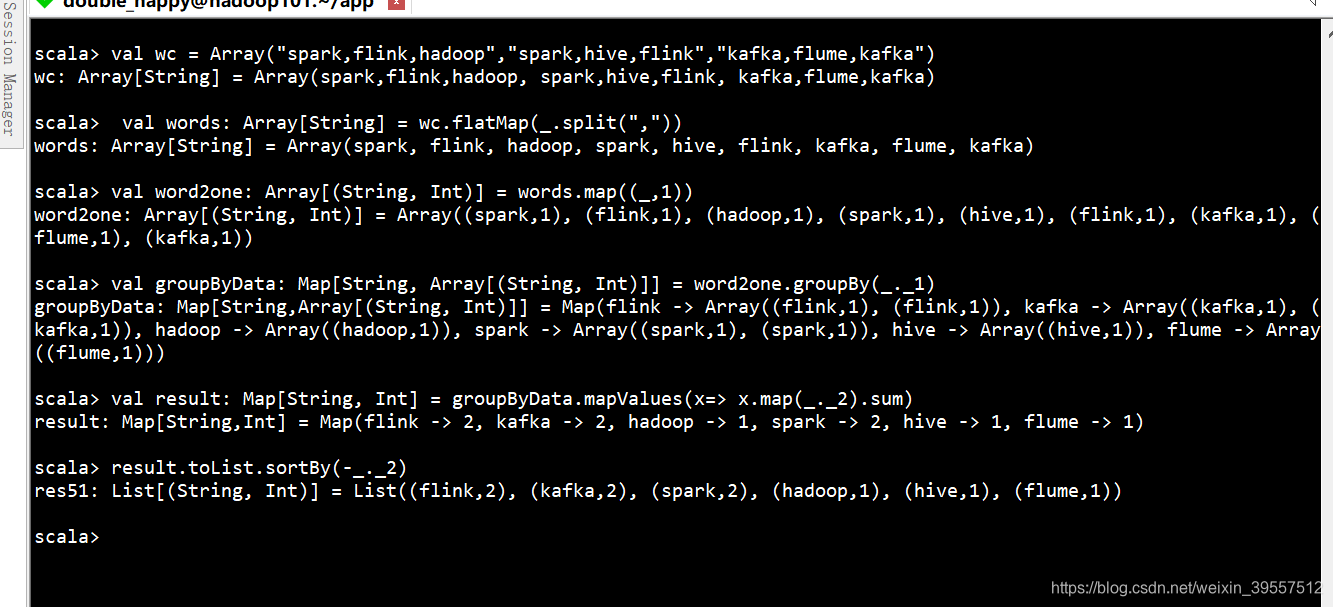
1 | 正常应该这样写: |