1.Hadoop编译
总结一下在开发机上编译源码的小问题:
1.maven的setting.xml的配置
1 | <mirror> |
2.编译源码里的pom.xml文件里的cloudera-repos的url去掉https的s
1 | <repositories> |
注意:idea开发的时候s是不去掉也ok(好像去不去掉都ok 都可以打开url提供的页面)
3.由于网络问题有些 .pom、.jar下载不完整,决解办法:去maven本地仓库先删掉对应文件,然后wget 文件的url。
1 | 扩展小知识: |
2.大数据的理解
1.存储 (HDFS、Hive、HBase、Kudu)
2.计算 (Hive、sql、Spark、Flink)
3.资源作业调度 (Yarn)
这三个方面,个人认为 存储是最重要的,存储涉及到:同步设计、小文件、监控等。如果存储做的不好,计算写的天花乱坠也是没有用的。
3.HDFS HA & 伪分布式
对比较伪分布式再来引出HDFS的HA:
1 | 伪分布式:进程 |
企业里用的绝对是HDFS的HA,伪分布式的snn无法做到实时checkpoint,snn只是一个冷备。
那么企业是是需要是一个热备,做实时备份的:
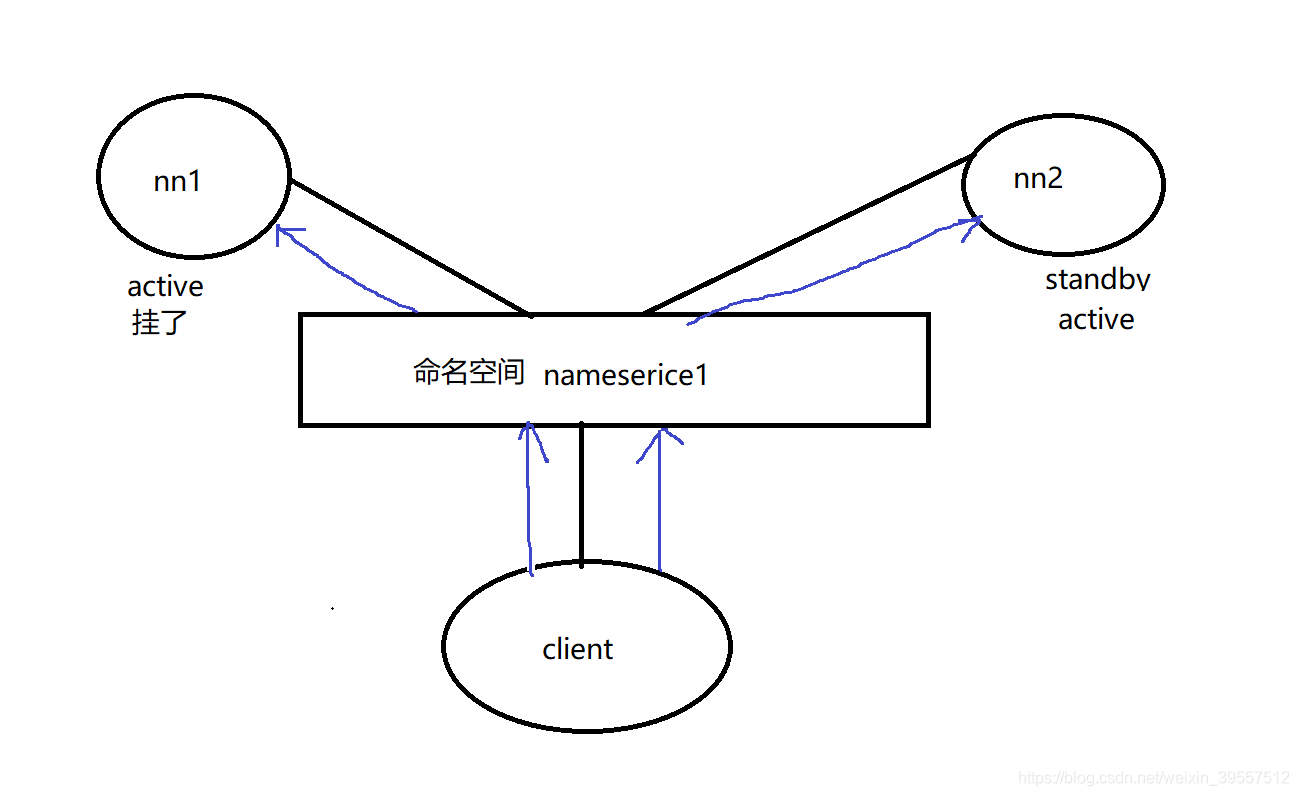
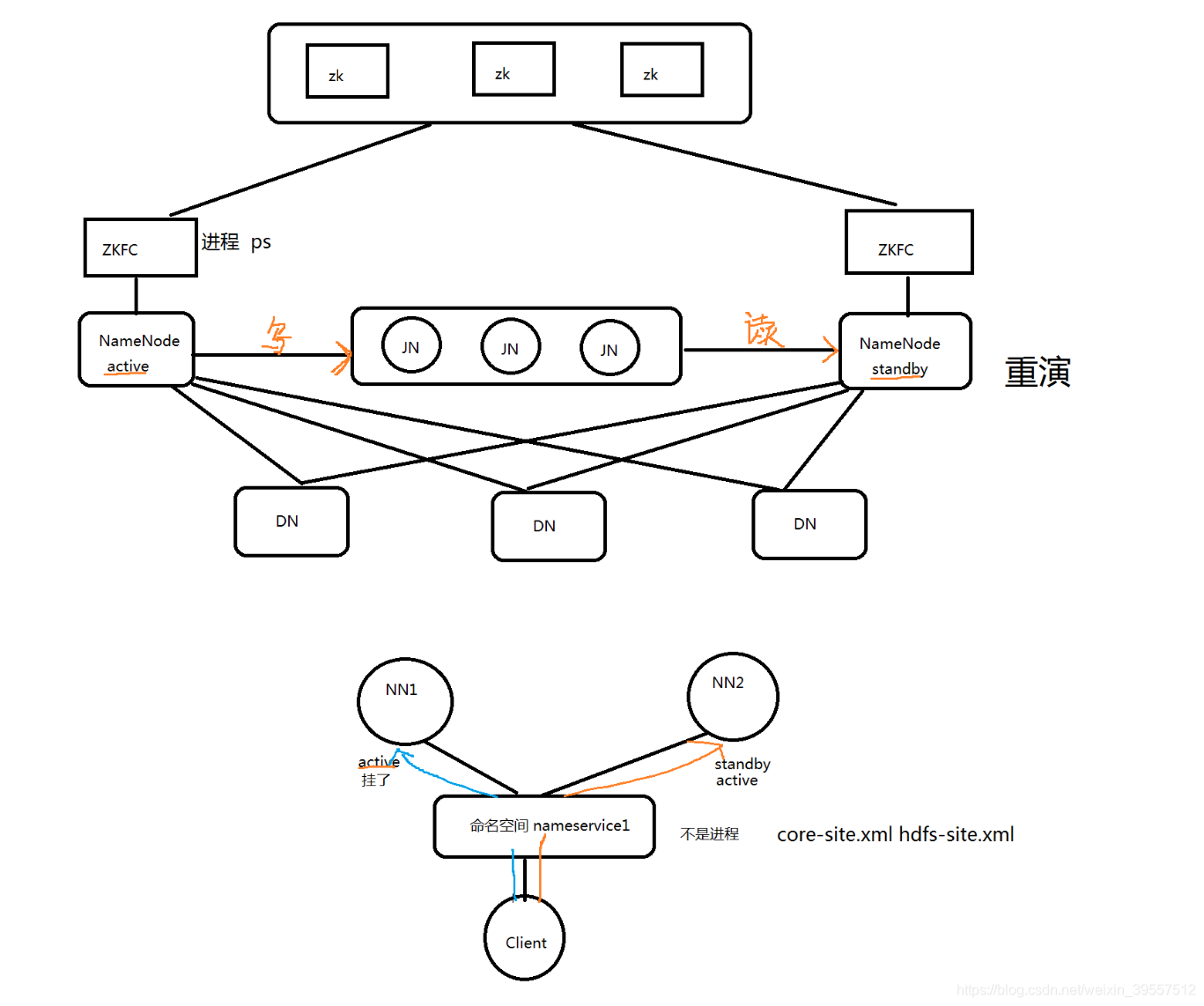
1 | nn节点挂掉,就不能提供对外服务,所以需要两个nn (active、standby),任何时候只有1台 active的nn对外 |
扩展小知识:
1 | `客户端是通过什么同时对接两个nn呢?===》命名空间 (在配置文件里的) |
4.HDFS HA 机器进程(emmm以三台开发机为例)
首先去hadoop.apache.org官网查看,配置HA有两种QJM、NFS(类似百度网盘,百度一下nfs概念就明白了),国内大部分是用QJM做HA的。下面的HA也是使用QJM做讲解。
1.HDFS HA 三台机器的进程
1 | doublehappy001: ZK NN zkfc(zookeeperFailoverControl) jn(JournalNode) DN |
jn:日志节点 记录请求的记录
1 | 企业里: |
经验:
1 | jn: >=3台 2n+1 |
2.Yarn HA 三台机器的进程
1 | doublehappy001: ZK NN zkfc(zookeeperFailoverControl) jn(JournalNode) DN RM NM |
Yarn HA它没有用jn ,这是HDFS HA & Yarn HA 的所有进程
扩展小知识:
1 | 主从架构 master --》slave |
5.HDFS HA架构图
HA使用active NN, standby NN两个节点解决单点问题。两个NN节点通过JN集群,共享状态,通过ZKFC选举active,监控状态,自动备援DN会同时向两个NN节点发送心跳。
扩展小知识:
1 | 双写 |
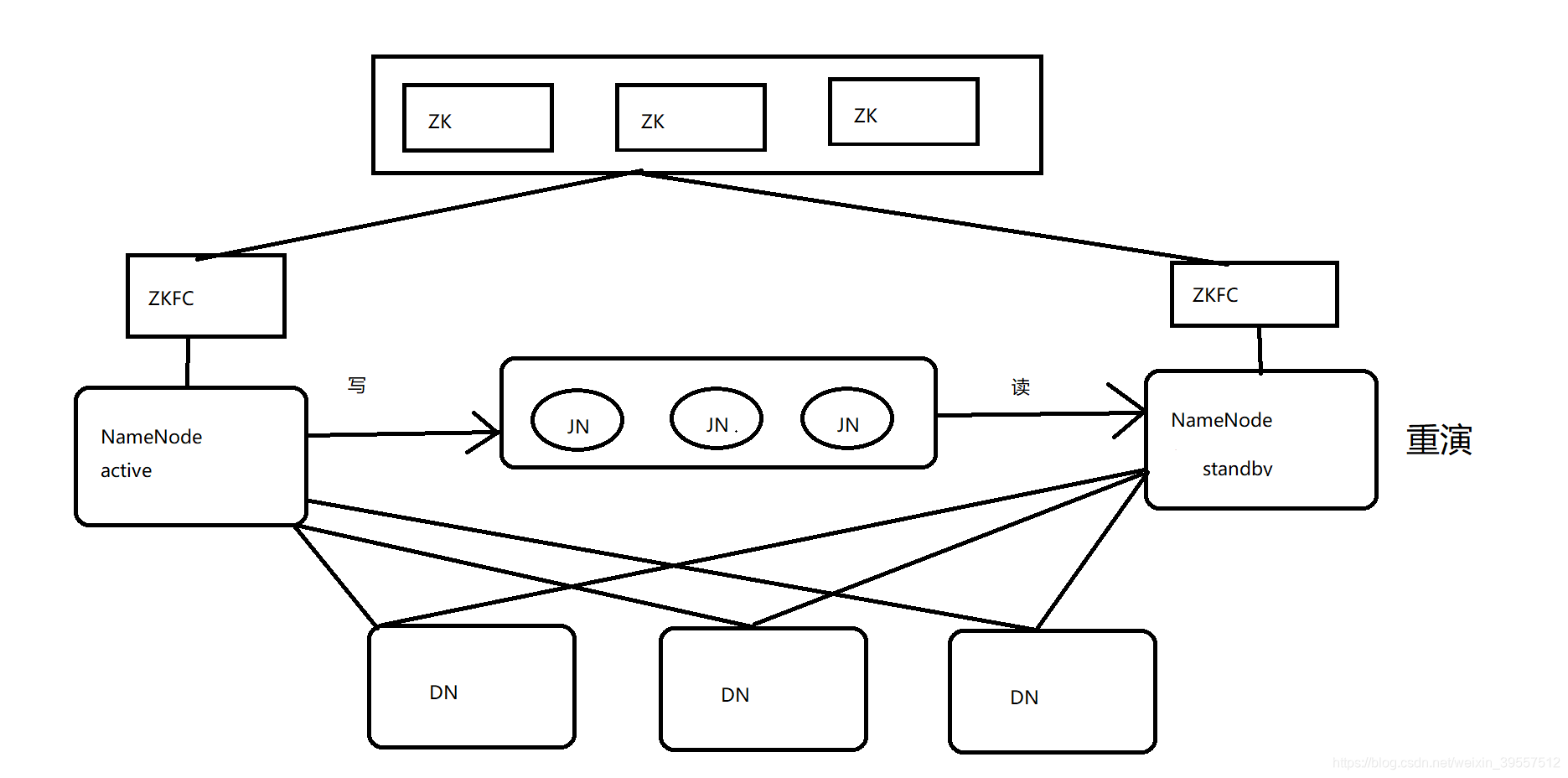
active nn:
1 | 接收client的rpc请求并处理,同时自己editlog写一份,也向JN的共享存储上的editlog写一份。 |
standby nn:
1 | 同样会接受到从JN的editlog上读取并执行这些log操作,使自己的NN的元数据和activenn的元数据是同步的, |
jn:
1 | 用于active nn,standby nn的同步数据,本身由一组的JN节点组成的集群,奇数,3台(CDH),是支持Paxos协议。 |
ZKFC:
1 | 监控NN的健康状态 |
6.Yarn HA架构图
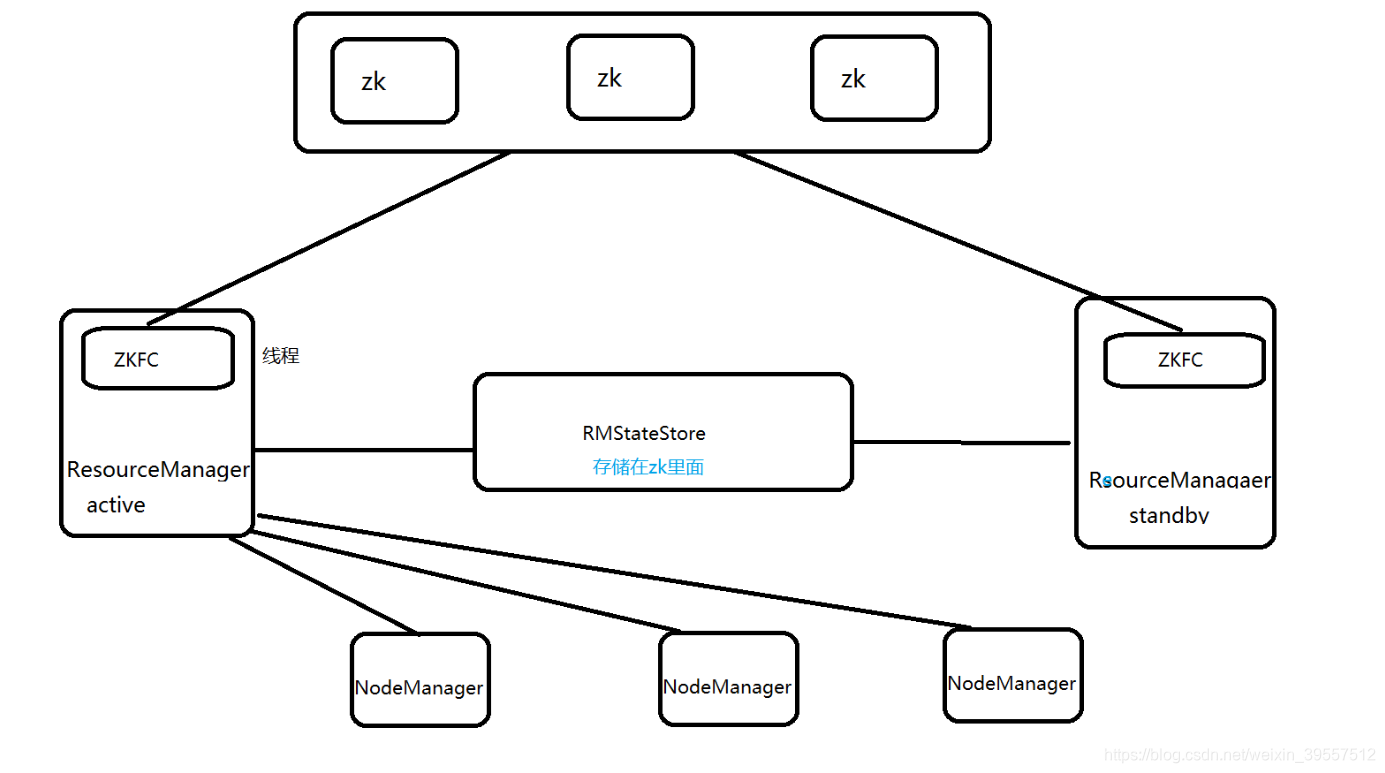
RM:
1 | a.启动时会通过向ZK的/hadoop-ha目录写一个lock文件,写成功则为active,否则standby。 |
NM:
1 | 节点上的资源的管理,启动container 容器 运行task的计算,上报资源,container情况汇报给RM和任务的处理情况汇报给 |
ApplicationMaster(AM)driver :
1 | nm机器上的container |
RMstatestore:
1 | a.RM的作业信息存储在ZK的/rmstore下,active RM向这个目录写app信息 |
ZKFC:
1 | 自动故障转移 只作为RM进程的一个线程 而非独立的守护进程来启动 |
7.HDFS &Yarn HA架构区别
ZKFC:
1 | Yarn:只作为RM进程的一个线程,而非独立的守护进程来启动 |
从节点心跳接收:
1 | Yarn: 只有active的rm接受nm的心跳 standby不接受nm的心跳。 |
active->standby切换:
1 | Yarn: |
总结:
1 | Yarn是active挂了之后去RMstatestore读取作业信息 |
体现出HDFS比Yarn的HA重要性,也体现出 存储比计算重要。